
프로세서의 조직
개요
프로세서에게 요구되는 업무
- 명령어 인출
- 명령어 해석
- 데이터 인출
- 데이터 처리 (명령어 실행)
- 데이터 쓰기 (결과 저장)
내부기억장치
- 프로세서는 업무를 수행하기 위해 레지스터가 필요하다.
- 레지스터를 내부기억장치라고 한다.
CPU 내부 조직
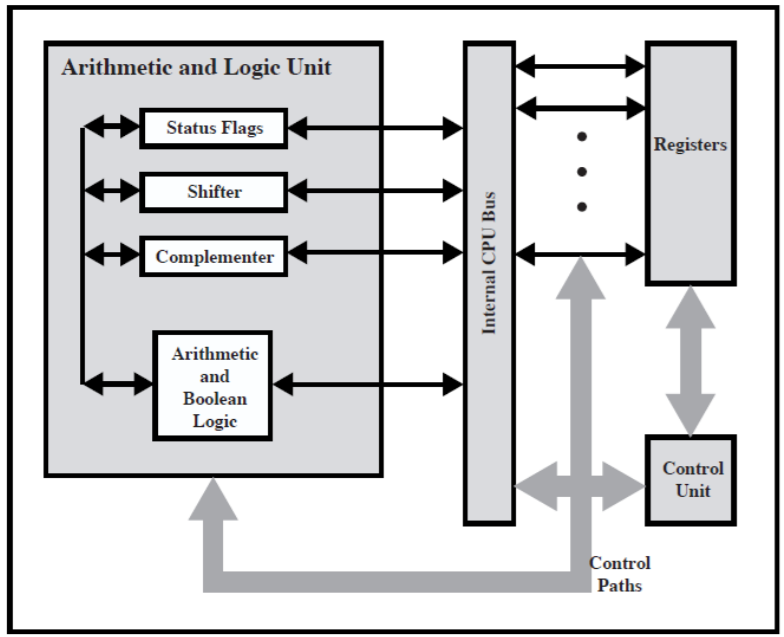
레지스터 조직
레지스터란?
- 레지스터는 프로세서 내부의 작업 공간이다.
- 레지스터의 개수와 기능은 프로세서마다 다르다.
- 레지스터는 기억장치 계층의 최상위 레벨이다.
레지스터의 역할
- ‘사용자에게 보이는 레지스터’의 역할
- 기계어·어셈블러 프로그래머가 사용하는 레지스터를 최적화 해준다. ⇒ 이것을 통해 주기억장치 사용을 최소화하도록 한다.
- ‘제어 및 상태 레지스터’의 역할
- 프로세서의 동작을 제어하는 제어 유니트와 프로그램의 실행을 제어하는 운영체제프로그램에 의해 사용된다.
각 레지스터에 대해 하나씩 자세히 알아보자.
사용자에게 보이는 레지스터
사용자에게 보여지는 레지스터의 종류는 아래와 같다.
- 일반 목적용
- 프로그래머에 의해 여러가지 용도로 배정된다.
- 데이터
- 데이터 저장을 위해서 사용된다.
- 주소
- 일반목적용 or 특정 주소지정 방식을 위해 사용된다.
- 종류
- 세그먼트 포인터
- OS에서 메모리 관리 시 사용된다.
- 인덱스 레지스터
- 변위 주소지정방법에서 사용된다.
- 스택 포인터
- 스택의 최상위를 가리킨다.
- 세그먼트 포인터
- 조건 코드 (flags)
- 연산 결과에 따라, 프로세서에 의해 세트되는 비트들을 관리한다.
일반 목적용 레지스터의 설계 이슈
- 일반 목적용 레지스터는 명령어 세트 설계에 영향을 미친다.
- 일반 목적용 레지스터 vs 특수 목적용 레지스터
- 일반 목적용 레지스터
- 융통성 및 프로그래머 옵션 증가
- 명령어의 크기와 복잡도 증가
- 특수 목적용 레지스터
- 명령어 크기 감소
- 프로그래밍의 유연성 감소
- 일반 목적용 레지스터
- 일반 목적용 레지스터의 개수
- 일반적으로 8~32개를 사용한다.
- 레지스터의 개수 증가시
- 더 많은 수의 오퍼랜드 지정자 비트들이 요구된다.
- 즉 오퍼랜드를 위한 비트 수가 많이 요구된다.
- 레지스터의 개수 감소시
- 기억장치 참조 횟수가 증가한다.
- 레지스터의 길이
- 주소를 저장하는 레지스터 (MAR)
- 가장 긴 주소를 저장할 수 있을 만큼 커야 한다.
- 데이터 레지스터 (MBR)
- 대부분의 데이터 유형을 저장할 수 있을 만큼 커야 한다.
- 주소를 저장하는 레지스터 (MAR)
제어 및 상태 레지스터
제어 및 상태 레지스터의 종류는 아래와 같다.
- 프로그램 카운터 (PC)
- 인출할 명령어의 주소를 가지고 있다.
- 분기/skip 명령어도 PC의 내용을 갱신시킨다.
- 명령어 레지스터 (IR)
- 가장 최근에 인출한 명령어를 가지고 있다.
- 연산코드와 오퍼랜드 지정자들이 분석된다.
- 기억장치 주소 레지스터 (MAR)
- 기억장치 내 어떤 위치의 주소를 가지고 있다.
- 주소 버스에 연결된다.
- 기억장치 버퍼 레지스터 (MBR)
- ‘기억장치에 쓰여질 데이터 단어’ or ‘가장 최근에 읽은 단어’를 가지고 있다.
- 데이터 버스에 연결된다.
프로그램 상태 단어 (PSW: Program Status Word)
- PSW는 상태 정보를 저장하는 레지스터(레지스터 세트)이다.
- PSW의 공통 필드·플래그
- Sign
- 직전에 수행된 산술 연산 결과의 부호 비트
- Zero
- 결과가 0일 때 세트
- Carry
- 연산 결과에 따른 올림수 또는 빌림수를 표시
- Equal
- 논리적 비교의 결과가 같을 때
- Overflow
- 산술적 오버플로우를 표시
- Interrupt enable/disable
- 인터럽트 가능여부
- Supervisor
- 프로세서가 수퍼바이저 모드(커널모드)와 사용자 모드 중의 어느 모드에서 실행 중인지 가리킴
- Sign
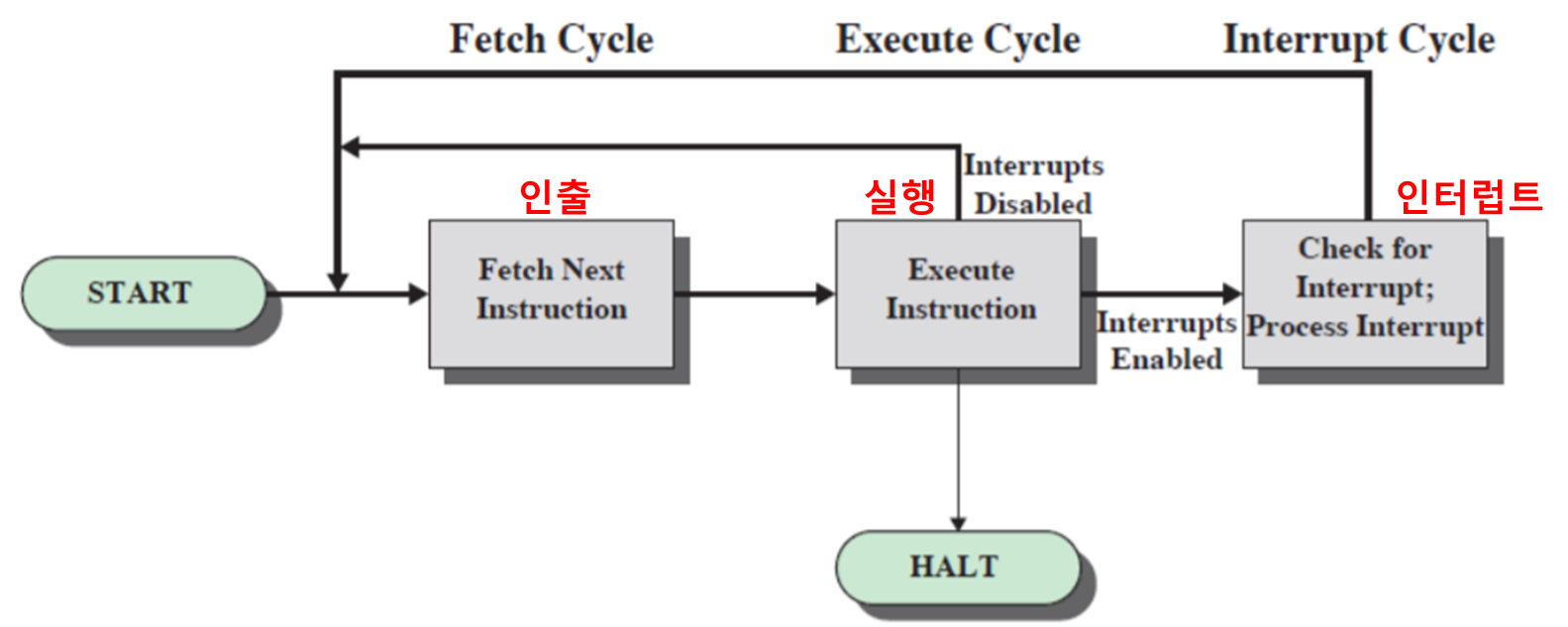
명령어 사이클
명령어 사이클 구조
명령어 사이클은 크게 아래와 같이 구분할 수 있다.
