
- 이전 게시글
JPQL - 기초
개요
JPQL이란?
이전 게시글에서 JPQL이 무엇인지 간략하게 알아보았다. 다시한번 복습해보자.
- JPQL의 특징
- JPQL은 객체지향 쿼리 언어이다.
- 따라서 테이블을 대상으로 쿼리하는 것이 아니라, 엔티티 객체를 대상으로 쿼리한다.
- JPQL은 SQL을 추상화해서 특정 DB SQL에 의존하지 않는다.
- JPQL은 결국 SQL로 변환된다.
- JPQL은 객체지향 쿼리 언어이다.
JPQL 설명을 위한 예시 도메인
JPQL에 대해 설명을 하기 위해, 사용할 예시의 도메인 모델을 알아보자.
-
샘플 모델 UML
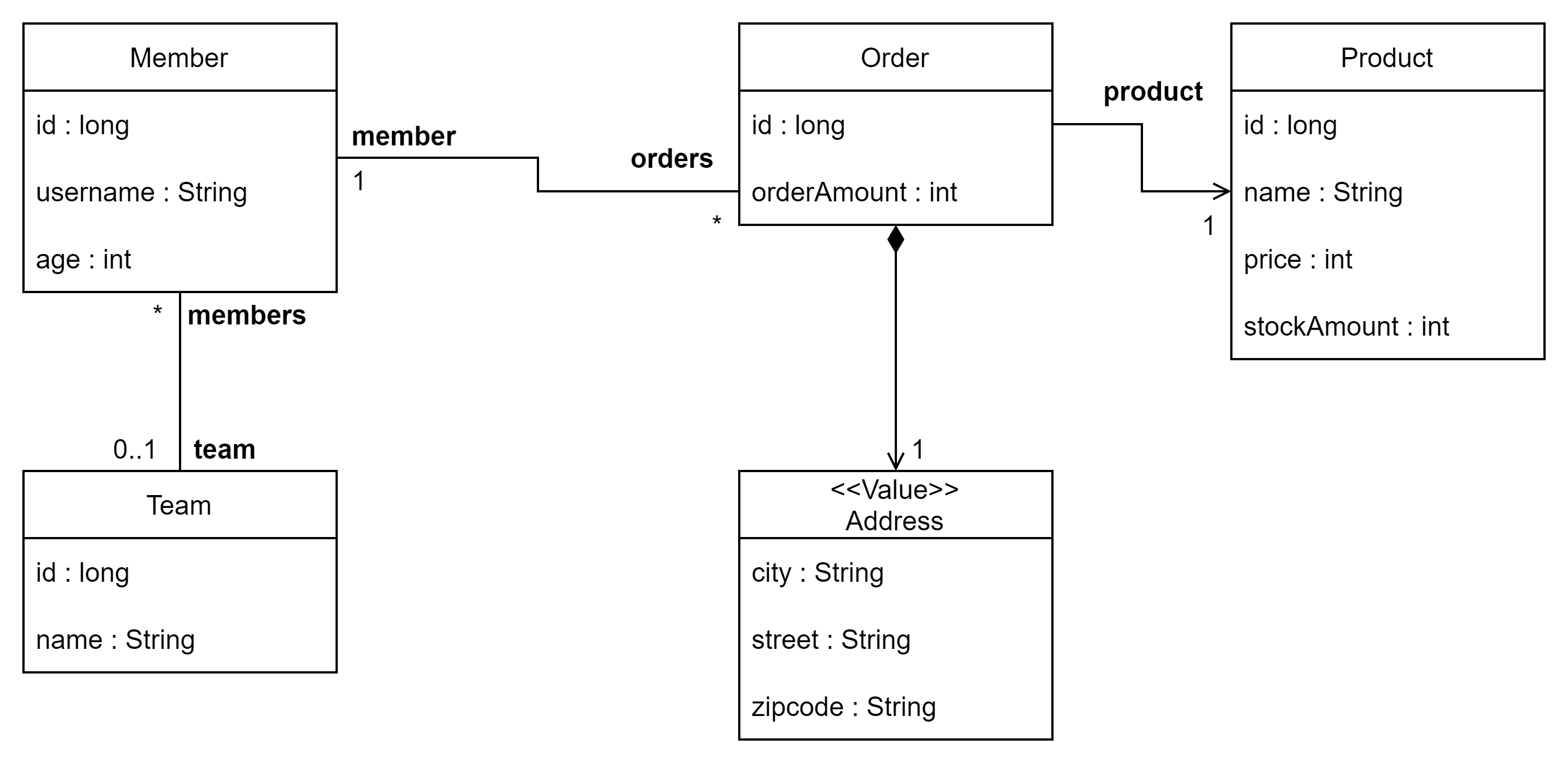
-
샘플 모델 ERD
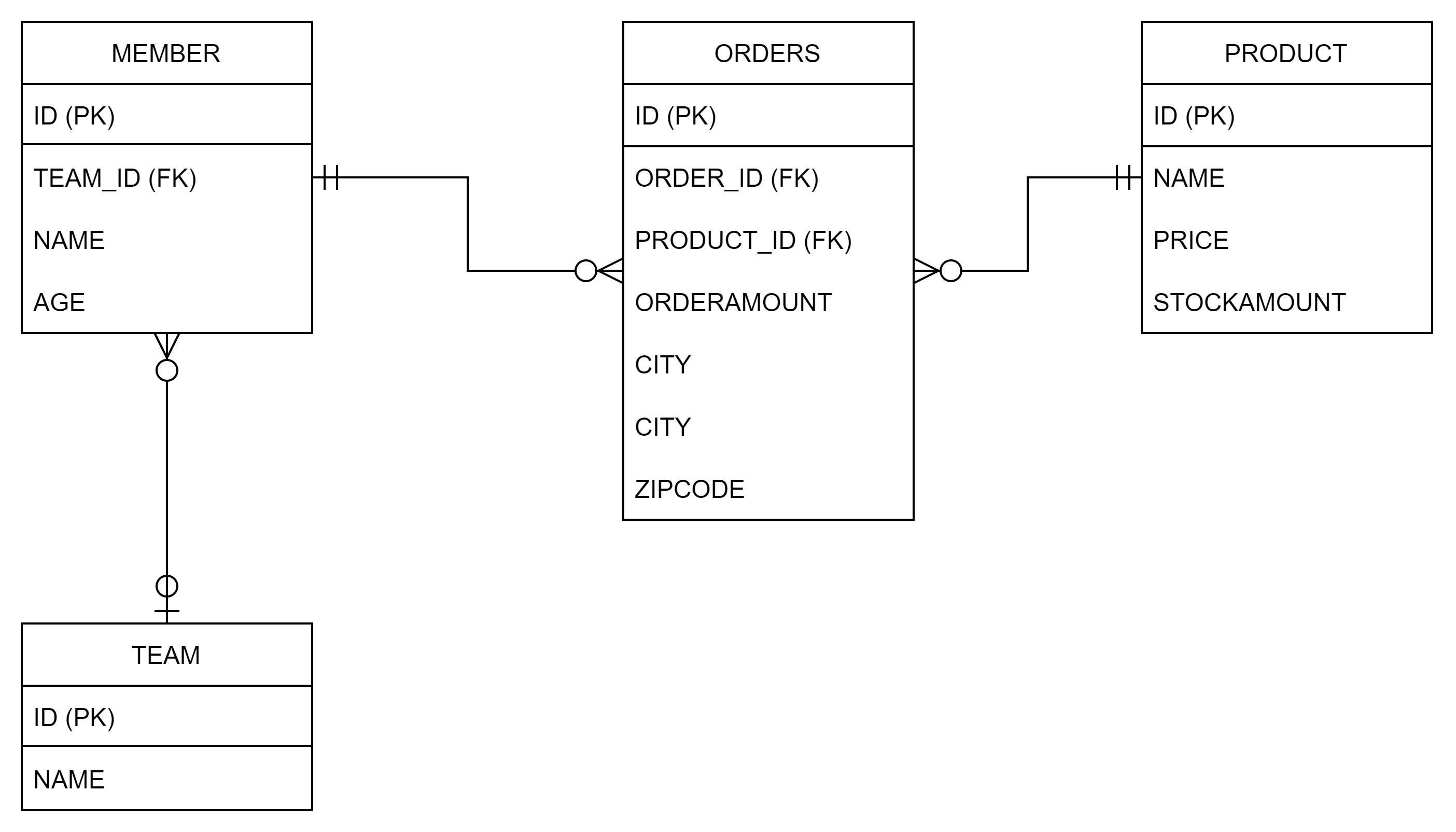
-
특징
- 회원(
Member)가 상품(Product)을 주문하는 것은 다대다 관계이다. Address는 임베디드 타입이다.- 그러므로 UML에서 스테레오 타입을 사용하여
<<Value>>로 정의한다. Address에 해당하는 부분이ORDERS테이블에 포함되어 있다.
