
컴퓨터 구조 개요
컴퓨터의 조직과 기능
컴퓨터 SW와 HW
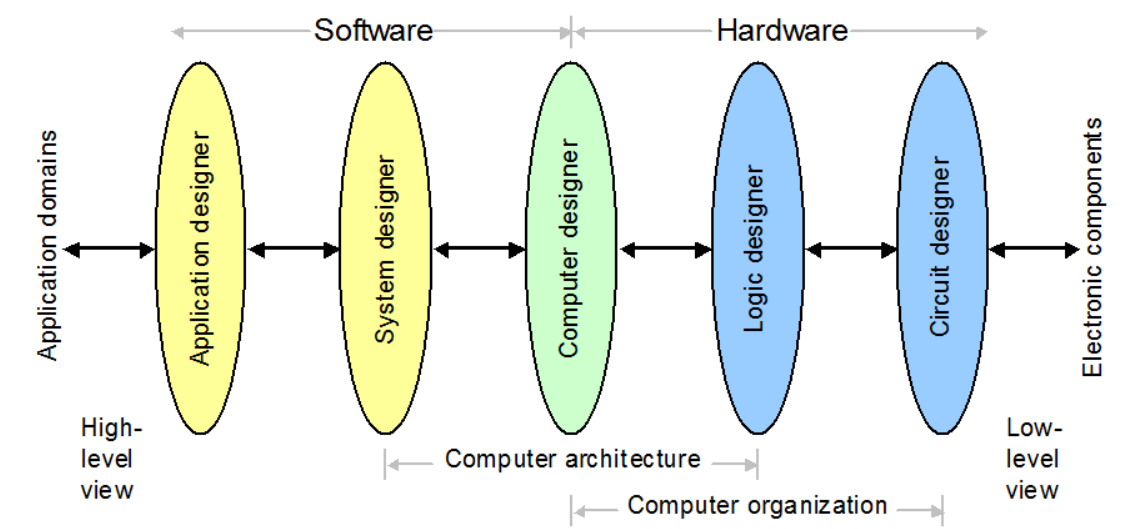
- Application designer
- 일반적인 응용 애플리케이션 계층
- Software
- System designer
- OS 나 컴파일러와 같은 시스템 계층
- Software
- Logic designer
- 논리회로 계층
- Hardware
- Circuit designer
- 전자회로 계층
- Hardware
컴퓨터의 기능
- 데이터 처리
- 관련 장치: CPU의 ALU
- 데이터 저장
- 관련 장치: RAM, HDD 등
- 데이터 이동
- 관련 장치: Bus
- 제어
컴퓨터의 조직
- 중앙처리장치
- CPU
- 주기억 장치
- Main Memory
- 입출력
- I/O
- 시스템 상호연결
- Bus
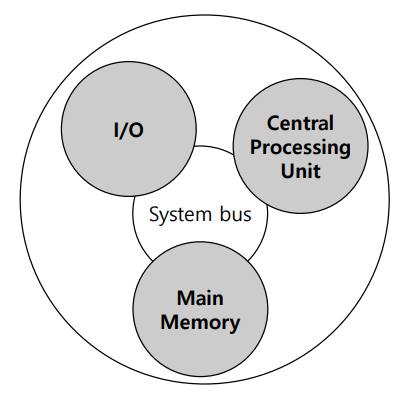
컴퓨터 구성
컴퓨터 주요 부품 목록
- Main Board
- CPU
- RAM
- Chipset
- HDD
- DVD
- Graphic card
- Power Supply
Main Board
- 공통의 버스 배선과 인터페이스 회로를 모아 놓고, 슬롯 형태의 작은 보드를 꽂아 사용하는 기판 구조에서 어미가 되는 기판이다.
중앙처리장치
- 컴퓨터 시스템 전체를 제어한다.
