
개요
현재 진행중인 프로젝트 현지야는 장소 정보를 얻어오기 위해, 카카오 장소 검색 API를 사용한다.
이 API를 통해서, 기본적인 POI 정보들을 가져올 수 있었지만… 영업시간, 메뉴와 같은 정보들을 제공해주지 않았다.
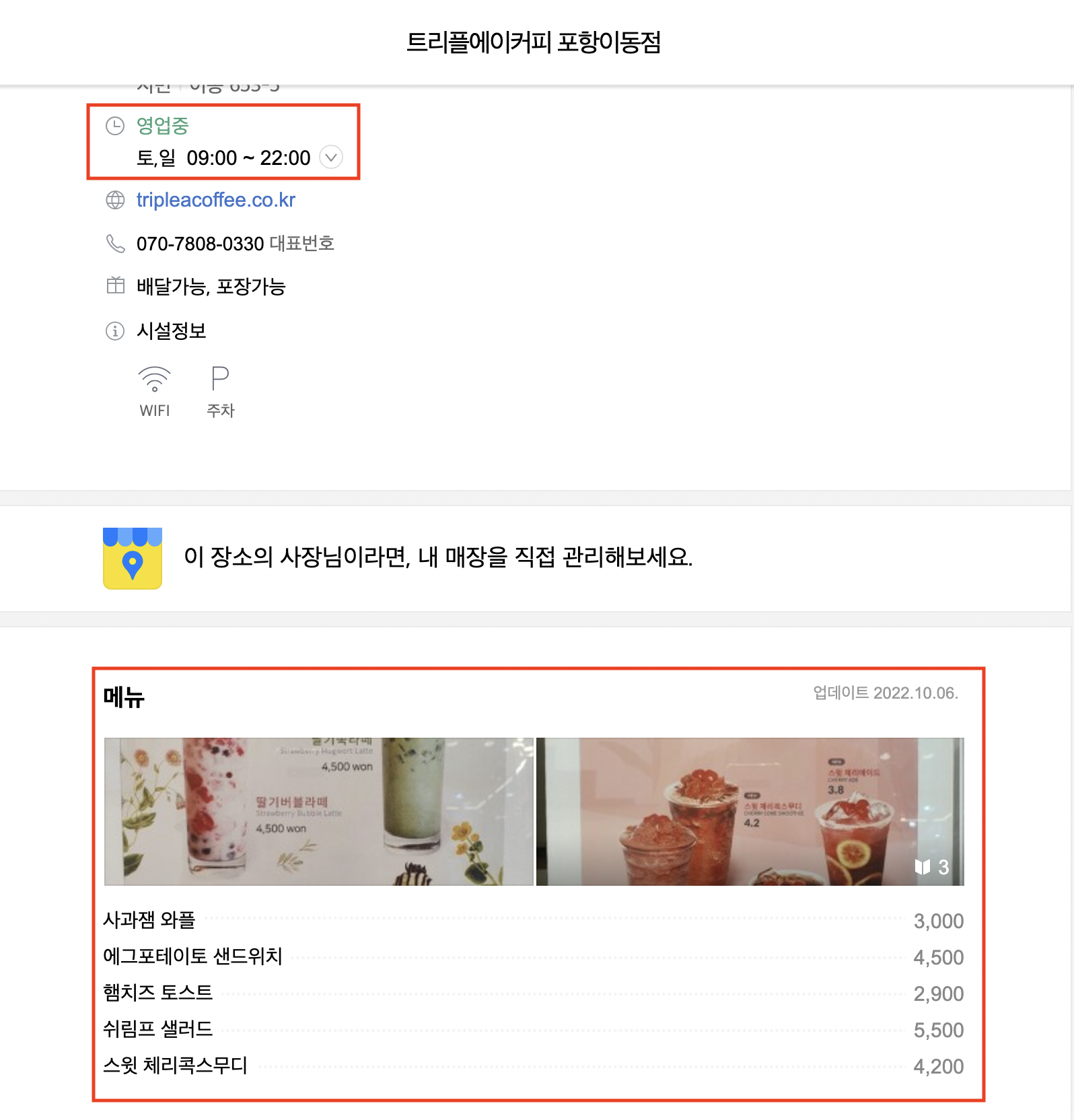
우리 서비스에서 필요한 정보 중 하나는 위 빨간색 영역에 해당하는 데이터이다.
그래서 결국 직접 크롤링을 하여, 이 데이터들을 가져오기로 결정했다.
Selenium 과 Spring Boot 를 활용해서, 특정 장소에 대한 ID 값을 요청받으면 해당 장소의 영업시간과 메뉴 정보를 응답하는 서버를 구축했다.
이번 포스팅에서는 크롤링 서버를 구축하며 겪은 문제들에 대해 정리하고자 한다.
관련 프로젝트는 아래를 참고하면 된다.

요구사항
나는 아래와 같이 동작하는 서버를 구현하고자 했다.
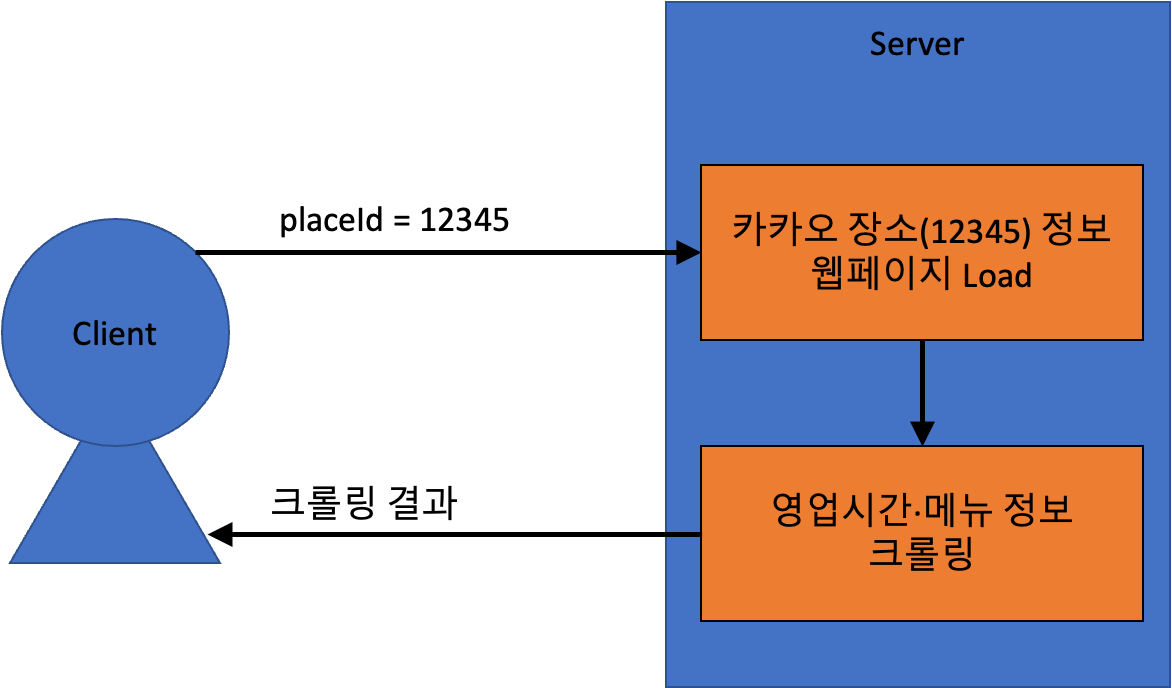
구조는 매우 간단해보인다!
단순히 Selenium SDK 만 잘 활용하면 될 줄 알았는데… 전혀 그렇지 않았다.
지금부터 내가 겪은 문제들를 하나씩 알아보자.
Selenium WebDriver 는 Thread-Safe 하지 않다.