- 그러므로 UML에서 스테레오 타입을 사용하여
- 회원(
기본 문법과 쿼리 API
JPQL 기본 문법
JPQL도 SQL과 비슷하게 SELECT, UPDATE, DELETE 문을 사용할 수 있다.
-
JPQL 문법: select 문
select_문 :: = select_절 from_절 [where_절] [groupby_절] [having_절] [orderby_절] -
벌크 연산: UPDATE 문
update_문 :: = update_절 [where_절] -
벌크 연산: delete 문
delete_문 :: = delete_절 [where_절]
벌크연산에 대해서는 추후 포스팅으로 다룬다.
SELECT 문
-
기본 사용법
SELECT m FROM Member AS m WHERE m.username = 'hello' -
상세 설명
- 대소문자 구분
- 엔티티와 속성은 대소문자를 구분한다.
- 예)
Member,username
- 예)
- JPQL 키워드는 대소문자를 구분하지 않는다.
- 예)
SELECT,FROM,AS
- 예)
- 엔티티와 속성은 대소문자를 구분한다.
- 엔티티 이름
- JPQL에서 사용한
Member는 클래스 명이 아니라, 엔티티 명이다. - 엔티티 명 지정
@Entity(name = "엔티티명")으로 지정한다.- 엔티티 명을 지정하지 않으면, 클래스 명을 기본값으로 사용한다.
- 기본값인 클래스 명을 엔티티 명으로 사용하는 것을 권장한다.
- JPQL에서 사용한
- 별칭은 필수
Member AS m을 보면,Member에m이라는 별칭을 주었다.- JPQL은 별칭을 필수로 사용해야 한다.
AS는 생략할 수 있다.
SELECT username FROM Member m //잘못된 문법 SELECT m.username FROM Member m //올바른 문법
하이버네이트는 JPQL 표준과 함께 HQL을 제공한다.
HQL은 JPQL의 확장으로, 더 다양한 기능을 제공한다. - 대소문자 구분
TypedQuery와 Query
- 작성한 JPQL을 실행하려면 쿼리 객체를 만들어야 한다.
- 쿼리 객체의 종류
TypedQuery- 반환할 타입을 명확하게 지정할 수 있을 때 사용한다.
Query- 반환 타입을 명확하게 지정할 수 없을 때 사용한다.
-
TypedQuery사용 예시// 쿼리 객체 생성 TypedQuery<Member> query = em.createQuery("SELECT m FROM Member m", Member.class); // 쿼리 실행 List<Member> resultList = query.getResultList(); // 결과 확인 for (Member member : resultList) { System.out.println("member = " + member); }em.createQuery()- 첫번째 파라미터
- JPQL 문자열을 넘겨준다.
- 두번째 파라미터
- 쿼리의 반환타입을 지정한다.
- 반환타입이 확실하여 해당 파라미터를 채울 수 있다면,
em.createQuery()메서드가TypedQuery를 반환한다. - 조회 대상이
Member엔티티 자체이므로, 조회 대상 타입이 명확하다. ⇒TypedQuery타입으로 쿼리 결과를 받을 수 있다.
- 첫번째 파라미터
-
Query사용 예시// 쿼리 객체 생성 (반환타입이 지정되지 않음) Query<Member> query = em.createQuery("SELECT m.username, m.age FROM Member m"); // 쿼리 실행 List resultList = query.getResultList(); //'Object 배열형인 조회 결과'가 List에 Object형으로 담긴다. // 결과 확인 for (Object o : resultList) { Object[] resultRecord = (Object[]) o; //Object[] 가 Object로 담겨있으므로 System.out.println("username = " + resultRecord[0]); System.out.println("age = " + resultRecord[1]); }em.createQuery()- 첫번째 파라미터
- JPQL 문자열을 넘겨준다.