- 인출
- 실행
- 인터럽트
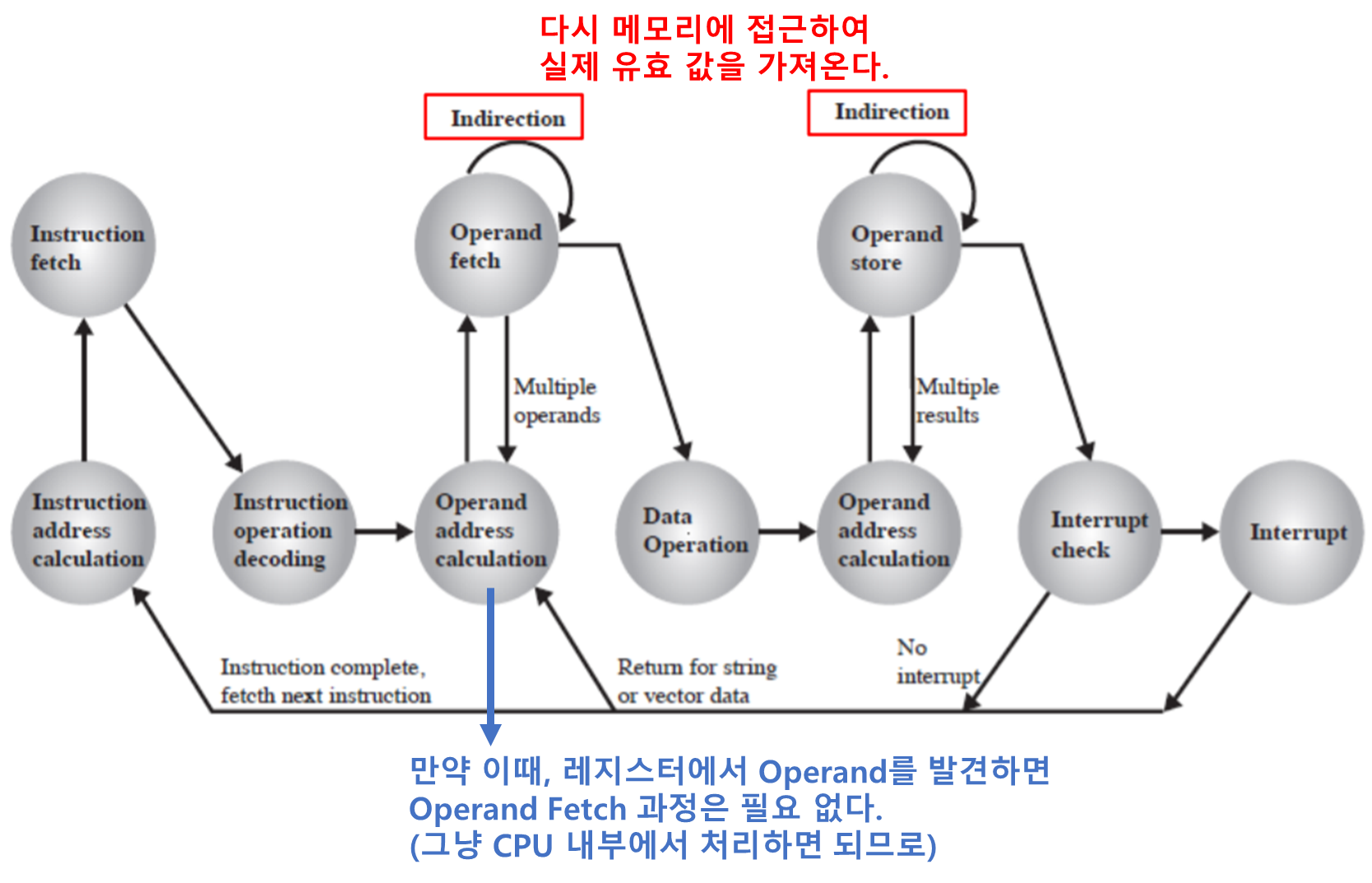
간접 사이클
- 간접 사이클이란?
- 간접 주소지정 방식에서 사용되는 명령어 사이클
- 간접 주소지정 방식 사용시
- 기억장치 액세스가 한번 더 이루어진다.
-
간접 주소의 인출도 하나 이상의 명령어 단계로 간주한다.
-
명령어 간접 사이클 상태도
프로세서 기능
명령어 파이프라이닝
명령어 파이프라이닝이란?
- 프로세서 성능 향상 기법 중 하나이다.
2단계 명령어 파이프라인
- 2단계?
- 명령어 사이클이 ‘명령어 인출’와 ‘명령어 실행’으로만 구분되는 경우
- 2단계 명령어 파이프라인의 동작
- 명령어가 실행되는 과정에서 주기억장치를 액세스하지 않는 시간에 다음 명령어를 동시에 인출한다.
파이프라이닝의 속도 향상의 한계
- 2단계 명령어 파이프라인의 경우, 일반적으로 ‘명령어 실행시간’이 ‘명령어 인출시간’보다 더 길다.
- 오퍼랜드 인출·연산·저장 등을 명령어 실행시 수행한다.