Selenium 을 사용해서 웹브라우저를 동작시키려면 WebDriver 를 사용해야 한다.
WebDriver 가 뭐지?
WebDriver 에 대한 정의는 다음과 같다.
Selenium WebDriver는 웹 애플리케이션 테스트를 자동화하는 데 사용되는 오픈 소스 API 모음이다.
https://www.selenium.dev/documentation/legacy/selenium_2/faq/#q-what-is-webdriver
이 정의만으로는 잘 와닿지 않지만, 웹브라우저를 통해 로드한 웹페이지를 Selenium 으로 조작할 수 있게 해주는 도구 정도로 해석하면 될 것 같다.
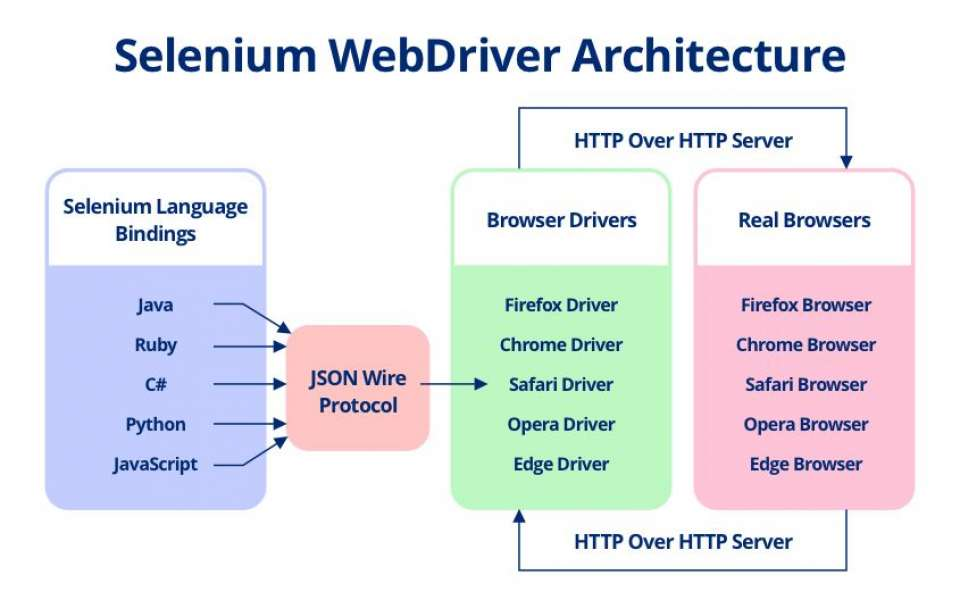
위 그림처럼, Selenium API가 담긴 SDK 와 웹브라우저사이의 중간 다리 역할을 한다고 볼 수 있다.
Thread-Safe 하지 않은 WebDriver
그리고 이 WebDriver 는 Tread-Safe 하지 않게 동작한다.
https://www.selenium.dev/documentation/legacy/selenium_2/faq/#q-is-webdriver-thread-safe
그래서 하나의 WebDriver 를 서버에 들어온 요청마다 사용하면 문제가 발생한다!
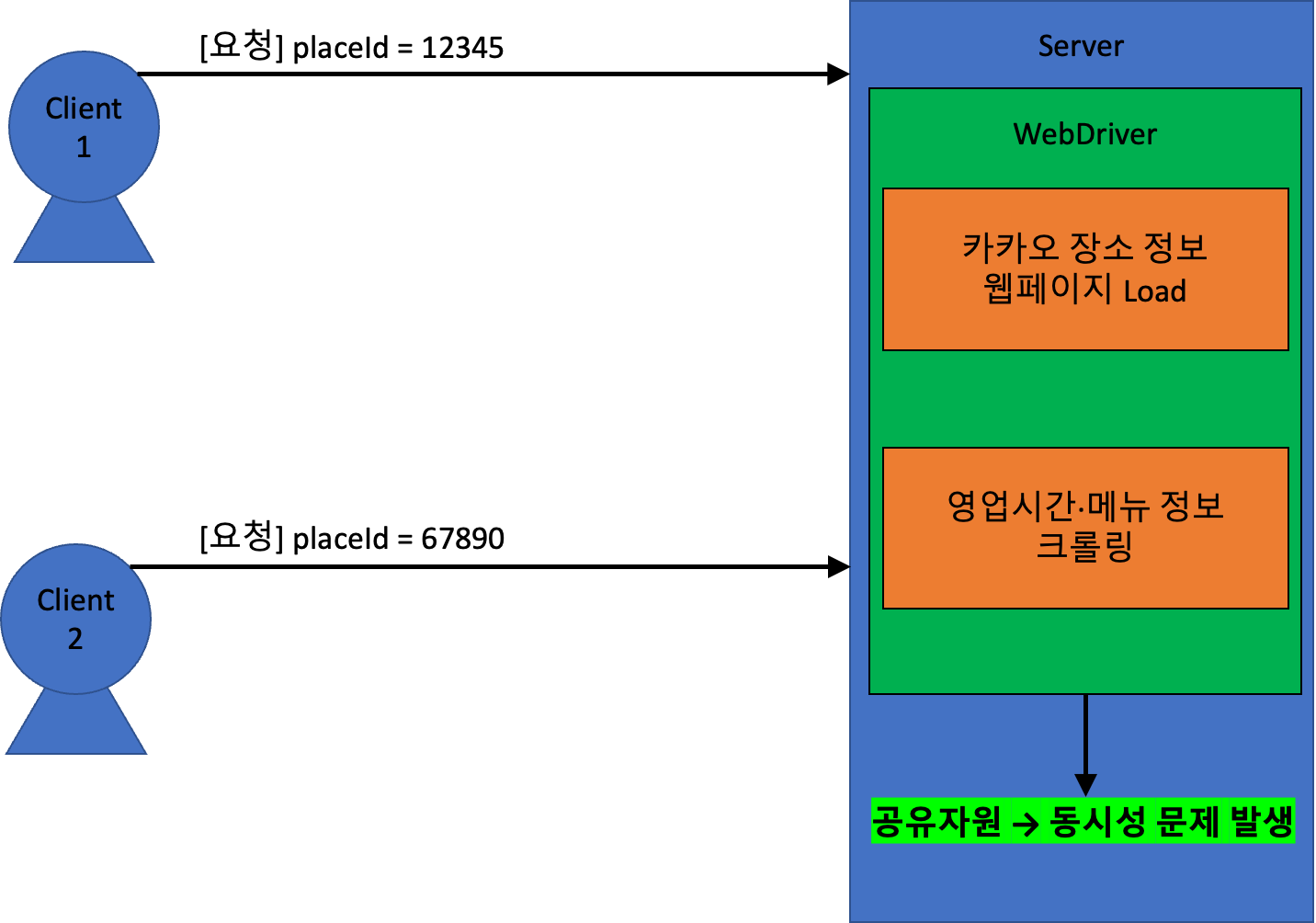
만약 WebDriver 를 서버에서 오직 하나만 사용한다면, WebDriver 를 하나의 공유자원으로 볼 수 있다.
그리고 이것으로 여러 요청(쓰레드)를 처리한다면 동시성 문제가 발생한다.
예를 든다면, 아래와 같은 상황이 발생할 수 있다.
[요청] placeId = 12345이 요청됨.placeId = 12345: 카카오 장소 정보 웹페이지 LoadplaceId = 12345: 영업시간·메뉴 정보 크롤링 중…[요청] placeId = 67890이 요청됨.placeId = 67890: 카카오 장소 정보 웹페이지 LoadplaceId = 67890:placeId = 12345의 크롤링 작업이 중단되고,placeId = 67890에 대한 영업시간·메뉴 정보 크롤링placeId = 67890: 크롤링 완료 →placeId = 67890에 대한 결과 반환placeId = 12345: 크롤링 완료 →placeId = 67890에 대한 잘못된 결과 반환
그럼 어떻게 해결해야할까?