- 두번째 파라미터
- 반환타입이 확실하지 않아 해당 파라미터를 채울 수 없다면,
em.createQuery()메서드가Query를 반환한다. - 조회 대상이
String형 username과Integer형 age이므로, 조회 대상 타입이 명확하지 않다. ⇒Query타입으로 쿼리 결과를 받을 수 있다.
- 반환타입이 확실하지 않아 해당 파라미터를 채울 수 없다면,
- 첫번째 파라미터
em.createQuery()정리TypedQuery객체를 사용해야 한다면query.getResultList()호출시 ⇒ 설정한 타입으로 하나의 결과 레코드를 담고, 이것을List<설정한 타입>에 각각 담아 반환한다.
List<Member> resultList = query.getResultList(); // List<Member> 의 각 요소는 쿼리결과의 각 Member형 레코드이다.- 조회하고자 하는 대상(필드)가 2개 이상이고,
Query객체를 사용해야 한다면query.getResultList()호출시 ⇒Object[]에 하나의 결과 레코드를 담고, 이것을List<Object>에 각각 담아 반환한다.
Object형에Object[]형 데이터를 담을 수 있다.List resultList = query.getResultList(); List<Object> resultList = query.getResultList(); // 위 두가지 코드 모두 동일하다. // List의 각 요소는 쿼리결과의 각 Object[]형 레코드이다. // Object[]의 각 요소는 하나의 칼럼값을 갖는다. // Object형으로 Object[] 데이터가 담겼다. - 조회하고자 하는 대상(필드)가 1개이고,
Query객체를 사용해야 한다면query.getResultList()호출시 ⇒Object에 하나의 결과(필드)를 담고, 이것을List<Object>에 각각 담아 반환한다.
List resultList = query.getResultList(); List<Object> resultList = query.getResultList(); // 위 두가지 코드 모두 동일하다. // List의 각 요소는 쿼리결과의 각 Object형 레코드이다.
- 타입을 변환할 필요가 없는
TypedQuery를 사용하는 것이 더 편리하다.
결과 조회
아래 메서드들을 호출하면, 실제 쿼리를 실행해서 DB를 조회한다.
query.getResultList()- 결과를 예제로 반환한다.
- 만약 결과가 없으면, 빈 컬렉션을 반환한다.
query.getSingleResult()- 결과가 정확히 하나일 때 사용한다.
- 결과가 없으면:
javax.persistence.NoResultException예외가 발생한다. - 결과가 1개보다 많으면:
javax.persistence.NonUniqueResultException예외가 발생한다.
Member member = query.getSingleResult();즉,
getSingleResult()는 결과가 정확히 1개가 아니면, 예외가 발생한다는 점에 주의하자!
파라미터 바인딩
JPQL에서 제공하는 파라미터 바인딩
- JDBC 에서 제공하는 파라미터 바인딩
- 오직 위치 기준 파라미터 바인딩만 지원한다.
- JPQL 에서 제공하는 파라미터 바인딩
- 위치 기준 파라미터 바인딩 (
?를 사용한다.) - 이름 기준 파라미터 바인딩 (
:를 사용한다.) - 위 두가지 모두 지원한다.
- 위치 기준 파라미터 바인딩 (
파라미터 바인딩 예시: 이름 기준 파라미터 바인딩
String usernameParam = "User1";
// ':username'으로 바인딩 기준 정의
TypedQuery<Member> query = em.createQuery(
"SELECT m FROM Member m WHERE m.username = :username",
Member.class);
//이름 기준 파라미터 바인딩 적용
query.setParemeter("username", usernameParam);
// 완성된 쿼리:
// SELECT m FROM Member m WHERE m.username = User1
List<Member> resultList = query.getResultList();
:username이라는 이름 기준 파라미터를 정의했다.query.setParameter()에서username이라는 이름을 갖는 위치에 파라미터를 바인딩했다.-
메서드 체이닝을 지원하여 아래와 같이 작성할수도 있다.
