
해시 알고리즘이란?
해시 함수 알고리즘이란, 데이터를 저장하거나 찾는 방법을 제시하는 알고리즘이다(이하 해시 알고리즘). 해시 알고리즘은 ‘키들의 집합인 key’ , ‘키를 index값으로 변환시켜주는 hash function’ , ‘hash function을 통해 도출된 값을 index로 취하는 배열(버킷)’ 로 구성되어있다.
해시 알고리즘의 작동원리는 다음과 같다. 이에 대한 예시는 아래 그림에 나타나 있다.
① 특정 key를 hash function의 입력값으로 넣는다.
② hash function은 이것을 특정한 값(보통 정수)로 반환한다.
③ ②번에서 반환된 값을 index로 가지는 value를 bucket에서 찾는다.
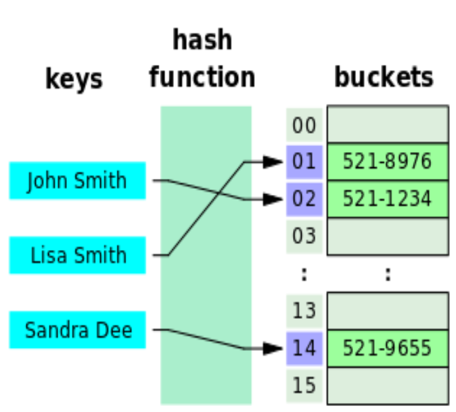
출처: 위키백과
시간복잡도 비교
해시 알고리즘을 사용했을 때, 데이터 검색, 저장, 삭제 등의 연산을 수행하는 시간 복잡도가 극적으로 향상된다. 일반적인 방법으로 n개의 데이터 중 특정 데이터 한 개를 찾는다고 가정했을 때, 발생하는 시간 복잡도는 O(n) 이다. 왜냐하면, n개의 데이터를 하나씩 찾아봐야 하기 때문이다.
하지만 해시 함수 알고리즘을 사용한다면, 특정 key를 hash function에 입력하여 도출된 값을 index로 사용하여 배열에 접근하면 된다. 따라서, “hash function 계산 시 소요되는 시간 + 배열(버킷)의 요소 찾는 시간” 이 해시 알고리즘의 시간 복잡도이다. hash function은 보통 O(1)이 걸리도록 구현하고, 배열의 요소를 찾는 시간은 O(1)이므로, 해시 알고리즘의 시간 복잡도는 “O(1)+O(1)”이다. 즉, 평균 시간 복잡도는 O(1)이 된다.
해시 알고리즘에서 주의해야 하는 부분이 있다. 바로 충돌문제 가 그것인데, 충돌문제는 서로 다른 키를 hash function이 같은 값으로 반환해줄 때 발생한다. 충돌문제를 해결하는 대표적인 방법은 Linked List를 활용하는 것이다. 요소를 Linked List 형태로 만들어, 서로 다른 키를 통해 같은 index로 접근 시, 각각 연결된 형태로 저장하는 방법이다. 아래 그림에서 k3, k4, k8가 서로 같은 index를 가르키고 있다. 따라서, 연결리스트 방식으로 해결하는 모습이 나타난다.
아래 그림은 LinkedList를 활용한 충돌 해결을 시각화한 것이다.
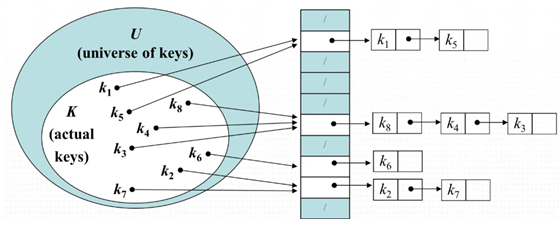
출처: T아카데미-유튜브채널
하지만 이런 방식으로 문제를 해결해도, 결국 시간 복잡도는 증가하게 된다. 왜냐하면, LinkedList의 첫 번째 요소부터 찾아가야 하는 추가적인 작업이 필요해지기 때문이다. 최악의 경우, hash function이 n개의 key를 모두 같은 값으로 반환한다고 가정해본다면, LinkedList의 길이는 총 n이 된다. 따라서, 특정 값을 찾을 때 발생하는 시간 복잡도는 O(n)이 된다. 이는, 기본적인 탐색 방법(하나씩 찾는 방법)의 시간 복잡도와 일치한다. 따라서, hash function을 어떻게 구현하느냐가 주요 포인트이다.