정답은 바로 각 요청, 즉 쓰레드마다 새로운 WebDriver를 사용하도록 하는 것이다.
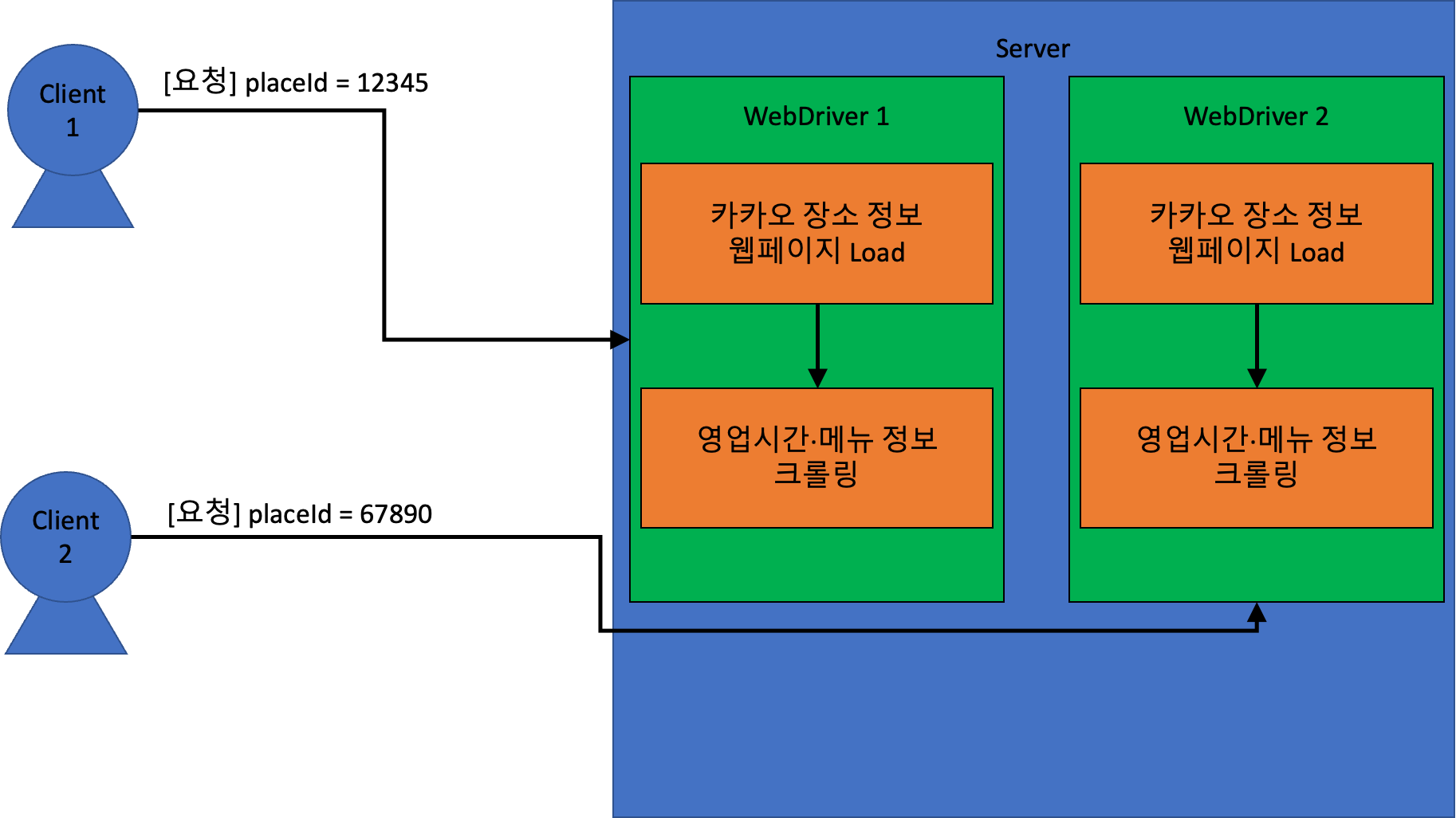
위와 같이, 요청 별로 사용하는 WebDriver와 WebBrowser 가 다르다면 문제가 되지 않는다.
따라서 나도 위와 같이 각 요청마다 새로운 WebDriver와 WebBrowser 를 생성하여 사용하도록 하였고, 이제 모든 문제가 해결이 된 것 같았다!
하지만 또 다른 문제가 발생하였으니…
WebDriver 와 WebBrowser 는 자원 포식자이다.
WebDriver 와 WebBrowser 는 컴퓨팅 자원을 많이 잡아먹는다.
그래서 나의 방식은 한계점이 분명했다.
무한히 실행되는 WebDriver
만약 동시 요청이 100개가 들어온다면…? 100개의 WebDriver와 WebBrowser 를 실행해야 하는데, 이를 감당할 수 있을까…?
실제로 테스팅을 위해, 10개의 동시요청을 보내봤다. (새로고침 연타!!!)
그 결과, 노트북의 CPU 사용량이 99% 를 찍었고 메모리도 상당히 많이 점유되었다.
나름 M1 Pro 칩인데…
만약 상대적으로 컴퓨터 사양이 낮은 서버에 올리면, 동시 요청 6건 정도만 들어와도 서버가 터질 수 있다.
따라서 동시에 실행할 WebDriver 의 개수를 제한해야했다.
너무 오래걸리는 크롤링
또다른 문제는, 한번의 크롤링 요청을 처리하는데 너무 오래 걸린다는 것이다.
한번 크롤링을 처리하는데 수행하는 작업은 아래와 같다.
- 요청이 들어옴.
- 새로운 WebDriver 실행
- 웹페이지 Load
- 크롤링 작업
- 크롤링 결과 응답
처리 시간을 단축하려면, 이 과정을 조금이라도 단순화해야했다.
가장 생략하기 쉬운 작업은 바로 새로운 WebDriver 실행 이다.
어?! 그렇다면…? 정답은 쓰레드풀!
동시 실행할 WebDriver 의 최대 개수를 제한하고, 새로운 WebDriver 를 요청마다 실행하지 않아도 되는 방법이 필요하다.
자, 무엇이 생각나는가?!
그렇다!! 바로 쓰레드 풀!!!
나는 쓰레드 풀 방식에서 영감을 얻어, 아래와 같이 수정을 했다.
- 기존 방식 : 요청마다 새로운 WebDriver를 실행하여 작업한다.
- 새 방식 : Application 을 시작할 때 5개의 WebDriver 를 미리 실행해두고, 들어온 요청마다 유휴상태의 WebDriver 를 찾아 작업한다.
이것을 구조도로 나타내면 아래와 같다.