List<Member> resultList = em.createQuery( "SELECT m FROM Member m WHERE m.username = :username", Member.class) .setParameter("username", usernameParam) .getResultList();
파라미터 바인딩 예시: 위치 기준 파라미터 바인딩
String usernameParam = "User1";
// '?1'으로 바인딩 기준 정의
//위치 기준 파라미터 바인딩 적용 및 실행
List<Member> resultList = em.createQuery(
"SELECT m FROM Member m WHERE m.username = ?1",
Member.class)
.setParameter(1, usernameParam)
.getResultList();
// 완성된 쿼리:
// SELECT m FROM Member m WHERE m.username = User1
- ‘위치 기준 파라미터 바인딩 방식’보단, ‘이름 기준 파라미터 바인딩 방식’을 사용하는 것이 더 명확하다.
참고사항: 왜 파라미터 바인딩 방식을 사용해야 하는가?
-
사실 파라미터 바인딩을 사용하지 않고, 다음과 같이 JPQL을 작성할 수 있다.
String usernameParam = "User1"; TypedQuery<Member> query = em.createQuery( "SELECT m FROM Member m WHERE m.username = " + usernameParam, Member.class); - 하지만 위 방식보단, 파라미터 바인딩 방식으로 JPQL을 작성하는 것이 권장된다.
- 파라미터 바인딩 사용 이유
- 위 코드처럼 직접 문자를 더해 만들어 넣으면, 악의적인 사용자에 의해 SQL 인젝션 공격을 당할 수 있다.
- SQL 인젝션 공격?
- 대략 아래와 같은 상황을 말한다.

SQL 인젝션 공격에 대한 자세한 것은 따로 다루진 않는다.
- SQL 인젝션 공격을 방지하기 위한 것 이외에, 성능 이슈도 존재한다.
- 파라미터 바인딩 방식을 사용하면, 파라미터의 값이 달라도 같은 쿼리로 인식해서 JPA는 JPQL을 SQL로 파싱한 결과를 재사용할 수 있다.
프로젝션
프로젝션이란?
- SELECT 절에 조회할 대상을 지정하는 것을 프로젝션이라고 한다.
SELECT {프로젝션 대상} FROM
- 프로젝션 대상
- 엔티티
- 임베디드 타입
- 스칼라 타입
- 숫자, 문자 등의 기본 데이터 타입
이제 프로젝션에 대해 하나씩 알아보자.
엔티티 프로젝션
SELECT m FROM Member m //회원 엔티티 조회
SELECT m.team FROM Member m //팀 엔티티 조회
- 둘 다 엔티티를 프로젝션 대상으로 사용했다.
- 참고: 조회한 연관 엔티티는 영속성 컨텍스트에서 관리된다.
임베디드 타입 프로젝션
-
임베디드 타입은 조회의 시작점이 될 수 없다.
String query = "SELECT a FROM Address a";- 포스팅 글 초반에 설명한 예시 도메인을 참고하면,
Address는 임베디드 타입이다. - 임베디드 타입은 조회의 시작점이 될 수 없으므로, 위와 같은 JPQL 쿼리는 잘못된 쿼리이다.
- 따라서 아래와 같이 수정해야 한다.
String query = "SELECT o.address FROM Order o";- 위 코드에선
Order엔티티가 조회의 시작점이므로, 올바른 JPQL 쿼리이다.
- 포스팅 글 초반에 설명한 예시 도메인을 참고하면,
-
임베디드 타입은 ‘엔티티 타입’이 아닌 ‘값 타입’이다.
- 따라서 이렇게 직접 조회한 임베디드 타입은 영속성 컨텍스트에서 관리되지 않는다.
- 임베디드 타입에 대한 자세한 내용은 이전 포스팅을 참고하자.
스칼라 타입 프로젝션
- 숫자나 문자, 날짜와 같은 기본 데이터 타입들을 스칼라 타입이라고 한다.
