
‘우아한레디스 by 강대명’ 세미나 정리
개요
본 글에서 다루지 않는 것
- 이 포스팅은 [우아한테크세미나] 191121 우아한레디스 by 강대명님 을 정리한 글입니다.
- 발표 영상처럼 이 포스팅에서 아래 내용은 다루지 않습니다.
- Redis Persistence (RDB, AOF)
- Redis Pub/Sub
- Redis Stream
- 확률적 자료구조
- Redis Module
- 실제 Redis 사용방법에 대해서는 아래 링크를 참고하면 좋을 것 같습니다.
Redis 란?
아래는 Redis의 특징이다.
- In-Memory Data Structure Store
- Open Source (BSD 3 License)
- Support Daaata Structures
- Strings, set, sorted-set, hashes, list
- Hyperloglog, bitmap, geospatial index
- Stream
CPU Cache
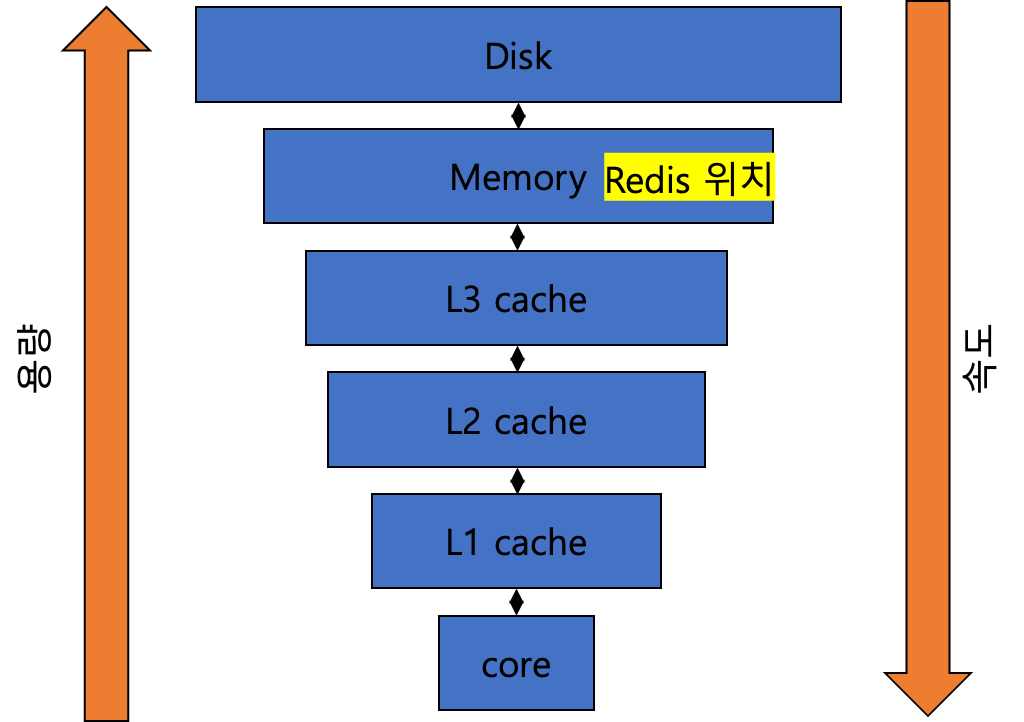
- 따라서 Redis는 다른 관계형 DB 보다 속도가 빠르다.
Redis 가 왜 필요할까?
단순한 웹 서비스 구조
아래 그림은 아주 단순한 웹 서비스의 구조도이다.