- CPU 구성요소
- ALU: 산술·논리 연산장치
- C.U: 제어장치
- R: 레지스터
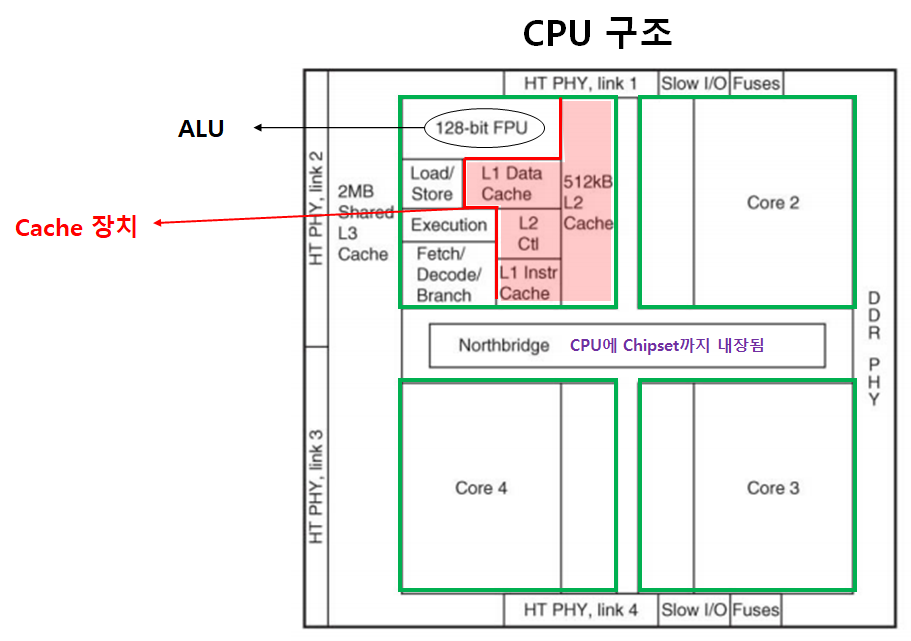
-
CPU의 Cache 장치 필요성
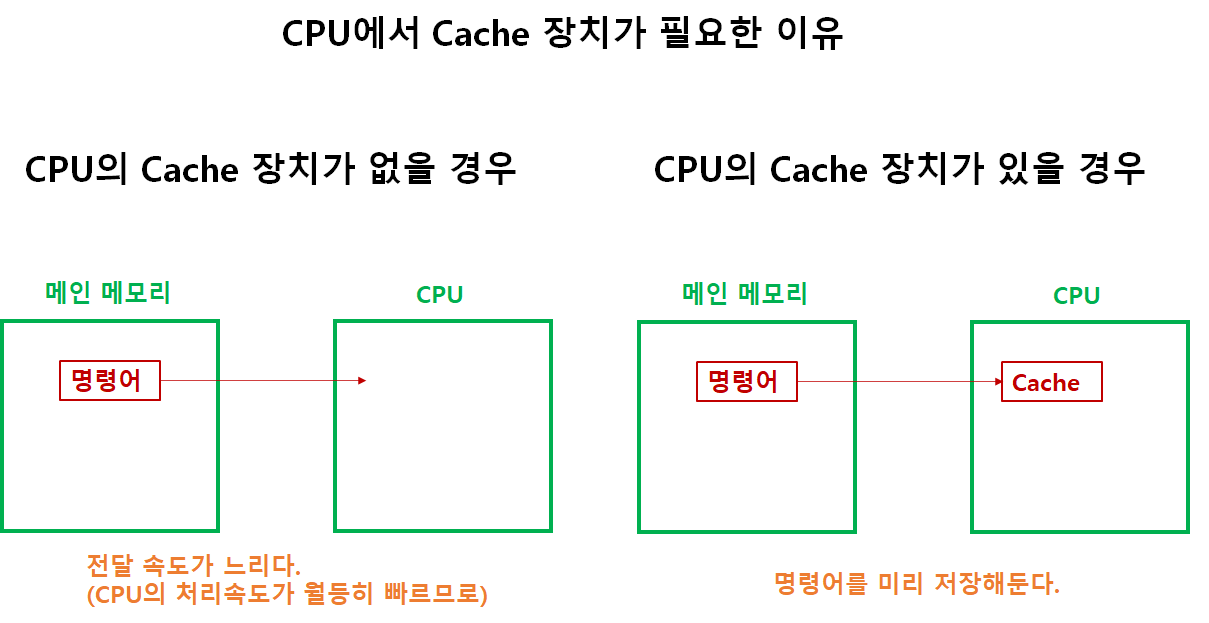
- L1 Cache
- L2 Cache
- L3 Cache
- 위 순서대로 용량이 커지며, 프로세서가 순서대로 확인한다.