-
스칼라 타입 조회
List<String> resultList = em.createQuery( "SELECT m.username FROM Member m", String.class) .getResultList(); -
중복 데이터 없이 스칼라 타입 조회
List<String> resultList = em.createQuery( "SELECT DISTINCT m.username FROM Member m", String.class) .getResultList();
여러 값 조회
- 프로젝션에 여러 값을 선택하면,
TypedQuery를 사용할 수 없고 대신Query를 사용해야 한다. -
예시 코드
Query<Member> query = em.createQuery("SELECT m.username, m.age FROM Member m"); List resultList = query.getResultList(); // List<Object> 결과 확인 Iterator iterator = resultList.iterator(); while (iterator.hasNext()) { Object[] resultRecord = (Object[]) iterator.next(); String username = (String) resultRecord[0]; Integer age = (Integer) resultRecord[1]; System.out.println("username = " + username + "age = " + age); }- 위 방식으로 결과 리스트를 확인하는 것은 번거롭다.
- 아래 방식을 사용해보자.
-
제네릭을 사용하여 보다 간결한 코드
Query<Member> query = em.createQuery("SELECT m.username, m.age FROM Member m"); //제네릭으로 요소 타입 지정 List<Object[]> resultList = query.getResultList(); // List<Object[]> 결과 확인 for (Object[] resultRecord : resultList) { String username = (String) resultRecord[0]; Integer age = (Integer) resultRecord[1]; System.out.println("username = " + username + "age = " + age); }
- 스칼라 타입뿐만 아니라, 엔티티 타입도 여러 값을 함께 조회할 수 있다. 아래 코드를 보자.
Query<Member> query = em.createQuery(
"SELECT o.member, o.product, o.orderAmount FROM Order o");
List<Object[]> resultList = query.getResultList();
// List<Object[]> 결과 확인
for (Object[] resultRecord : resultList) {
Member member = (Member) resultRecord[0]; // 엔티티
Product product = (Product) resultRecord[1]; // 엔티티
int orderAmount = (Integer) resultRecord[2]; // 스칼라
}
- 물론 이때도 조회한 엔티티는 영속성 컨텍스트에서 관리된다.
NEW 명령어
- 지금까지 여러 필드를 조회할 때, 타입을 명확히 지정할 수 없으므로
Query를 사용하여Object[]를 반환받았다. - 실제로 애플리케이션을 개발할 때는
Object[]를 직접 사용하지 않고, DTO 클래스와 같이 의미있는 객체로 변환해서 사용할 것이다.
- DTO 클래스 사용 예시
-
UserDTO 클래스
public class UserDTO { private String username; private int age; public UserDTO(String username, int age) { this.username = username; this.age = age; } //getter, setter 생략 } -
DTO를 사용하는 JPQL 조회:
NEW명령어 없이List<Object[]> resultList = em.createQuery("SELECT m.username, m.age FROM Member m") .getResultList(); // 번거로운 DTO 변환 작업 List<UserDTO> userDTOs = new ArrayList<UserDTO>(); for (Object[] resultRecord : resultList) { String username = (String) resultRecord[0]; Integer age = (Integer) resultRecord[1]; userDTOs.add(new UserDTO(username, age)); } return userDTOs;- 위와 같은 DTO 변환 작업은 너무 번거롭다.
- 이때, JPQL 쿼리에
NEW명령어를 사용하면 편리하다.
-
DTO를 사용하는 JPQL 조회:
NEW명령어 사용//new 명령어가 적용된 새 JPQL 쿼리 List<UserDTO> userDTOs = em.createQuery( "SELECT NEW 패키지경로.UserDTO(m.username, m.age) FROM Member m" UserDTO.class) .getResultList(); // 번거로운 DTO 변환 작업은 필요없다. return userDTOs;SELECT다음에NEW명령어를 사용하여 반환받을 클래스를 지정할 수 있다.- 반환받을 클래스의 생성자에 JPQL 조회 결과를 넘겨줄 수 있다.
NEW명령어를 사용한 클래스로TypedQuery를 사용할 수 있어서 간편하다.
-
NEW명령어 사용 시, 주의사항- 패키지 명을 포함한 전체 클래스 명을 입력해야 한다.
- 순서와 타입이 일치하는 생성자가 필요하다.
페이징 API
JPA가 제공하는 페이징 API
JPA는 페이징을 아래 두 API로 추상화했다.
setFirstResult(int startPosition)- 조회 시작 위치 (0부터 시작한다.)
setMaxResults(int maxResult)- 조회할 데이터 수
예시 코드
TypedQuery<Member> query = em.createQuery(
"SELECT m FROM Member m ORDER BY m.username DESC",
Member.class);
query.setFirstResult(10); // 11번째 레코드부터
query.setMaxResults(20); // 총 20개의 레코드까지
query.getResultList();
setFirstResult(10)- 11번째 레코드부터
setMaxResults(20)- 20개의 레코드를 조회한다.