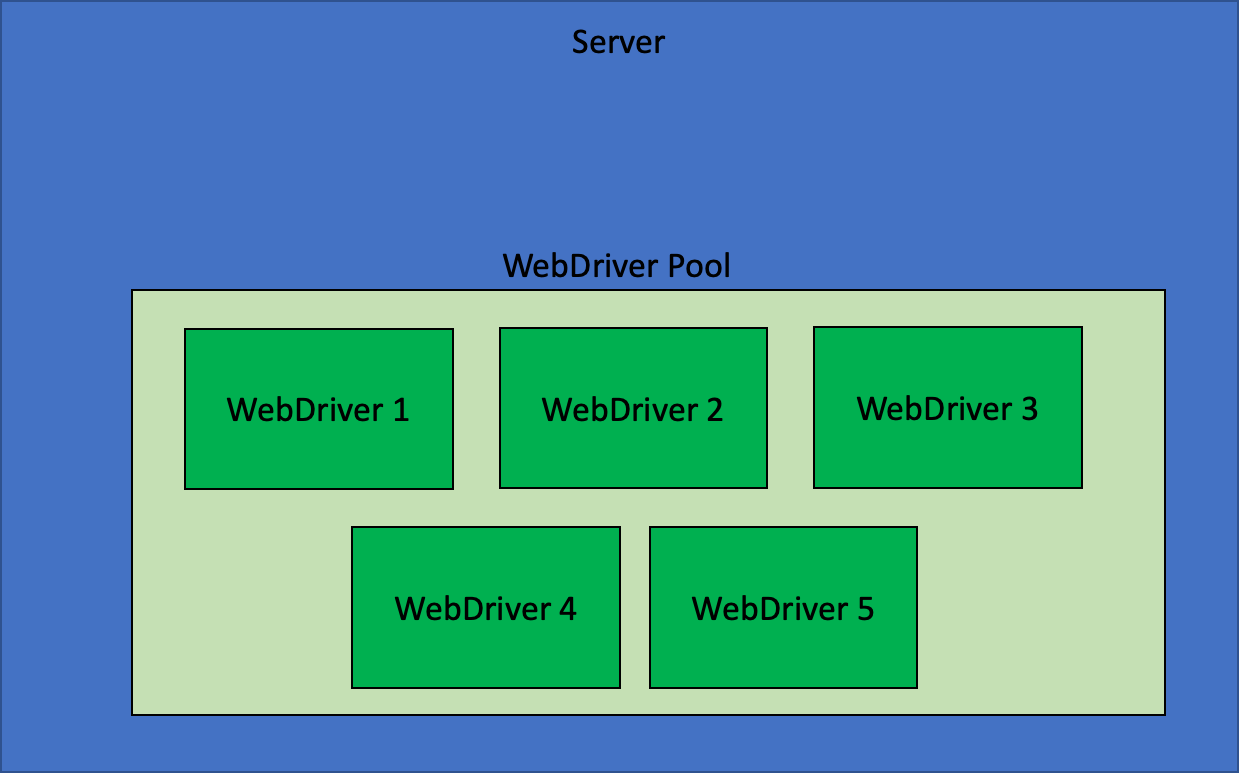
서버 앱이 시작되면 위와 같이 5개의 WebDriver 가 미리 실행된다.
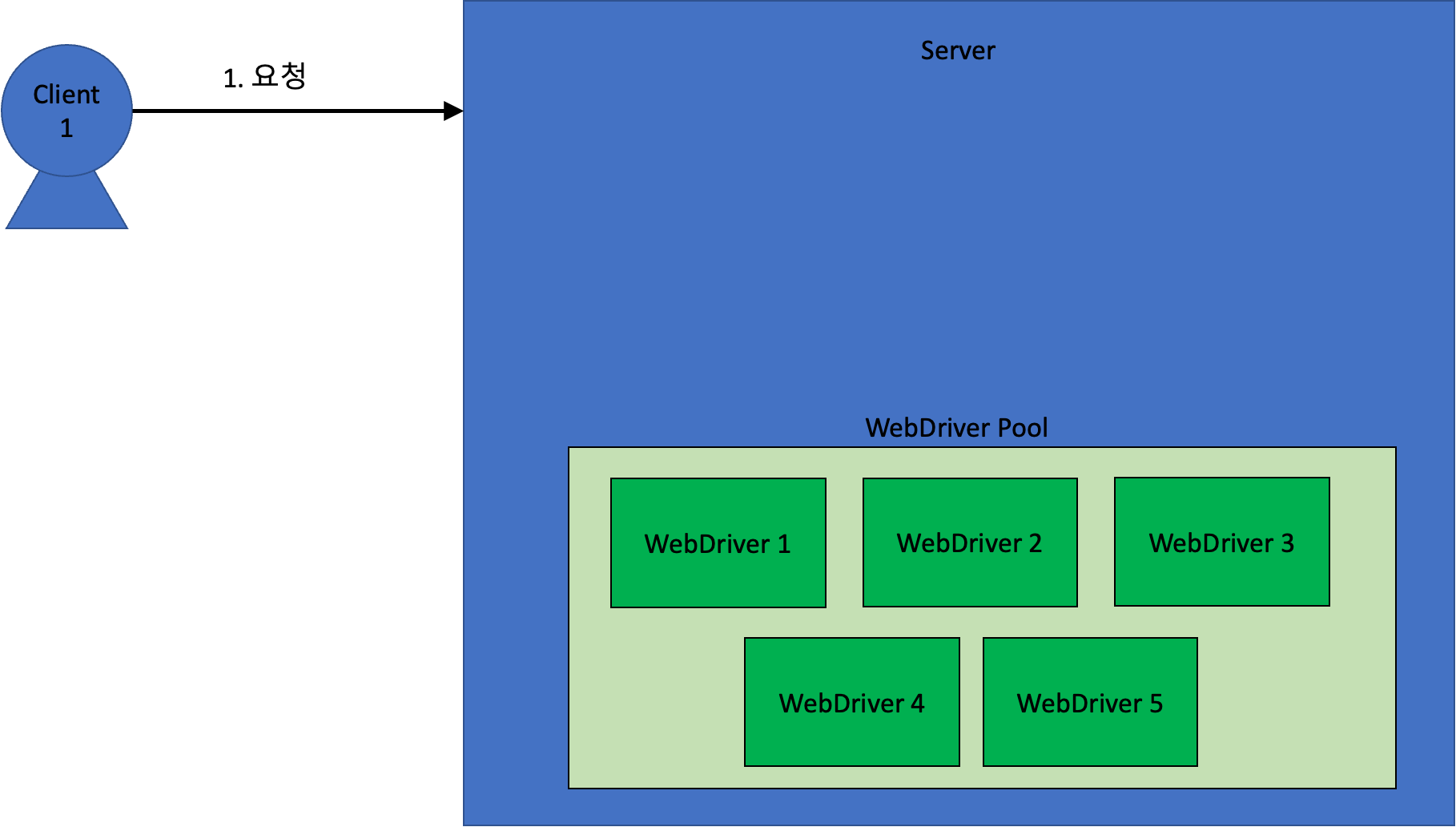
동시 요청이 들어왔을 때, 어떻게 처리되는지 알아보자!
서버에 요청이 들어오고 나면, 아래와 같이 유휴상태의 WebDriver 를 가져와 크롤링 작업을 수행한다.