Chipset
- 여러 칩과 회로가 모여 서로 연관된 기능을 수행하도록 설계된 제어칩들의 조합이다.
- CPU 프로세서와 함께 시스템 전체를 제어한다.
- 칩셋 내부 회로
- CPU를 지원하는 각종 제어 장치들로 구성되어 있다.
- 버스 컨트롤러, 메모리 컨트롤러, I/O 컨트롤러, 인터럽트 컨트롤러, 타이머 등
요즘에는 CPU에 Chipset이 내장되어 있다.
주기억장치
- 수행 중인 프로그램과 이를 위해서 필요한 데이터를 기억하고 있는 장치
- 비교적 CPU에 접근 속도가 빠르며 많은 용량을 기억한다.
- RAM(Random Access Memory)이 주로 사용된다.
- D-RAM
- Dynamic
- 전력 공급이 끊어지면, 데이터가 삭제됨.
- S-RAM
- Static
- 전력 공급이 끊어져도, 데이터는 유지됨.
- D-RAM
보조기억 장치
- 외부 기억장치
- 반영구적으로 데이터를 저장하고 보존한다.
- 중앙처리장치와 직접 정보를 교환할 수 없기 때문에, 저장된 데이터가 주기억장치로 옮겨진 후 처리된다.
- 주기억장치에 비해, 가격은 저렴하고 용량이 크지만 속도가 느리다.
소프트웨어
시스템 소프트웨어
- 컴퓨터 시스템을 제어하고 효율적으로 사용하기 위해 만들어진 소프트웨어
- 운영체제, 디바이스 드라이버, 컴파일러, 인터프리터
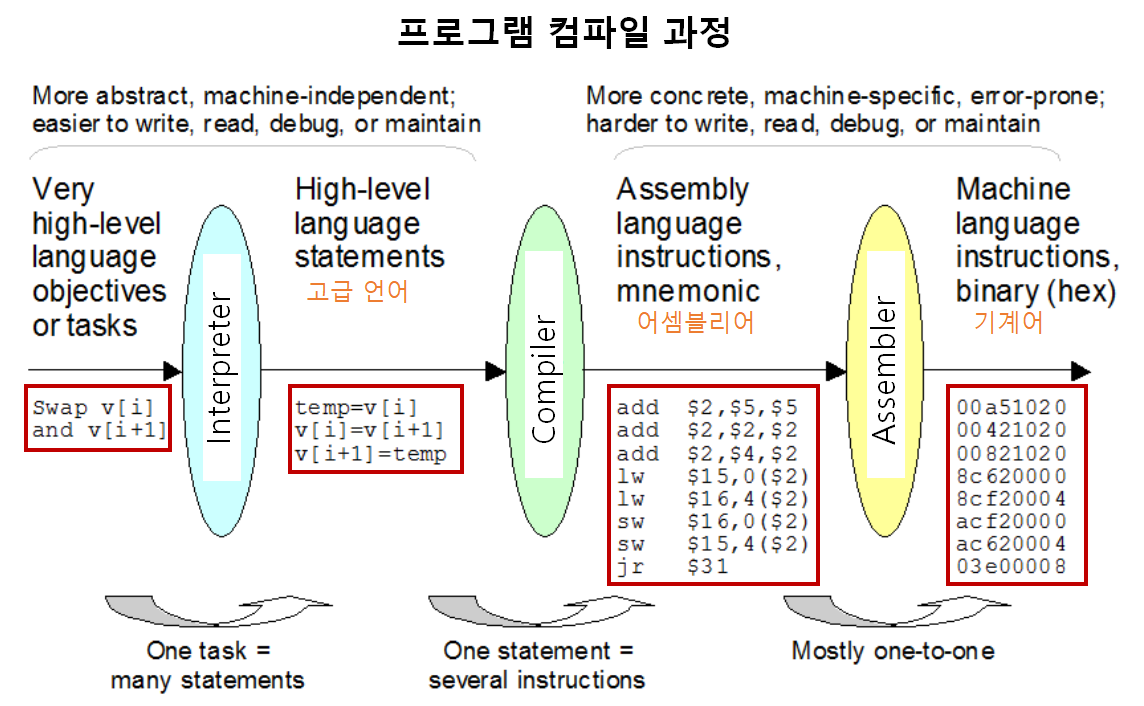
프로그래밍에서의 모델 및 추상 수준
집적회로
무어의 법칙
- 컴퓨터의 크기가 작어졌다.