-
따라서 발생하는 문제
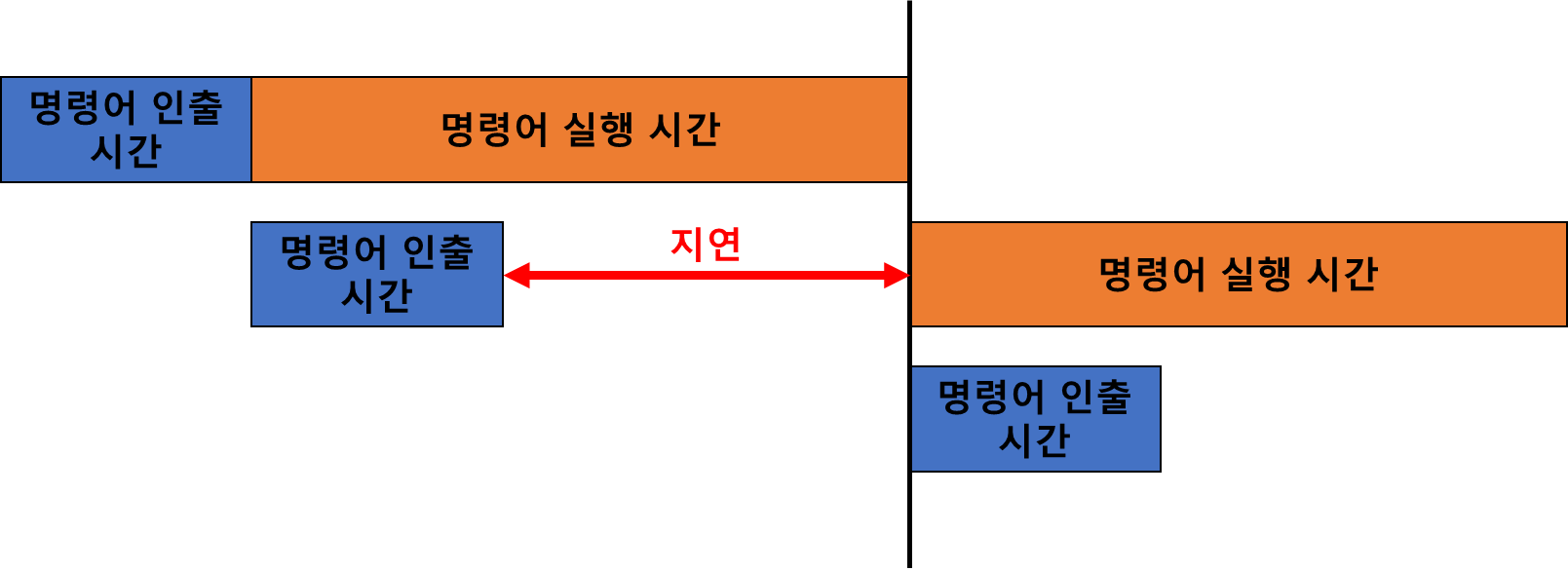
- 이 문제를 실행 단계 세분화로 극복할 수 있다.
- 조건 분기 명령어에서는 다음에 인출할 명령어의 주소를 알 수 없다.
-
원인: 제어 해저드
해저드에 관해선 이후에 다룬다.
-
추정(guessing)을 통해서 성능을 극복할 수 있다.
-
- 파이프라인에 남아 있는 명령어에 따라서 레지스터의 내용이 변경될 수 있다.
- 원인: 데이터 해저드
- 파이프라이닝 시, 다음 단계에서 오퍼랜드 인출 과정에 영향을 줄 수 있다.
- 레지스터와 기억장치 충돌 가능성이 있다.
- 원인: 자원 해저드
- 따라서 충돌 해결을 위한 회로가 필요하다.
속도향상을 위한 다단계 파이프라이닝 구성: 실행단계 세분화
‘명령어 단계’를 아래와 같이 세분화한다.
- 명령어 인출 (FI: Fetch Instruction)
- 다음 명령어를 읽어서 버퍼에 넣는다.
- 명령어 해독 (DI: Decode Instruction)
- 연산 코드와 오퍼랜드 지정자를 결정한다.
- 오퍼랜드 주소 계산 (CO: Calculate Operands)
- 각 오퍼랜드의 유효 주소를 계산한다.
- 오퍼랜드 인출 (FO: Fetch Operands)
- 기억장치로부터 각 오퍼랜드를 인출한다.
- 명령어 실행 (EI: Execute Instruction)
- 지정된 연산을 수행하고, 결과가 있다면 지정된 목적지 오퍼랜드 위치에 저장한다.
- 오퍼랜드 저장 (WO: Write Operation)
- 결과를 기억장치에 저장한다.
명령어 파이프라인 동작의 시간 흐름도
가정: 시스템 버스를 사용하지 않고 ‘캐시’나 ‘레지스터’만을 사용하는 경우라고 가정한다.
(Main Memory에 접근하는 경우, 아래와 같이 수행되지 않는다.
그 이유는 나중에 해저드 부분에서 다룬다.)
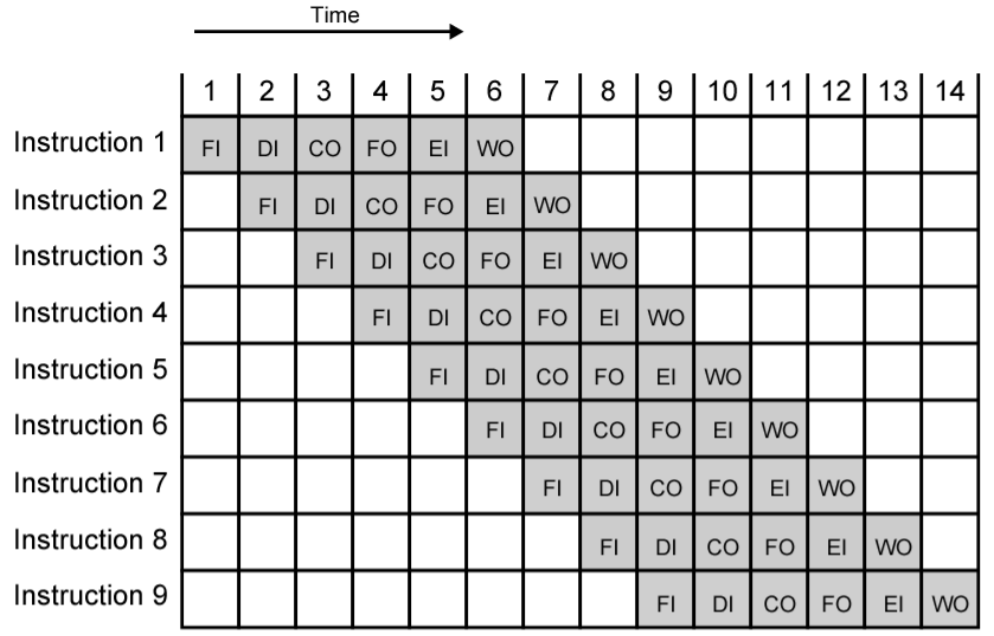
- 주의사항
- 모든 명령어가 위와 같이 총 6단계를 수행하지는 않는다.
- 예시) LOAD 명령의 경우 WO단계가 필요하지 않다.
- 모든 명령어가 위와 같이 총 6단계를 수행하지는 않는다.
조건 분기가 명령어 파이프라인 동작에 미치는 영향
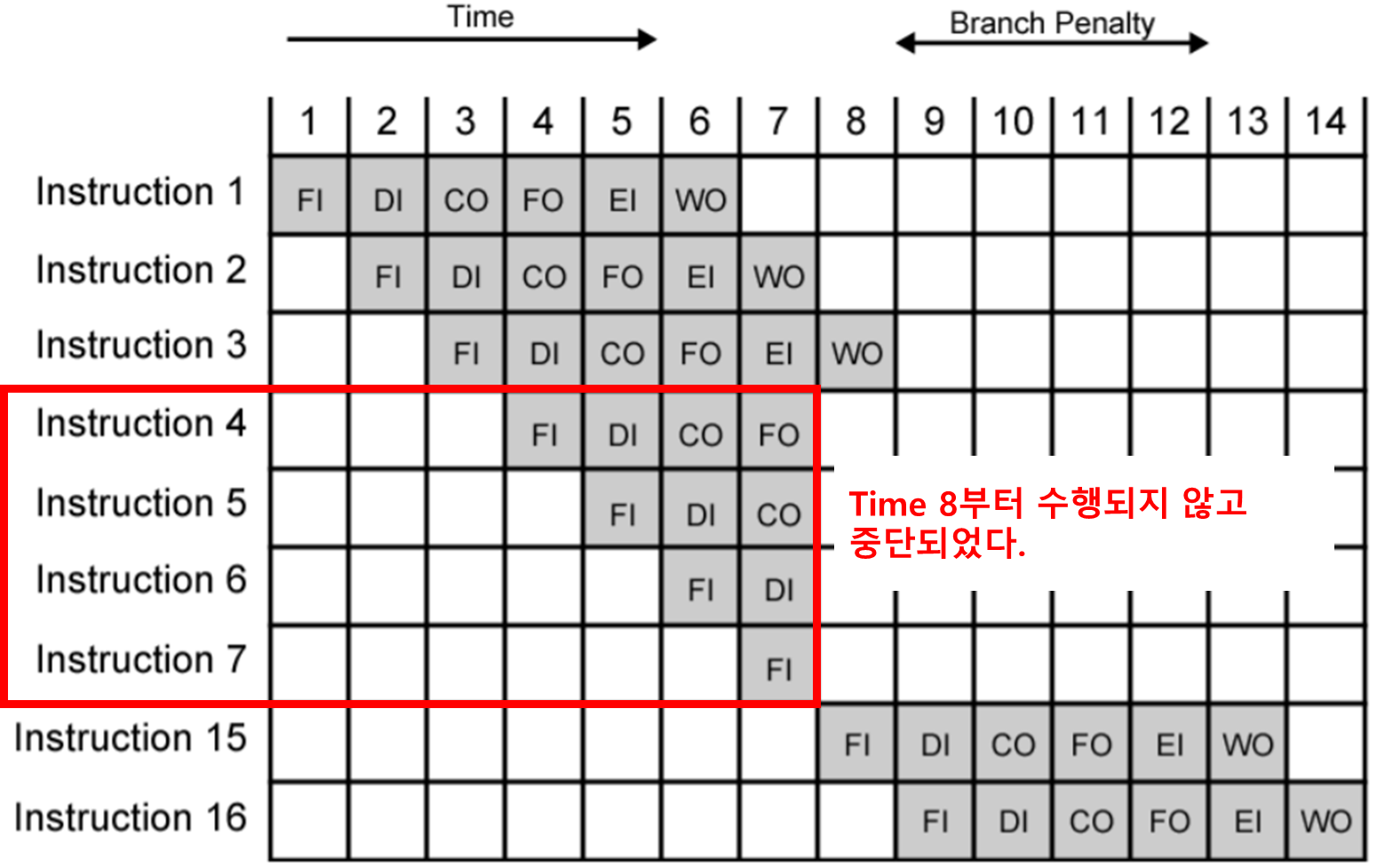
- 위 그림을 보자. 명령어 4, 5, 6, 7이 파이프라이닝 도중 중단되었음을 확인할 수 있다.