- 즉 11~20 번째 레코드를 조회한다.
- DB마다 다른 페이징 처리를 같은 API로 처리할 수 있는 이유
- 데이터베이스 방언(Dialect) 기능 덕분에 가능하다.
집합과 정렬
집합이란?
- 집합함수와 함께 통계 정보를 구할 때 사용한다.
-
예시 JPQL 쿼리
select COUNT(m), //회원수 SUM(m.age), //나이 합 AVG(m.age), //나이 평균 MAX(m.age), //최대 나이 MIN(m.age) //최소 나이 from Member m
집합 함수
| 함수 | 설명 | 반환타입 |
|---|---|---|
| COUNT | 결과 수를 구한다. | Long |
| MAX, MIN | 최대, 최소 값을 구한다. | 문자, 숫자, 날짜 등 |
| AVG | 평균값을 구한다. 숫자타입만 사용할 수 있다. |
Double |
| SUM | 합을 구한다. 숫자타입만 사용할 수 있다. |
정수합: Long 소수합: Double BigInteger합: BigInteger BigDecimal합: BigDecimal |
집합 함수 사용 시 참고사항
NULL값은 무시하므로 통계에 잡히지 않는다.- 만약 값이 없는데
SUM,AVG,MAX,MIN함수를 사용하면NULL값이 된다.- 단,
COUNT는 0이 된다.
- 단,
DISTINCT를 집합 함수 안에 사용해서 중복된 값을 제거한 뒤의 집합을 구할 수 있다.select COUNT ( DISTINCT m.age ) from Member m
DISTINCT를COUNT에서 사용할 때, 임베디드 타입은 지원하지 않는다.
GROUP BY, HAVING
GROUP BY는 통계 데이터를 구할 때, 특정 그룹까지 묶어준다.- 예시
- 아래 JPQL 쿼리는 ‘팀 이름을 기준으로 묶어, 통계 데이터를 구하는 쿼리’이다.
select t.name, COUNT(m.age), SUM(m.age), AVG(m.age), MAX(m.age), MIN(m.age) from Member m LEFT JOIN m.team t GROUP BY t.name
HAVING은GROUP BY와 함께 사용되어,GROUP BY로 그룹화한 통계 데이터를 기준으로 필터링한다.- 예시
- 아래 JPQL 쿼리는 ‘위 쿼리의 결과 데이터 중에서 평균나이가 10살 이상인 그룹을 조회하는 쿼리’이다.
select t.name, COUNT(m.age), SUM(m.age), AVG(m.age), MAX(m.age), MIN(m.age) from Member m LEFT JOIN m.team t GROUP BY t.name HAVING AVG(m.age) >= 10 -
GROUP BY와HAVING문법groupby_절 ::= GROUP BY {단일값 경로 | 별칭} + having_절 ::= HAVING 조건식
- 통계 쿼리 사용 시, 주의사항
- 통계 쿼리는 보통 전체 데이터를 기준으로 처리하므로, 실시간으로 사용하기엔 부담이 많다.
- 따라서 결과가 아주 많다면 통계 결과만 저장하는 테이블을 별도로 만들어 두고 사용자가 적은 새벽에 통계 쿼리를 실행해서 그 결과를 보관하는 것이 좋다.
정렬(ORDER BY)
ORDER BY는 결과를 정렬할 때 사용한다.- 예시 JPQL 쿼리
- 아래 JPQL 쿼리는 ‘나이를 기준으로 내림차순으로 정렬하고 나이가 같으면 이름을 기준으로 오름차순으로 정렬하는 쿼리’이다.
select m from Member m ORDER BY m.age DESC, m.username ASC -
ORDER BY문법orderby_절 ::= ORDER BY {상태필드 경로 | 결과 변수 [ASC | DESC]}+- 상태필드:
t.name과 같이, 객체의 상태를 나타내는 필드 - 결과 변수: SELECT 절에 나타나는 값
- 상태필드:
- 김영한, 『자바 ORM 표준 JPA 프로그래밍』, 에이콘