- 논리회로/기억 소자들이 가까워져 전기적 통로의 길이가 줄어들어 동작 속도가 상승했다.
- 집적회로 내에서 연결되어 납땜 연결보다 신뢰성이 높아졌다.
- 집적도가 상승되는 동안 칩 가격은 변하지 않았다.
- 전력 소모가 줄어들었다.
컴퓨터의 성능 향상
성능 균형 문제
- 성능 균형 문제란?
- 프로세서와 주기억장치 간 인터페이스에서 병목이 발생하는 현상
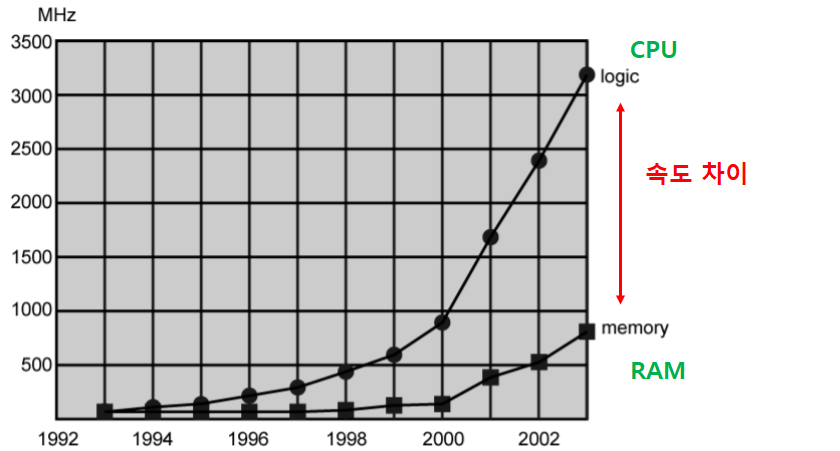
- 입출력 장치에서의 성능 균형 문제
- 프로세서와 입출력 장치 간의 데이터 이동은 여전히 해결되지 않은 문제이다.
- 성능 균형 문제 해결법
- 버스 대역폭 확대
- (CPU 내부의) 캐시 메모리 활용
CPU 동작 순서
- 명령어 인출
- 명령어 해독
- 데이터 인출
- 데이터 처리 (실행)
- 데이터 저장
프로세서 속도 향상 방안
- 프로세서의 하드웨어 속도 증가시키기
- 논리 게이트 크기를 줄이고, 더 많은 게이트를 조밀하게 넣는다.
- 클럭 속도를 높인다.
- 신호들의 전파 시간을 감소시킨다.
- 프로세서-주기억장치 사이에 존재하는, 캐시의 크기와 속도를 증가시킨다.
- 명령어 실행 속도를 높일 수 있도록, 프로세서 조직과 구조를 변경한다.