여기에 Cache 를 도입해보자.
Cache 구조 1 - Look aside Cache

Cache 구조 2 - Write Back

- 단 장애 발생 시, 데이터가 날아갈 위험이 존재한다.
- In-Memory 이기 때문에
이러한 Cache 역할을 하기 위해 Redis가 필요하다. 물론 또다른 목적으로 Redis를 도입할 수 있다.
Redis를 어디에 써야할까?
Redis 사용처
- Remote Data Store
- A서버, B서버, C서버에서 데이터를 공유하고 싶을 때
- Redis는 싱글 쓰레드로 동작하기 때문에 동시성 문제에서 보다 자유롭다.
- 주로 많이 쓰이는 곳
- 인증 토큰 등을 저장 (Strings 또는 hash 자료구조 이용)
- Ranking 보드로 사용 (sorted-set 자료구조 이용)
- 유저 API Limit
- 잡큐 (list 자료구조 이용)
Redis Collection
Redis가 제공하는 Collection
Redis는 Collection 자료구조를 제공한다. 이러한 자료구조를 통해, 데이터를 저장하고 읽을 수 있다.
그렇다면 Redis가 Collection을 제공하므로써 얻을 수 있는 것은 무엇일까?
- 개발의 편의성
- Redis가 Collection 기능을 제공하기 때문에 개발시 편리하다.
- Redis에서 사용하던 자료구조 그대로 개발 코드에서 사용할 수 있다.
- 개발의 난이도
- Redis에서 Collection을 다루는 작업은 Atomic 하다.
- Atomic : 더 이상 쪼개질 수 없는 단위
- 즉 Redis는 싱글 쓰레드로 동작하여 Race Condition을 피할 수 있다.
- Race Condition : 쉽게 말해, 여러 쓰레드가 공유 자원을 사용하여 결과값이 예상과 다르게 나오는 상태를 말한다. (위키백과)
물론 잘못짜면 발생할 수 있다.
- Redis에서 Collection을 다루는 작업은 Atomic 하다.
Redis Collection 종류
- Strings
- List
- Set
- Sorted Set
- Hash
지금부터 하나씩 알아보자.
Strings - 단일키
- 기본 사용법
- 저장 :
Set <key> <value> - 조회 :
Get <key>
- 저장 :
- 예시
Set token:1234567 absdaweGet token:1234567
- Key Prefix
- 보통 저장된 데이터를 구분하기 위해, key 값에 prefix를 붙인다.