- 이것은 “명령어 3 = 조건 분기 명령어” 이기 때문이다.
- 명령어 3을 수행 완료한 결과, 흐름이 분기되어 명령어 4~7을 건너뛰게 된 것이다.
- 즉 명령어 3의 조건문을 수행한 결과, 명령어 4~7을 수행하지 않아도 되게된 것이다.
- 이것을 Flushing이라고 한다.
-
Flushing이 발생하여 아래와 같이 성능 손실이 발생했다.
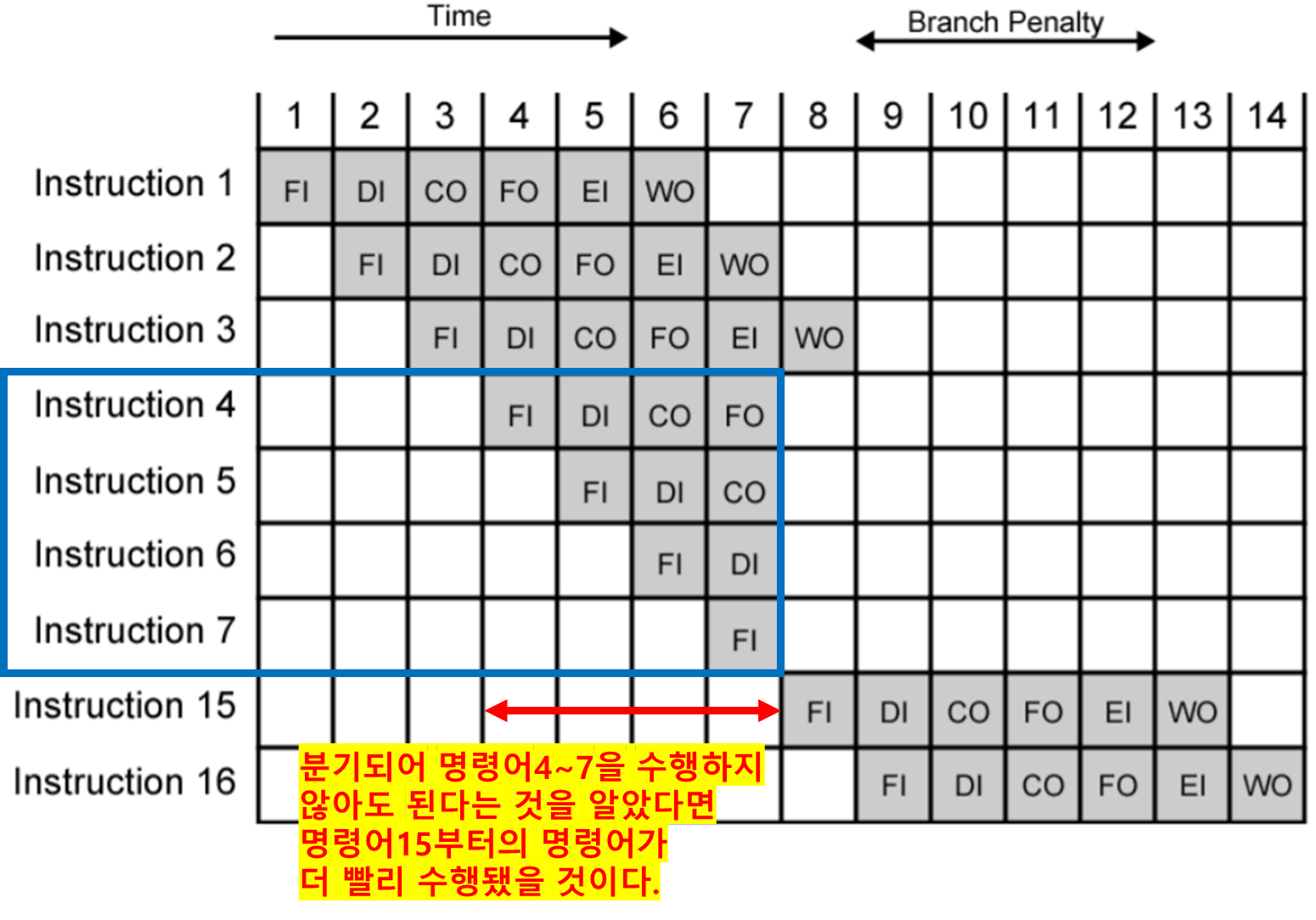
파이프라인 성능
- 사이클 시간
- 사이클 시간이란, 명령어들이 파이프라인의 한 단계를 통과하는데 걸리는 시간을 말한다.
- 한 단계: FI, DI 등의 단계
- 단,
= 사이클 시간
= i번째 단계에서 걸리는 시간
= 최대 단계 지연 (가장 긴 지연을 가지는 단계를 통과하는데 걸리는 지연)
= 명령어 파이프라인의 단계의 수
= 한 단계로부터 다음 단계로 신호가 넘어가는 데 걸리는 시간 지연 (오버헤드)
- 사이클 시간이란, 명령어들이 파이프라인의 한 단계를 통과하는데 걸리는 시간을 말한다.
- n개의 명령어들을 모두 처리하는데 걸리는 전체 시간
파이프라이닝에 따른 속도 향상률
- 파이프라이닝되는 명령어 수가 증가할수록 k배 정도 향상된 속도를 보인다.
- 예시) 4단계 파이프라이닝 → 대략 4배의 속도 향상
- 단, 완벽히 k배로 향상되지는 않는다.
-
왜냐하면 flushing과 같은 해저드 때문이다.
이것은 나중에 자세히 설명하겠다.