-
파이프라이닝
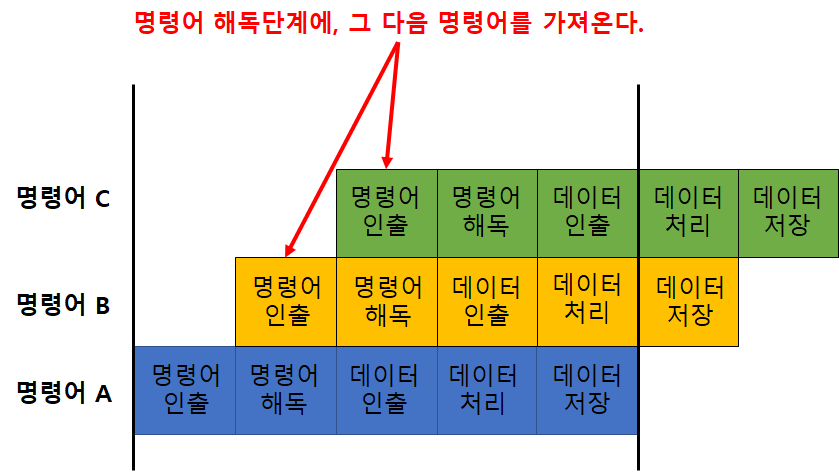
-
수퍼스칼라
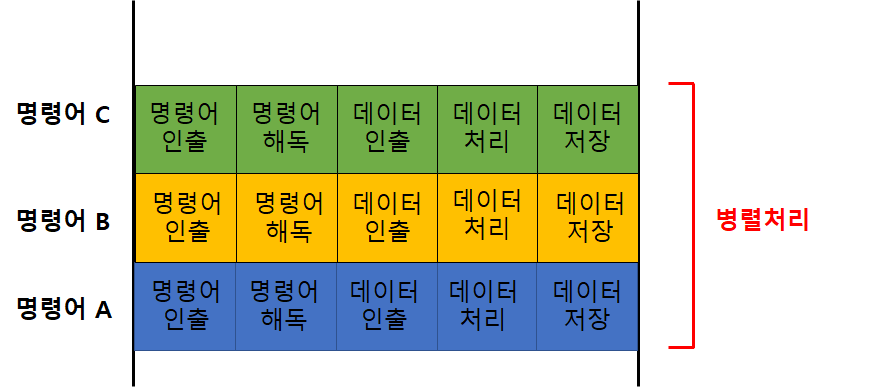
-
CPU 클럭이란?
- CPU가 일을 하는 단위이다.
- ex) 명령어 해독
- 클럭율: Hz로 나타낸다.
클럭 속도와 회로 밀도 문제
- 칩 내부 회로의 밀도와 클럭 속도가 높아지면, 전력밀도(단위면적당 전력소모량)이 증가한다.
- 트랜지스터 하나가 소비하는 전력
- ‘논리 값이 한번 바뀔때 소모되는 에너지’ * ‘시간당 논리 값이 바뀌는 빈도수’
성능 향상을 위한 새로운 시도: 멀티코어
- 멀티코어
- 큰 용량의 캐시를 공유하는 여러 프로세서를 하나의 칩에 배치한 것이다.
- 하나의 복잡한 프로세서를 사용하기보다는, 칩 내에 더 간단한 여러 프로세서를 배치하는 것이 좋다.
- 소프트웨어가 여러 개의 프로세서들을 효과적으로 사용하도록 지원한다면, 프로세서의 개수 만큼 성능 향상을 기대할 수 있다.
컴퓨터 성능 평가
프로세서의 평가 요소
- 성능
- 가격
- 크기
- 전력 소비
- 신뢰성
관점에 따른 컴퓨터 성능 평가
- 사용자 관점
- 응답시간 or 실행시간이 중요하다.
- 실행시간
- 컴퓨터가 테스크를 완료하기까지의 총 소요시간
- 디스크 접근, 메모리 접근, 입출력 작업, 운영체제의 오버헤드 및 CPU 시간을 포함한다.