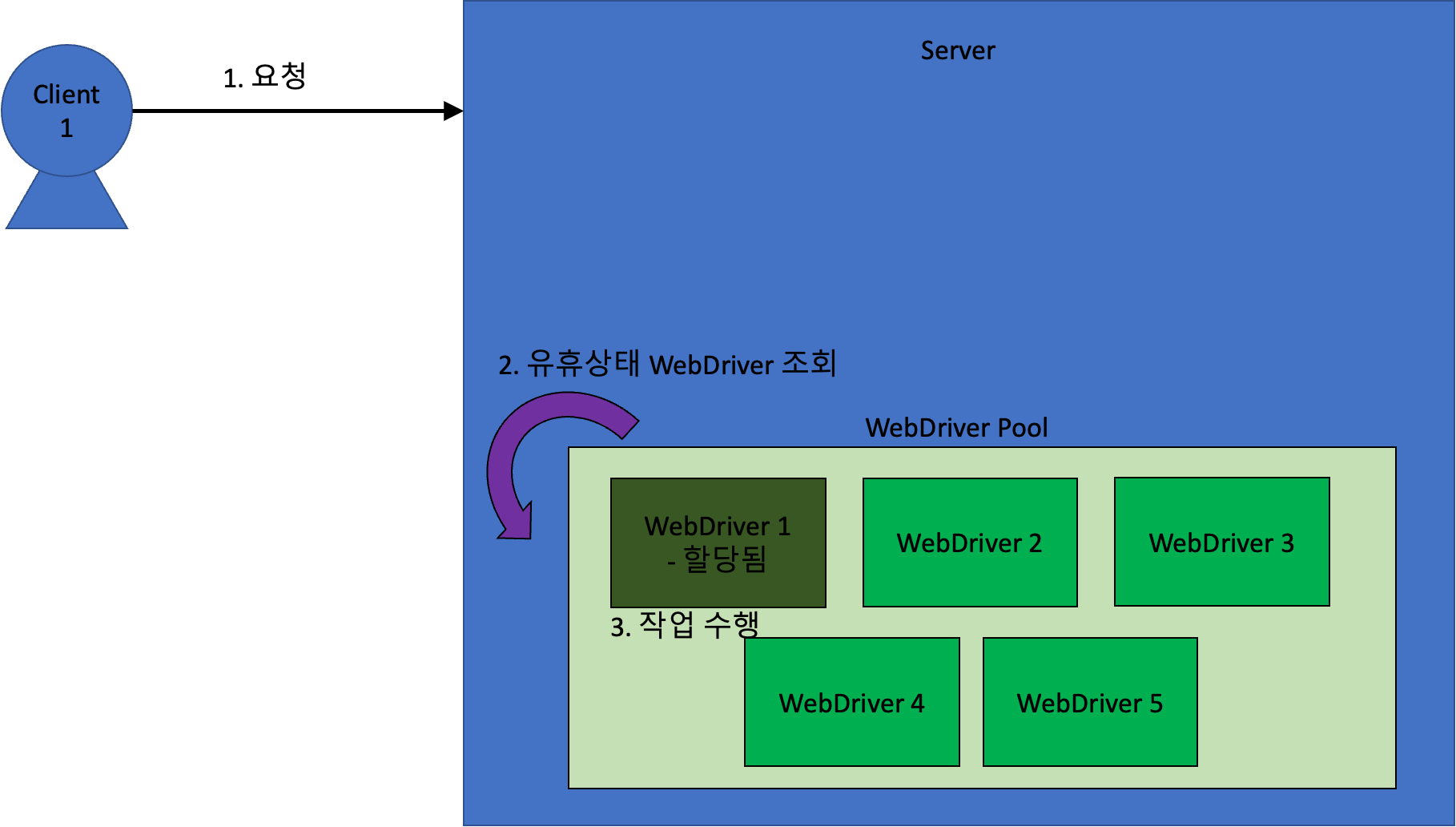
도중에 새로운 요청이 들어오면 아래와 같이 동작한다.
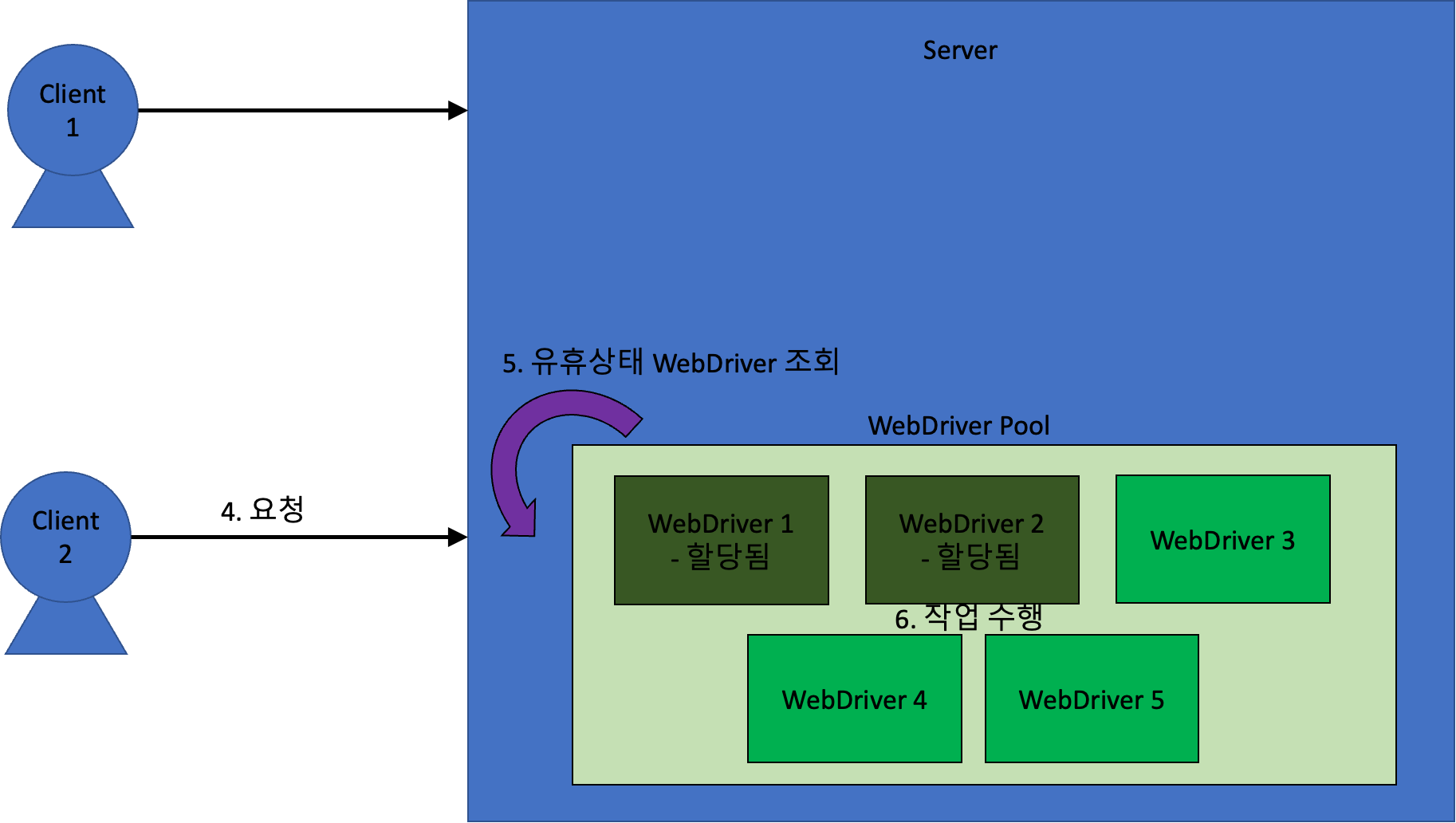
만약 유휴 상태인 WebDriver가 없는 상태에서 새로운 요청이 들어오면, 그 요청은 유휴상태 WebDriver 가 생길 때까지 대기하게 된다.