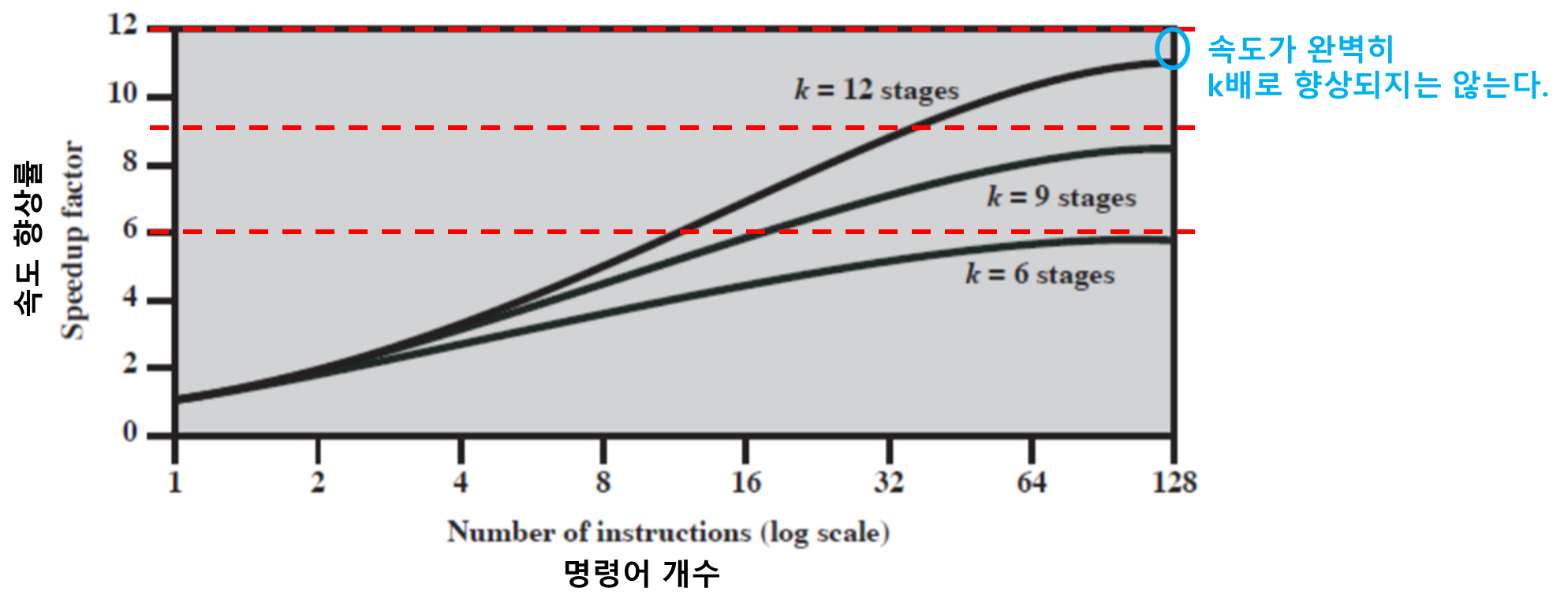
- 파이프라이닝의 단계수가 많아질수록 속도 향상의 가능성이 증가한다.
- 하지만 무조건 단계수가 많다고 속도가 향상되는 것은 아니다. 그 이유는 아래와 같다.
- 단계 추가에 따른 비용 증가
- 단계들 간의 지연 증가
- 분기에 따른 파이프라이닝의 플러싱(Flushing) 가능성 증가
- 하지만 무조건 단계수가 많다고 속도가 향상되는 것은 아니다. 그 이유는 아래와 같다.
파이프라인 해저드
- 파이프라인 해저드란?
- 조건들이 실행을 계속하는 것을 허용하지 않는다. ⇒ 파이프라인의 일부분이 멈추어야 하는 경우가 생긴다.
- 위와 같은 경우에 발생하여, 성능저하를 유발하는 것을 파이프라인 해저드라고 한다.
- 파이프라인 해저드 == 파이프라인 버블
- 조건들이 실행을 계속하는 것을 허용하지 않는다. ⇒ 파이프라인의 일부분이 멈추어야 하는 경우가 생긴다.
- 파이프라인 해저드 종류
- 자원 해저드
- 데이터 해저드
- 제어 해저드
각 해저드에 대해, 자세히 알아보자.
파이프라인 해저드: 자원 해저드
- 자원 해저드란?
- 이미 파이프라인에 들어와 있는 두 개 이상의 명령어들이 동일한 자원을 필요로 할 때 발생한다.
- 동일한 자원 예시: 포트(통로, ALU 등
- 자원 해저드 발생 시, 명령어들이 파이프라인의 일부분에서 직렬로 실행된다. (병렬X)
- 이미 파이프라인에 들어와 있는 두 개 이상의 명령어들이 동일한 자원을 필요로 할 때 발생한다.
- 자원 해저드 예시 1
- 가정
- 주기억장치가 하나의 포트를 가지고 있다.
- 포트: CPU와 Main Memory 간의 통로
- 모든 명령어 인출과 데이터 읽기·쓰기가 한번에 한개씩 수행된다.
- 주기억장치가 하나의 포트를 가지고 있다.
-
자원 해저드 발생
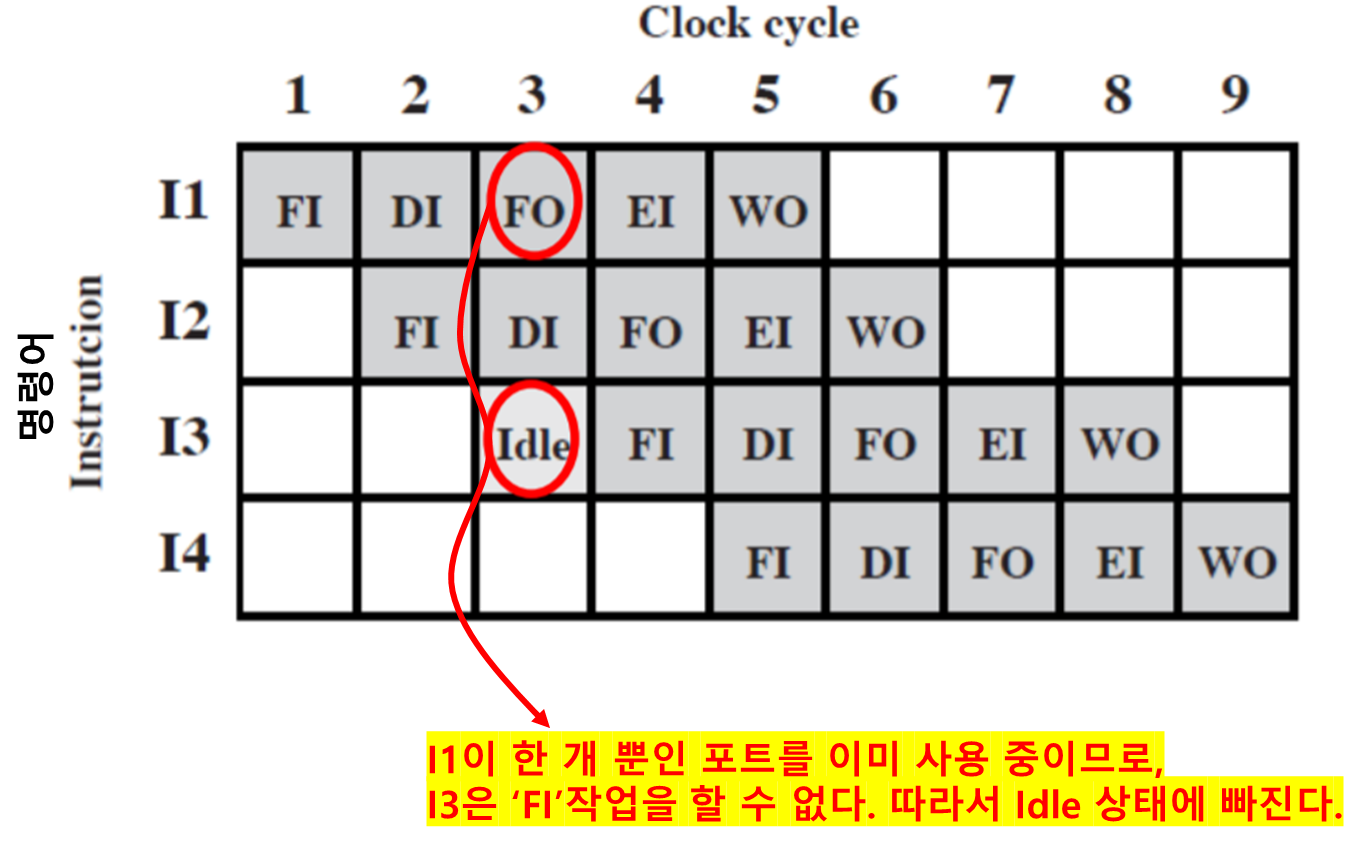
- 위 경우, ‘오퍼랜드를 기억장치로 읽어오거나 쓰는 것’은 ‘명령어 인출’과 함께(병렬) 수행될 수 없다.