- 시스템 관점
- 처리량 or 대역폭이 중요하다.
- 대역폭
- 일정한 시간 동안 처리하는 작업의 양
성능의 정의
- 프로그램의 실행 시간
- 한 작업을 끝내는데 필요한 전체 시간
- 디스크 접근, 메모리 접근, 입출력 작업, 운영체제의 오버헤드 등 모든 시간을 더한 것이다.
- CPU 실행 시간 (CPU 시간)
- 프로세서가 순수하게 이 프로그램을 실행하기 위해서 소비한 시간
- 성능의 정의
- 성능 = 1 / 수행시간
- 성능 = 1 / CPU실행시간
- CPU실행시간 = 명령어_수 * 명령어당_클럭_사이클_수 * 사이클당_초
- CPU실행시간 = 명령어_수 * CPI / 클록율
- CPI: 명령어당 클럭 사이클 수
성능에 영향을 미치는 요소
- 클록 사이클 수 (clock cycles)
- 클럭 사이클이란?
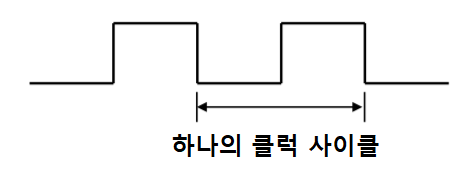
- 공식
- 
와
에 대해선 아래에서 설명하겠다.
- 
- 클럭 사이클이란?
- 클록율 (clock rate)
- Hz 단위로 표현한다.
- 1 Hz = 1초에 1개의 사이클을 수행한다.
- 공식
- 예시
- 10 나노초에 1개의 사이클을 수행한다. ⇒ 10 nsec(nano second) clock cycle ⇒ 100 MHz clock rate
- 2 나노초에 1개의 사이클을 수행한다. ⇒ 2 nsec clock cycle ⇒ 500 MHz clock rate
- 1 나노초에 1개의 사이클을 수행한다. ⇒ 1 nsec clock cycle ⇒ 1 GHz clock rate
- 200 피코초에 1개의 사이클을 수행한다. ⇒ 200 psec(pico second) clock cycle ⇒ 5GHz clock rate
- 단위 정리
- 나노: 10^(-9)
- 피코: 10^(-12)
- GHz: 1,000,000,000 Hz (10억)
명령어 당 사이클 수 (CPI)
- CPI: Cycles Per Instruction
- 하나의 명령어를 수행하기 위해서 소요되는 클럭 사이클 수 (평균)
- 공식
- 
: 명령어 유형
를 위해 필요한 사이클 수
: 전체 명령어의 수
- n : 명령어 유형의 개수
- 주어진 프로그램을 수행하는데 필요한 프로세서(CPU) 시간 T
: 클럭 사이클 시간
- 명령어 실행 및 기억장치 이동시간 등을 고려한 프로세서(CPU) 시간 T
- ![T=I_c[p+(mk)]\tau](https://latex.codecogs.com/svg.image?T=I_c[p+(mk)]\tau)
- ![T=I_c[p+(mk)]*\tau](https://latex.codecogs.com/svg.image?p) : 명령어를 해독하고 실행하는데 필요한 프로세서 사이클의 수
- ![T=I_c[p+(mk)]*\tau](https://latex.codecogs.com/svg.image?m) : 필요한 기억장치 참조 수
- ![T=I_c[p+(mk)]*\tau](https://latex.codecogs.com/svg.image?k) : 기억장치 사이클 시간과 프로세서 사이클 시간 간의 비율
명령어 세트
- 명령어 수
- 하나의 프로그램을 수행하기 위해서 필요한 기계 명령어 개수
- 명령어 세트 종류
- CISC 명령어 세트 (시스크)
- 시스크 프로세서에서 사용된다.
- RISC 명령어 세트 (리스크)
- 리스크 프로세서에서 사용된다.