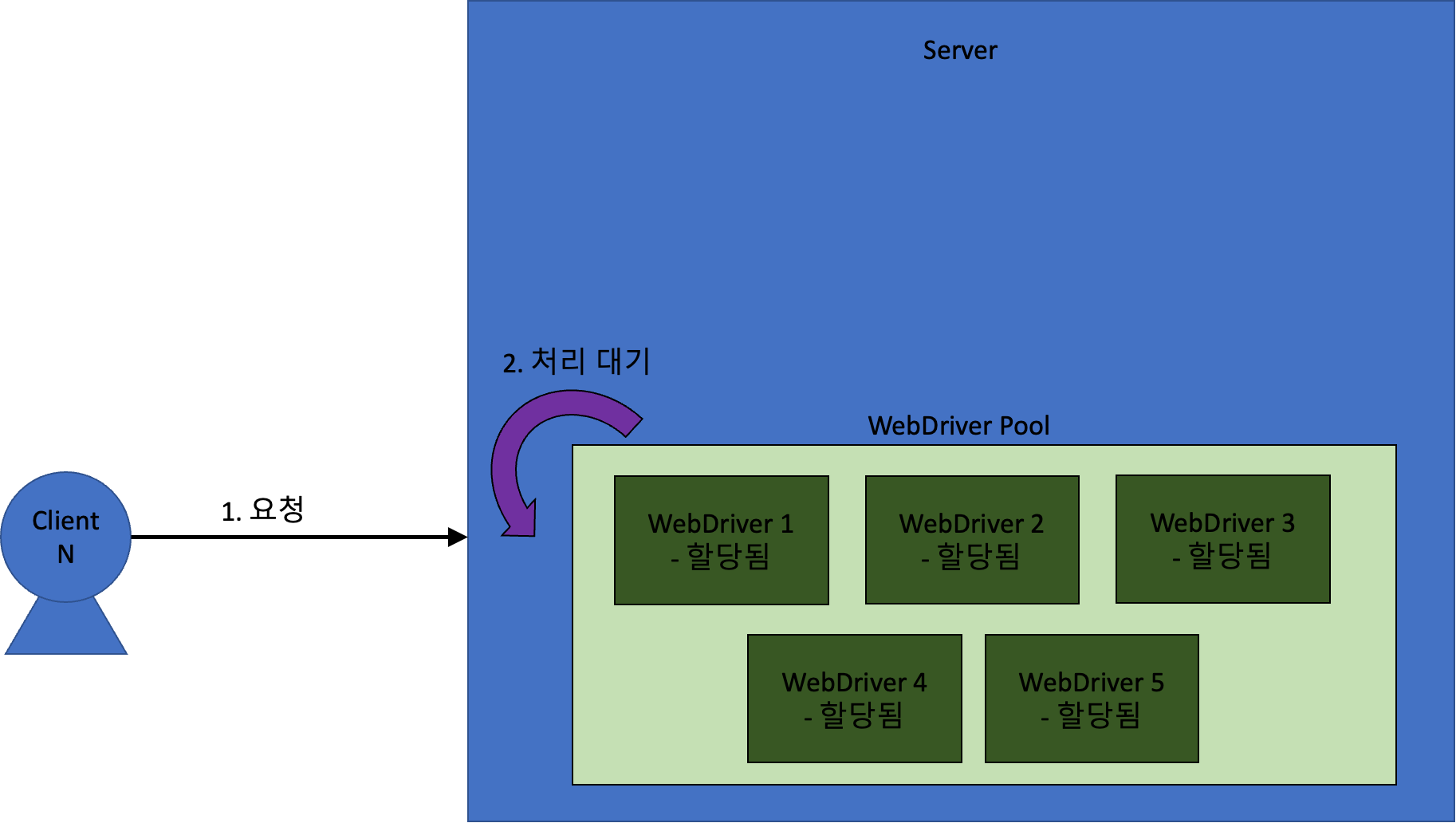
이렇게 쓰레드 풀 방식을 채택해서, 안정성과 속도 모두를 잡았다!!
캐시 적용
이렇게 동시성 문제를 해결하고, 성능과 안정성을 챙겼다.
그리고 크롤링한 장소의 정보를 모두 캐싱하여, 동일한 요청이 또 들어왔을 때 보다 빠르게 응답할 수 있게 하였다.
캐싱 방식
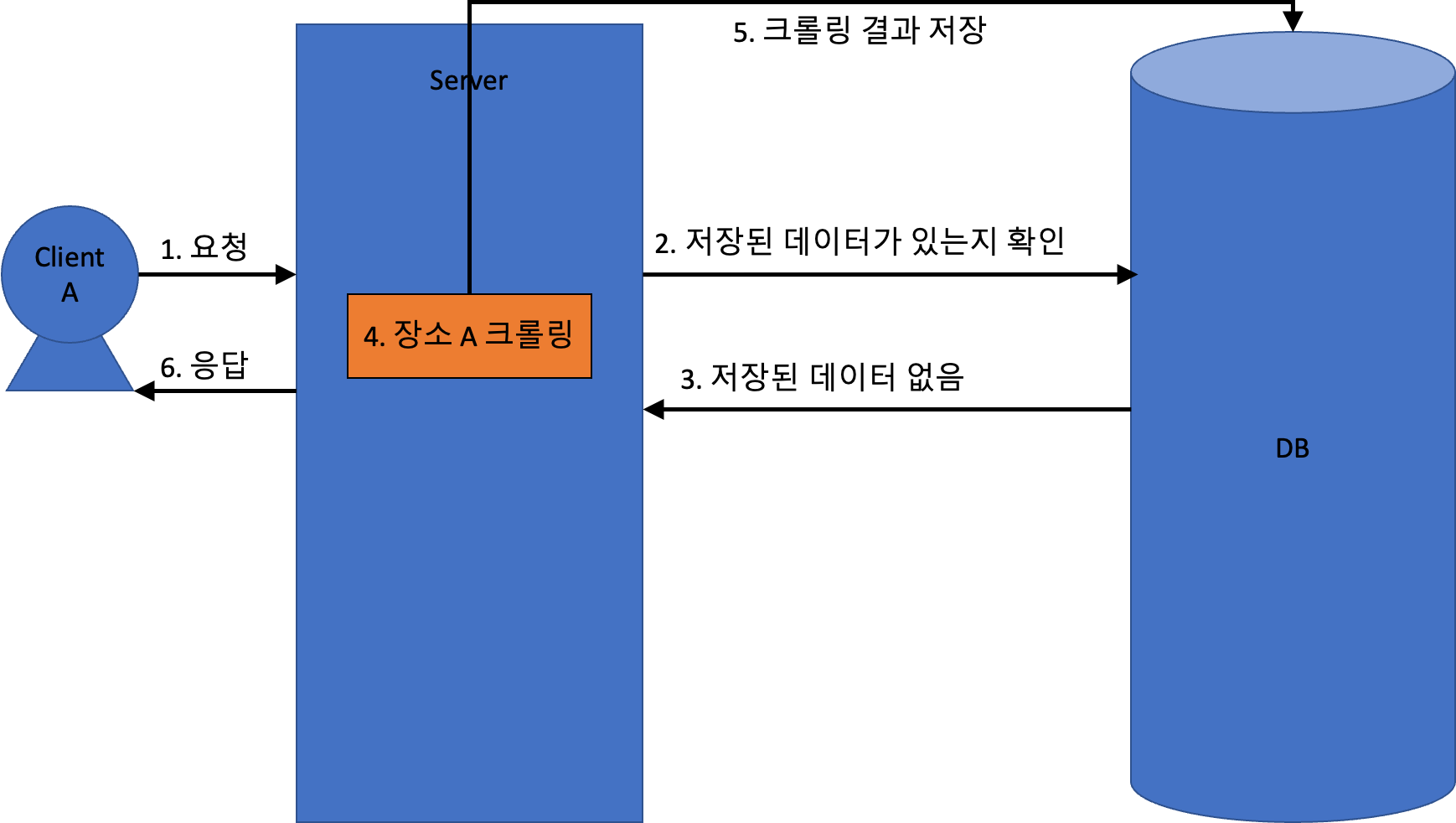

중복 크롤링 문제
동일한 장소를 여러번 크롤링
만약 캐싱되지 않은 장소 정보를 동시에 여러번 요청하면 어떻게 될까?
지금까지 설명한 구조에서는 아래와 같이 동작하게 된다. ClientA 와 ClientB 가 동시에 같은 장소를 요청했다고 해보자.