- 가정
- 자원 해저드 예시 2
- 가정
- ALU가 한 개만 있다.
- 자원 해저드 발생
- 이때도 역시 자원 해저드가 발생한다.
- 이 경우, 명령어 실행(EI)가 병렬적으로 처리될 수 없다.
- 가정
- 자원 해저드 해결 방안
- 이용가능한 자원을 늘린다.
- 예시) 포트 다중화, ALU 다중화 등
파이프라인 해저드: 데이터 해저드
- 데이터 해저드란?
- 오퍼랜드 위치에 대한 액세스에 충돌이 있을 때 발생하는 해저드이다.
- 즉, 같은 오퍼랜드를 다른 명령어에서 접근하려고 할 때 발생한다.
- 데이터 해저드 발생 예시
- 가정
- 아래 명령어가 수행된다고 가정하자.
- ADD EAX, EBX ⇒ (EAX = EAX + EBX)
- SUB ECX, EAX ⇒ (ECX = ECX - EAX)
-
데이터 해저드 발생
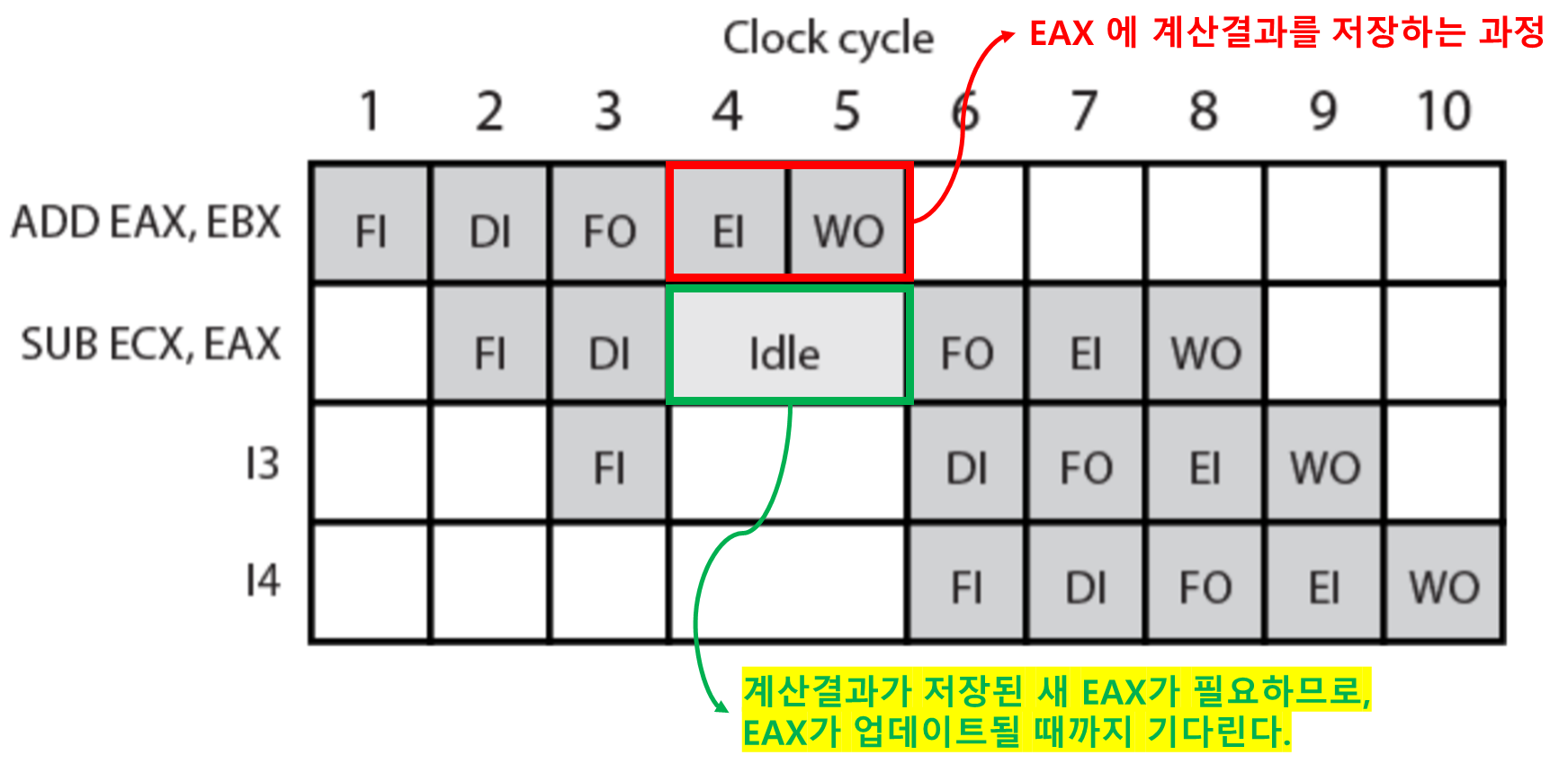
- 가정
파이프라인 해저드: 제어 해저드
- 제어 해저드란?
- 파이프라인이 분기 예측에서 잘못된 결정을 한 경우, 그 다음에 버려야할 명령어들을 파이프라인에 가져왔을 때 발생한다.
- 즉, 위에서 설명한 Flush 현상이 제어 해저드이다.
- 조건 분기를 처리하기 위한 대표적인 방법들
- 다중 열
- 루프 버퍼
- 분기 예측
조건 분기를 처리하는 방법들에 대해 하나씩 알아보자.
조건 분기 처리: 다중 열
- 다중 열이란?
- 파이프라인의 앞부분을 중복시켜 두 개의 명령어를 모두 인출시키는 것
- 즉, 분기에 의해 선택되는 모든 명령어를 인출한다.
- 총 두 개의 열을 이용한다.
- 문제점
- 여러 개의 파이프라인들이 있을 때는, 레지스터와 기억장치에 대한 액세스 과정에서 경합이 발생하여 지연이 발생할 수 있다.
- 원래의 분기에 대한 판단이 완료되기 전에, 다른 분기 명령어가 파이프라인으로 들어올 수 있다.
- 모든 명령어를 인출하므로
조건 분기 처리: 루프 버퍼
- 루프 버퍼란?
- 루프 버퍼는 파이프라인의 명령어 인출 단계에 포함되어 있는 작은 고속 기억장치이다.
- 가장 최근에 인출된 n개의 명령어들이 루프 버퍼에 순서대로 저장되어 있다.
- 명령어 전용 캐시와 유사하다고 생각할 수 있다.
- 분기가 이루어졌을 때 동작
- 먼저 분기의 목표가 버퍼에 있는지 검사한다.
- 버퍼에 있으면 다음 명령어는 버퍼로부터 인출된다.
- 루프나 반복을 처리하는데 적합하다!
- 이전 명령어를 저장해뒀기 때문에 루프 처리에 유리하다.
조건 분기 처리: 분기 예측
- 분기 예측의 방식
- 정적 방식
- 분기가 일어나지 않을 것으로 예측한다.
- 순서대로 다음 명령어를 계속 인출한다.
- 즉 분기를 고려하지 않는다.
- 분기가 항상 일어날 것으로 예측한다.
- 항상 분기 목적지로 명령어를 인출한다.
- 분기 명령어의 연산 코드에 근거한 예측
- 분기가 어떤 분기 연산 코드에서는 일어나고 다른 코드들에서는 일어나지 않는다고 가정한다.
- 분기가 일어나지 않을 것으로 예측한다.