즉, 프로세서(CPU)의 종류에 따라 명령어 세트가 결정된다.
- CISC 명령어 세트 (시스크)
-
예시

예제 문제: CPI - 1
- 문제
- 같은 명령어 집합 구조 (CISC or RISC)를 구현한 컴퓨터 두 종류가 있다. 컴퓨터 A의 클럭 사이클 시간은 250ps이고 어떤 프로그램에 대한 CPI는 2.0이다.
컴퓨터 B의 클럭 사이클 시간은 500ps이고, CPI는 1.2이다. 이 프로그램에 관해서는 어떤 컴퓨터가 얼마나 더 빠른가?
- 같은 명령어 집합 구조 (CISC or RISC)를 구현한 컴퓨터 두 종류가 있다. 컴퓨터 A의 클럭 사이클 시간은 250ps이고 어떤 프로그램에 대한 CPI는 2.0이다.
- 풀이
- 공식: 주어진 프로그램을 수행하는데 필요한 프로세서 시간
- 컴퓨터 A의 프로세서 시간
- 
- 컴퓨터 A의 프로세서 시간
- 
- 이때, 컴퓨터 A와 B가 서로 같은 명령어 집합 구조를 구현했다고 했다.
- 따라서,
- 따라서,
- 그러므로,
이다.
- 즉, 컴퓨터 A가 B보다 1.2배 빠르다.
- 공식: 주어진 프로그램을 수행하는데 필요한 프로세서 시간
예제 문제: CPI - 2
- 문제
- 어떤 컴파일러 설계자가 같은 상위 수준 언어 문장에 대해 생성된 두가지 코드 1과 2 중 하나를 선택하려고 한다.
어떤 코드가 더 많은 명령어를 실행하는가? 어떤 코드가 더 빠른가? 각 코드의 CPI는 얼마인가?
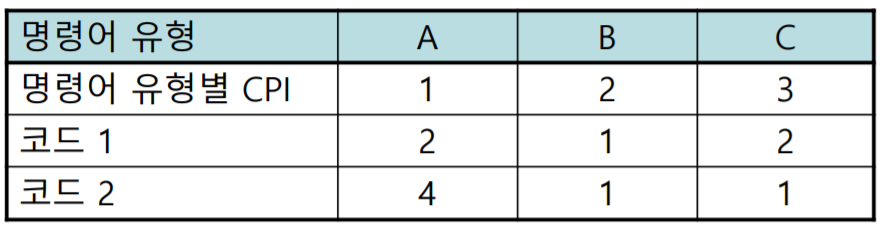
- 어떤 컴파일러 설계자가 같은 상위 수준 언어 문장에 대해 생성된 두가지 코드 1과 2 중 하나를 선택하려고 한다.
- 풀이 및 정답
- 문제: 어떤 코드가 더 많은 명령어를 실행하는가?
- 코드 1의 총 명령어 개수
- 코드 2의 총 명령어 개수
- 정답: 코드 2
- 코드 1의 총 명령어 개수
- 문제: 어떤 코드가 더 빠른가?
- 코드 1의 클럭 사이클
- 
- 코드 2의 클럭 사이클
- 
- 정답: 코드 2
- 코드 1의 클럭 사이클
- 문제: 각 코드의 CPI
- 코드 1의 CPI
- }{5}=2)
- 코드 2의 CPI
- }{6}=1.5)
- 코드 1의 CPI
- 문제: 어떤 코드가 더 많은 명령어를 실행하는가?
예제 문제: CPI - 3
- 문제
- 2GHz 클럭의 컴퓨터 A에서 10초에 수행되는 프로그램이 있다. 이 프로그램을 6초 동안에 실행할 컴퓨터 B를 설계하고자 한다.
클럭 속도는 얼마든지 빠르게 만들 수 있는데, 이렇게 하면 CPU의 다른 부분에 대한 설계에 영향을 미쳐 같은 프로그램에 대해 A보다 1.2배 많은 클럭 사이클이 필요하다고 한다.