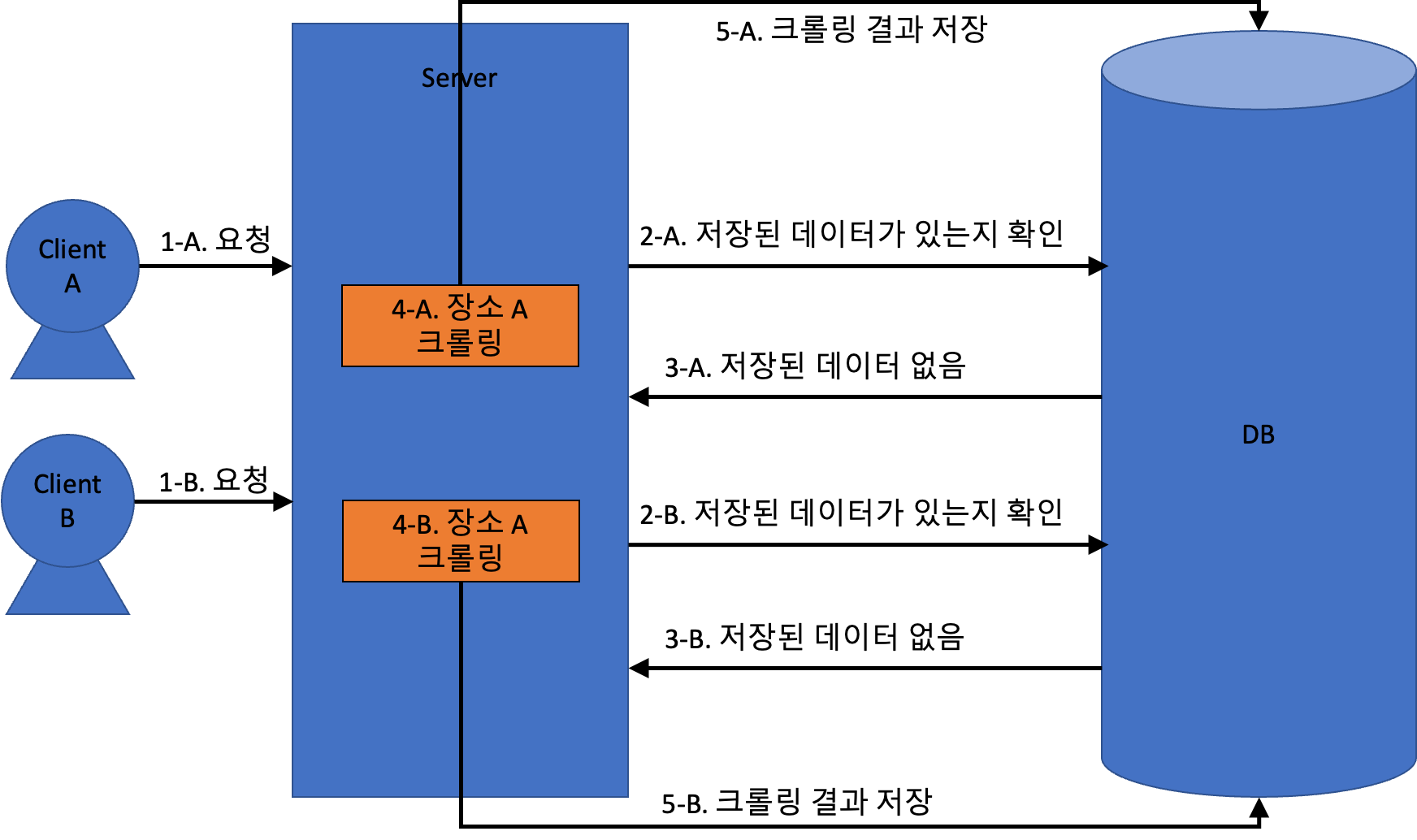
이 상황에 대한 문제점은 아래와 같다.
- 아직 DB에 저장된 데이터가 없으니, 한 장소에 대한 동일한 크롤링 작업을 2번해야한다.
- 그리고 똑같은 크롤링 결과를 DB에 2번 저장한다.
이 문제를 해결하기 위해서, “현재 어떤 장소에 대해 크롤링 작업을 수행하고 있는지 확인하고, 이미 처리중인 작업이 있으면 그 작업이 끝날때까지 기다린 후, 그 결과를 응답하는 방식”을 사용했다.
이를 그림으로 나타내면 아래와 같다.
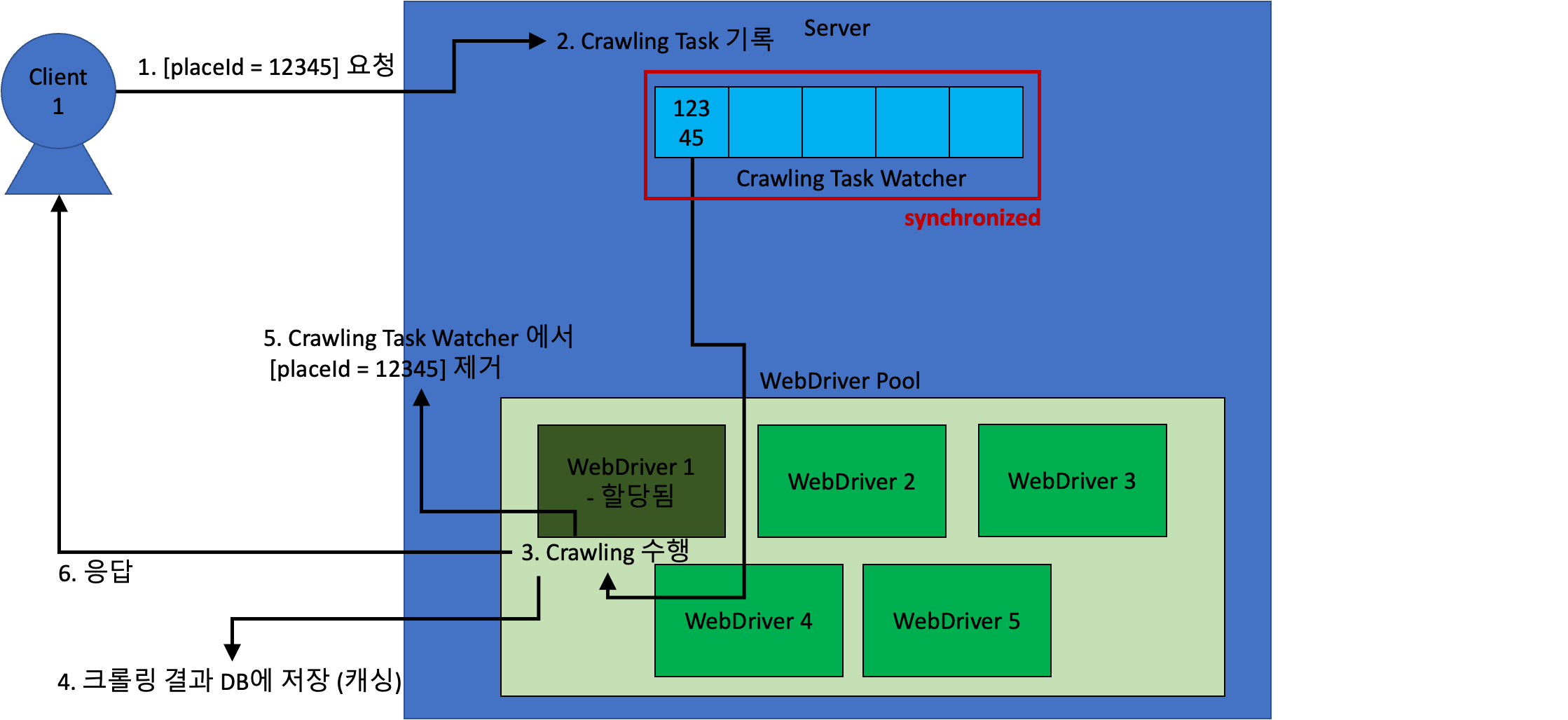
현재 크롤링 중인 placeId 를 Crawling Task Watcher 에서 관리하도록 한다.
만약 클라이언트 1이 요청한 장소와 동일한 요청을 동시에 요청하게 되면 다음과 같다.