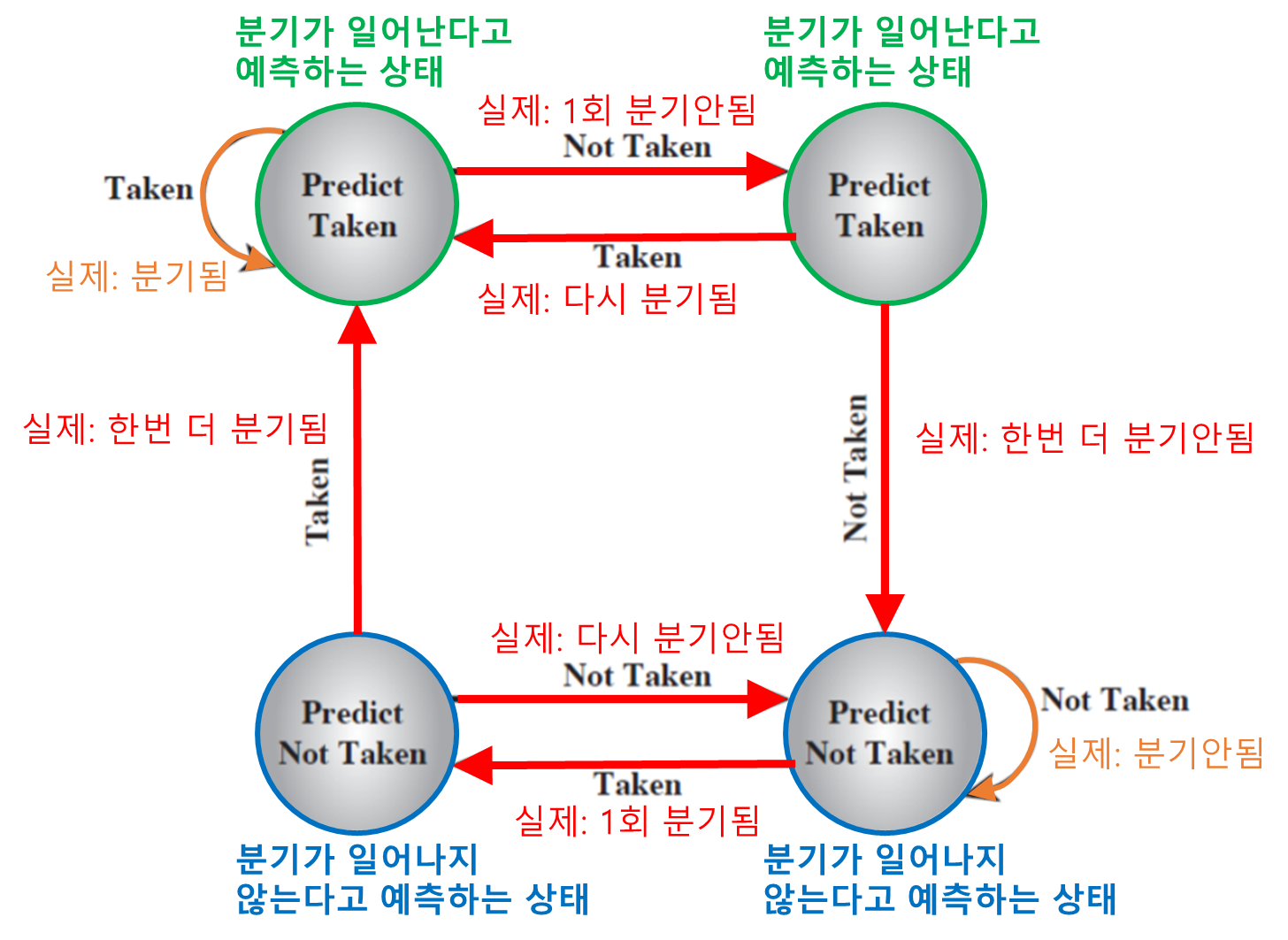
- 동적 방식
- 발생/미발생 스위치
- 각 조건 분기 명령어에 대해, 명령어의 최근 역사를 반영한다.
- 발생/미발생 스위치
- 정적 방식
발생/미발생 스위치에 대해 더 자세히 알아보자.
-
발생/미발생 스위치 동작 원리
수퍼스칼라
수퍼스칼라란?
- 수퍼스칼라라는 시스템 구조란, 여러 개의 파이프라인들에서 독립적으로 명령어를 실행하는 구조를 말한다.
- 예시)
- 정수 연산 수행 파이프라인, 부동소수점 연산 파이프라인
- 위 두가지는 서로 별개로 구성되므로, 이들 연산을 동시에 수행할 수 있다.
- 명령어들이 프로그램 순서와 다르게 실행하는 것을 허용해야 한다.
- 여러 개의 명령어들을 동시에 인출한다.
- 가까이 있는 서로 독립적인 명령어들을 찾아서 병렬로 실행한다.
- 그래서 명령어 병렬처리 시, 명령어 간의 의존성 해결 방안이 필요하다.
병렬성에 대한 제한 사항
- 수퍼스칼라의 성능
- “여러 개의 명령어들을 병렬로 실행하는 능력”이 결정한다.
- 병렬성을 최대로 유지하기 위해, 아래 기법들을 혼용하여 사용한다.
- 컴파일에 의한 최적화
- 정적 방식
- 고급언어를 컴파일러가 번역 시, 각 명령어가 병렬처리되게끔 번역하는 기법이다.
- 하드웨어 기법
- 동적 방식
- 순간순간에 발생하는 의존성 문제를 해결한다.
- 컴파일에 의한 최적화
- 수퍼스칼라의 주요 제한 사항
- 데이터 의존성
- 데이터 해저드와 유사하다.
- 프로시저 의존성
- ‘분기 명령어’와 ‘분기 다음 명령어’는 동시에 실행될 수 없다.
- 자원 충돌
- 자원 해저드와 유사하다.