컴퓨터 B의 클럭 속도는 얼마로 해야하는가?
- 2GHz 클럭의 컴퓨터 A에서 10초에 수행되는 프로그램이 있다. 이 프로그램을 6초 동안에 실행할 컴퓨터 B를 설계하고자 한다.
- 풀이
- 공식: 클록율
- 
- 그러므로, 컴퓨터 B의 클럭속도는 4GHz 로 해야한다.
- 공식: 클록율
암달의 법칙
- 암달의 법칙
- 단일 프로세서와 비교하여, 다수의 프로세서들을 사용한 프로그램의 잠재적 속도 향상 정도를 다룬다.
- 공식
: 단일 프로세서를 이용하여 특정 프로그램을 처리하는데 걸리는 시간
: 병렬 프로세서의 개수
: 한 프로그램에서 스케줄링 오버헤드 없이, 무한히 병렬화할 수 있는 코드의 비율
예제 문제: 암달의 법칙 - 1
- 문제
- 어떤 연산의 수행 시간이 50%를 차지하는 프로그램이 존재한다.
- 이때, 하드웨어를 2배 빠르게 만든다면(2개의 프로세서를 사용한다면) 수행시간이 얼마나 향상되는가?
- 또, 이 연산을 2배 빠르게 수행하려면 하드웨어를 얼마나 개선해야하는가?
- 풀이
- 공식: 다수의 프로세서를 사용했을 때 얼마나 빨라지겠는가
- 그러므로, 1.33 배 향상된다.
- 또한, 하드웨어 개선을 통해 2배로 빠르게 계산할 수 없다. 왜냐하면 N이 무한대여도 공식으로 불가능하기 때문이다.
- 따라서 f (수행시간 비율)을 낮춰야한다.
- 공식: 다수의 프로세서를 사용했을 때 얼마나 빨라지겠는가
예제 문제: 암달의 법칙 - 2
- 문제
- 어떤 프로세서 칩이 응용 프로그램을 위해 사용되고 있는데, 이 프로그램의 수행 시간이 30%는 연산A에, 25%는 연산B에, 10%는 연산C에 소요한다.
이 프로세서의 새로운 모델을 위해 설계팀은 세가지의 가능한 향상방식을 고안해 냈는데, 이 각각의 설계 노력과 제조에 거의 같은 비용이 든다.
이들 향상방식 중에 어느 하나를 선택해야 하는가? - 연산A를 2배 빠르게 설계한다.
- 연산B를 3배 빠르게 설계한다.
- 연산C를 10배 빠르게 설계한다.
- 어떤 프로세서 칩이 응용 프로그램을 위해 사용되고 있는데, 이 프로그램의 수행 시간이 30%는 연산A에, 25%는 연산B에, 10%는 연산C에 소요한다.
- 풀이
- 공식: 다수의 프로세서를 사용했을 때 얼마나 빨라지겠는가
- n배 빠르게 = N
- 수행 시간 % = f
- 연산 A를 2배 빠르게 설계한다.
- 즉, 1.17배 향상된다.
- 연산 B를 3배 빠르게 설계한다.
- 즉, 1.2배 향상된다.
- 연산 C를 10배 빠르게 설계한다.
- 즉, 1.09배 향상된다.
- 따라서, 연산B를 3배 빠르게 설계하는 것이 좋다.
- 공식: 다수의 프로세서를 사용했을 때 얼마나 빨라지겠는가
벤치마크
- 기계 성능의 상대적 평가를 위해, 선택되거나 설계된 프로그램
- 특성
- 고급 언어로 작성되며, 서로 다른 기계들에서 호환성을 가져야 한다.
- 특정 종류의 유형에 대표적이어야 한다.
- 쉽게 측정되고 널리 보급될 수 있어야 한다.
- 성결대학교 컴퓨터 공학과 최정열 교수님 (2021)
- William Stalling, 『컴퓨터시스템구조론(10판)』