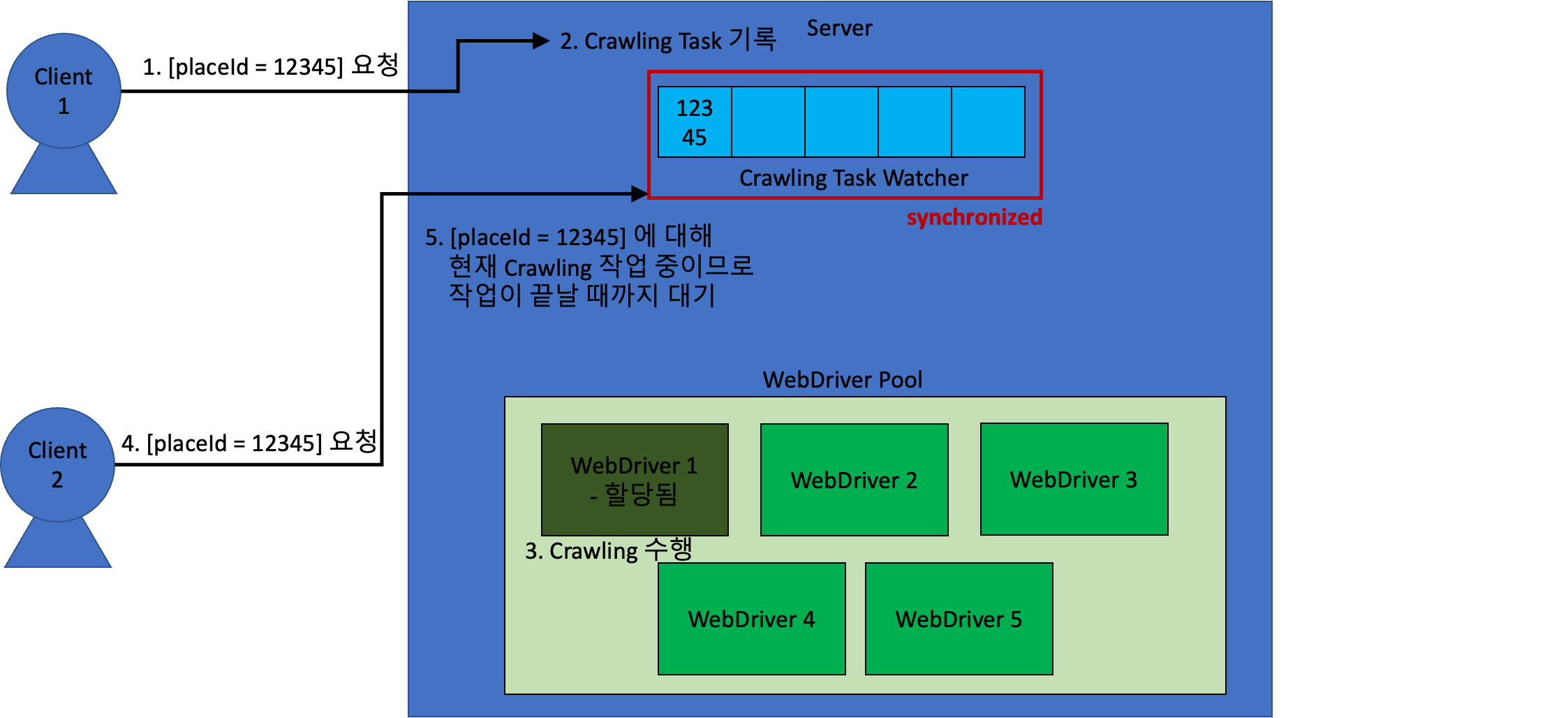
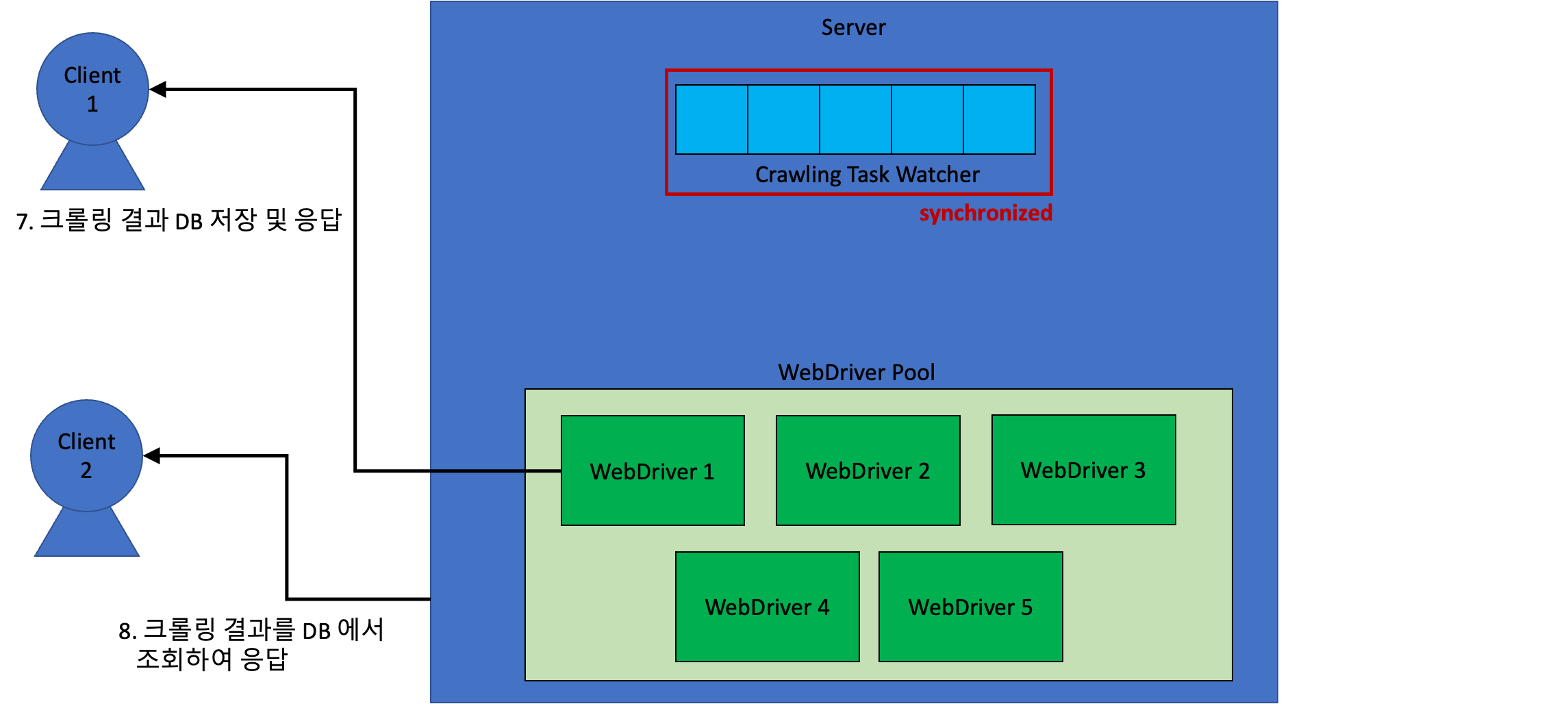
이러한 방식을 통해, 비효율성을 최소화할 수 있었다!
마치며…
이 프로젝트를 시작할 때만 해도, 단순하게 구현할 수 있을 줄 알았다.
하지만 개발 도중에 여러 문제가 발생했고, 이것을 나름 지혜롭게? 해결할 수 있었다.
이 포스팅에서 설명한 개념들을 토대로 구현한 실제 소스코드는 아래 Repo를 참고하면 될 것 같다.
이 글이 누군가에게 도움이 될 것이라 믿고, 글을 마치려 한다.