- 데이터 의존성
의존성의 영향
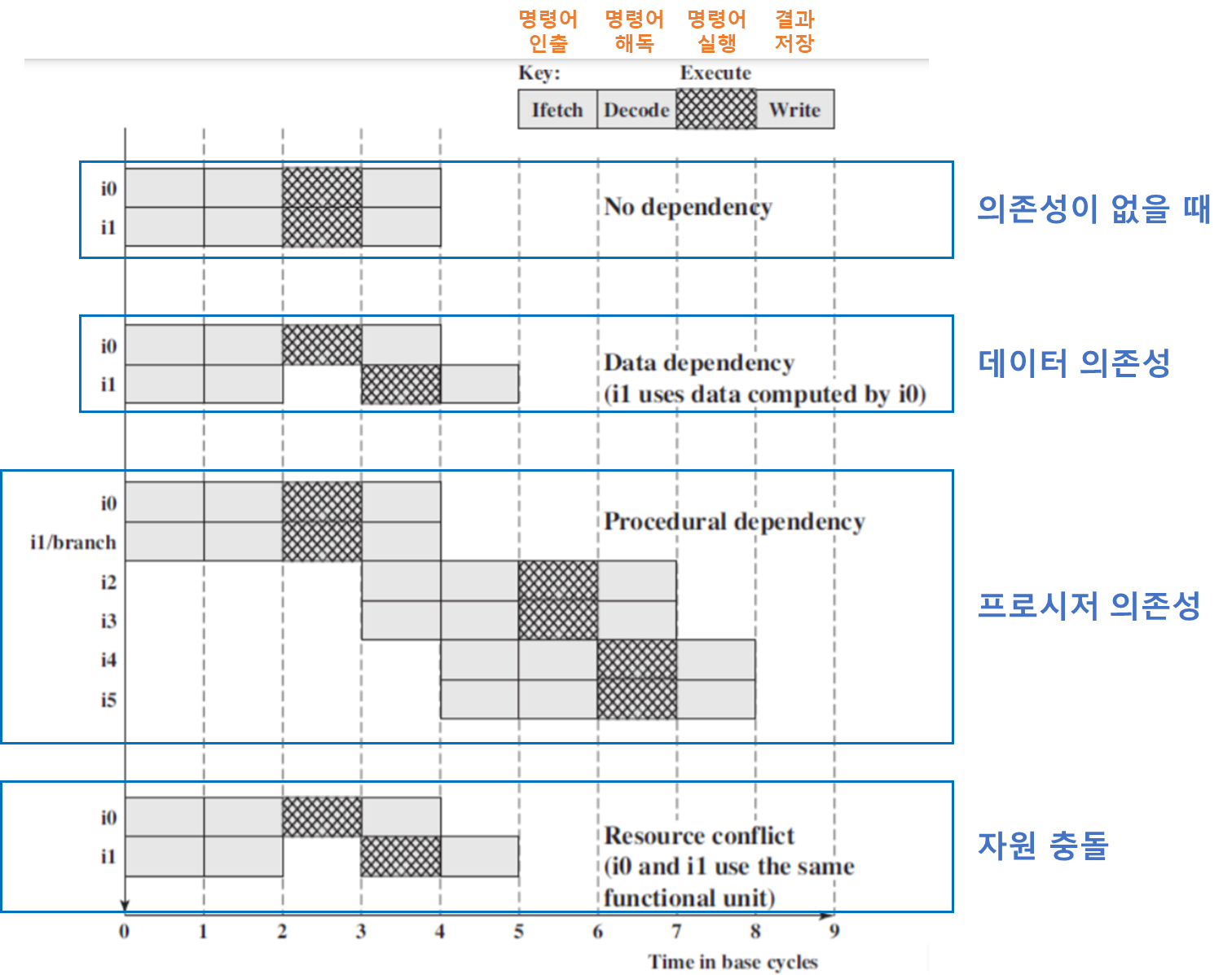
명령어 수준 병렬성
-
데이터 의존성 예시
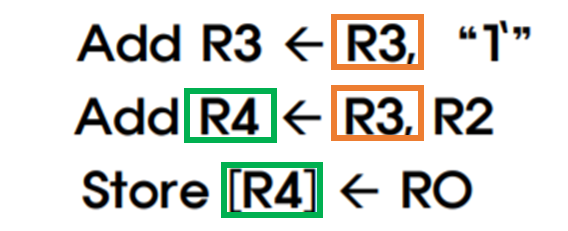
Add R3 ← R3, "1"가 완료되어 R3이 갱신될 때까지,Add R4 ← R3, R2는 기다려야 한다.Add R4 ← R3, R2가 완료되어 R4가 갱신될 때까지,Store [R4] ← R0는 기다려야 한다.
- 병렬 수준은 코드 내에 존재하는 데이터의 의존성과 프로시저 의존성의 발생 빈도에 의해 결정된다.
- 기계 병렬성
- 프로세서가 명령어 수준 병렬성을 활용할 수 있는 능력을 나타내는 척도이다.
수퍼스칼라 기반 명령어 실행
- “실행될 프로그램”은 순차적으로 배열된 명령어로 구성된다.
- “명령어 인출 과정 (분기 예측 포함)”을 통해서, 명령어들의 동적 흐름이 형성된다.
- 프로세서는 그 명령어들을 실행 윈도우로 발송한다.
- 이때, 순차적인 명령어가 ‘명령어 간의 의존성’에 따라 재구성되어, 더이상 순차적이지 않게 된다.
- 프로세서는 실제 데이터 의존성과 하드웨어 자원의 사용 가능성에 의해 결정된 순서에 따라, 각 명령어의 실행 단계를 수행한다.
- 명령어들은 개념적으로 다시 순차적 순서로 돌아가며, 결과가 기록된다.
- 즉, 다시 순차적으로 명령어 순서가 구성된다.
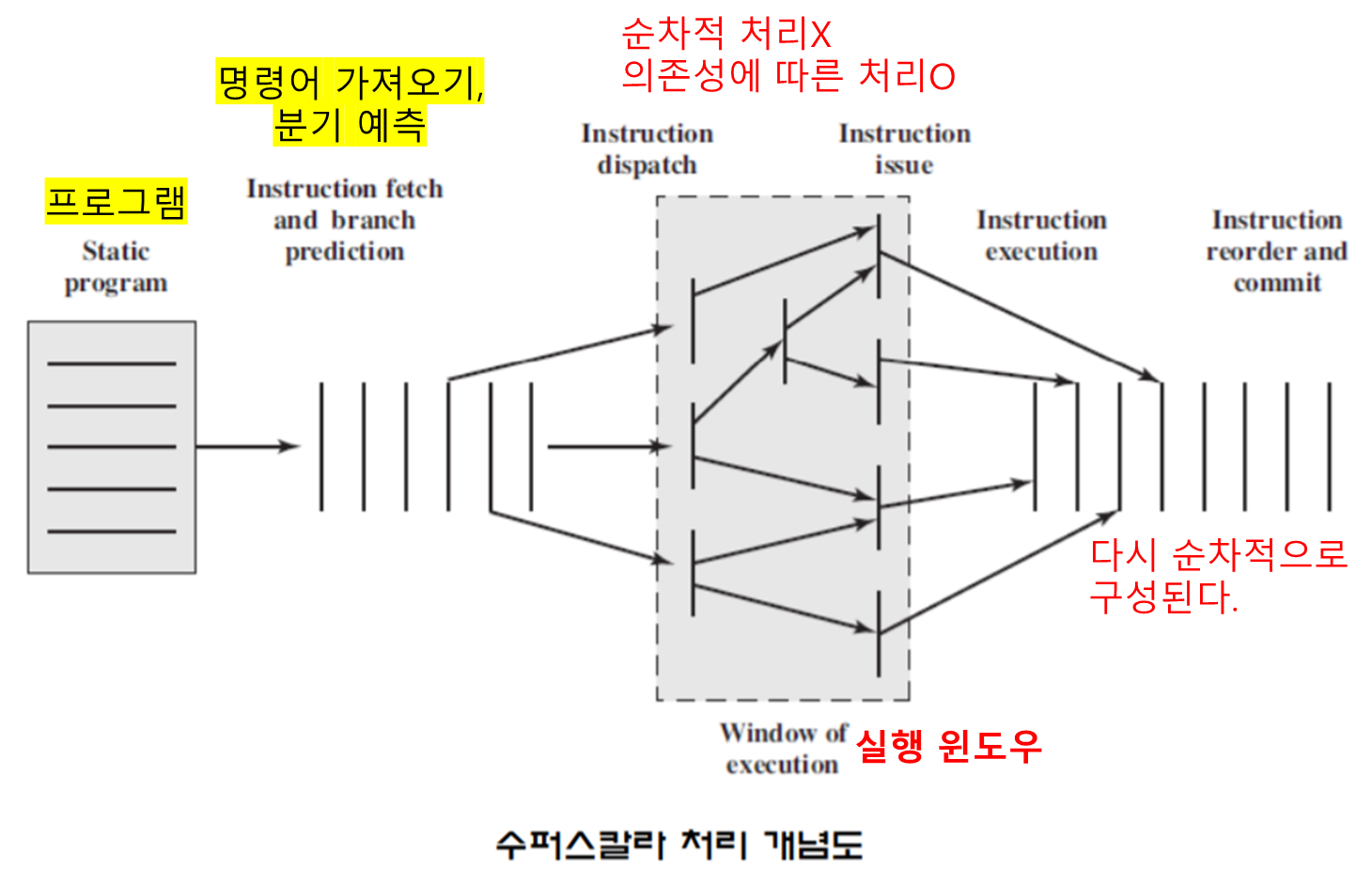
수퍼스칼라를 구현하기 위한 하드웨어 요소
- 여러 명령어들을 동시에 인출하는 명령어 인출 방식 사용
- 의존성 결정 회로
- 여러 명령어들을 병렬로 시작하거나 발송하는 메커니즘
- 프로세스 상태를 올바른 순서대로 결정해주는 메커니즘
- 성결대학교 컴퓨터 공학과 최정열 교수님 (2021)
- William Stalling, 『컴퓨터시스템구조론(10판)』