Strings - 멀티키
- 기본 사용법
- 저장 :
mset <key1> <value1> <key2> <value2> ... <keyN> <valueN> - 조회 :
mget <key1> <key2> ... <keyN>
- 저장 :
- 예시
mset token:1234567 asdsad email:1234567 test@gmail.commget token:1234567 email:1234567
Strings vs SQL
SQL문을 대체해보자.
INSERT INTO USERS(NAME, EMAIL) VALUES ('test', 'test@gmail.com');
-
Strings - 단일키
Set name:test test Set email:test test@gmail.com -
Strings - 멀티키
Mset name:test test email:test test@gmail.com
List : insert
- 기본 사용법
Lpush key1 A→ key1: (A)- 리스트의 왼쪽에 삽입한다.
Rpush key1 B→ key1: (A, B)- 리스트의 오른쪽에 삽입한다.
Lpush key1 C→ key1: (C, A, B)Rpush key1 D, A→ key1: (C, A, B, D, A)Lpush key E, F→ key1: (F, E, C, A, B, D, A)
List : pop
- 기본 사용법
Lpop <key>Rpop <key>
Set
- 기본 사용법
SADD <key> <value>- value가 이미 key에 있으면 추가되지 않는다.
SMEMBERS <key>- 모든 value를 돌려준다.
SISMEMBER <key> <value>- value가 존재하면 1, 없으면 0
Sorted Set
- 기본 사용법
ZADD <key> <score> <value>- value가 이미 key에 있으면 해당 score로 변경된다. 즉 해당 value의 score를 수정한다.
ZRANGE <key> <startIndex> <EndIndex>- 해당 index 범위 값을 모두 돌려준다.
- index는 0부터 시작한다.
- -1은 끝까지를 나타낸다.
- 주의사항
- Sorted Set의 score는 double 타입이기 때문에, 값이 정확하지 않을 수 있다.
Hash
- Hash 구조는
key하위에sub key가 존재한다.key subkey value
- 기본 사용법
Hmset <key> <subkey1> <value1> <key> <subkey2> <value2>Hgetall <key>- 해당 key의 모든 subkey와 value를 가져온다.
Hget <key> <subkey>Hmget <key> <subkey1> <subkey2> ... <subkeyN>
Hash vs SQL
SQL문을 대체해보자.
INSERT INTO USERS(NAME, EMAIL) VALUES ('test', 'test@gmail.com');
Hash 를 사용한다면 아래와 같다.
Hmset testKey name test email test@gmail.com
Collection 주의 사항
- 하나의 컬렉션에 너무 많은 아이템을 담으면 좋지 않다.
- 10,000개 이하 수준으로 유지하는게 좋다.
- Expire는 Collection의 item 개별로 걸리지 않고, 전제 Collection에 대해서만 걸린다.
- 즉 10,000 개의 아이템을 가진 Collection에 expire가 걸려있다면, 그 시간 후에 10,000개의 아이템이 모두 삭제된다.
Redis 운영
운영 시, 핵심 포인트
- 메모리 관리를 잘하자.
O(N)관련 명령어는 주의하자.
하나씩 자세히 설명하겠다.
메모리 관리
- Redis는 In-Memory Data Store 이다.
- 만약 Physical Memory 이상을 사용하게 되면, 문제가 발생한다.
- Swap 이 있다면 Swap 사용으로 해당 메모리 Page를 접근할 때마다 늦어진다.
- Swap 이 없다면 Redis가 죽는다. (OS단에서 처리할 것임)
- MaxMemory를 설정하더라도 이보다 더 사용할 가능성이 크다.
- Redis는 ‘JeMalloc’이라는 메모리 관리 솔루션을 사용하여 메모리를 관리한다.
- 하지만 ‘JeMalloc’이 완벽하지 않다. (상당히 잘만들어졌음에도 불구하고)
- 만약 메모리의 page 단위가
10 kbytes이라고 했을 때, 한 컬렉션의 크기가11 kbtyes이라면 할당되는 메모리는 총20 kbytes이다. 이것을 메모리 파편화라고 한다. - 위 상황이 반복된다면..?
-
큰 메모리를 사용하는 instance 하나보다는 적은 메모리를 사용하는 instance 여러개가 안전하다.

- 왜냐하면 Redis가 ‘RDB 파일(백업파일)을 생성하는 등’의 write 작업을 할 때, 자식 프로세스를 생성하여 Fork 하기 때문이다. (Copy On Write)
- 예를 들어, 물리 메모리가
8 GB인 서버에서 Redis가5 GB를 사용하고 있다고 해보자. 이때4 GB분량의 RDB를 생성하는 작업을 수행해야 한다면, 자식 프로세스가 생성되어 수행된다. 따라서 Copy On Write 가 발생하고 총9 GB의 메모리가 필요하게 된다. - 그렇다면 이게 어째서 적은 메모리를 사용해야 안전하다는 것의 근거가 될까?
- Fork를 통해 자식 프로세스를 생성하게 되면, 기존의 메모리의 최대 2배 용량을 사용할 수 있기 때문이다. 따라서 메모리 크기가 작을수록 유리하다.
- Redis는 메모리 파편화가 발생할 수 있다.
- 따라서 다양한 사이즈를 가지는 데이터보다는 유사한 크기의 데이터를 가지는게 유리하다.
메모리를 줄이기 위한 설정
- 기본적으로 Collection 들은 아래와 같은 자료구조를 사용한다.
- Hash 구조 → HashTable을 하나 더 사용
- Sorted Set 구조 → Skiplist와 HashTable을 이용
- Set 구조 → HashTable 사용
- 해당 자료구조들은 메모리를 많이 사용한다.
- Ziplist를 이용하자.
- 속도는 조금 느리지만, 용량에 있어 유리하다.
- 약 20~30% 정도의 메모리를 절약할 수 있다.
Ziplist 구조
- 위에서 설명한 자료구조들은 추가적인 HashTable을 갖는다. 왜냐하면 해쉬 자료구조는
O(1)시간복잡도를 갖기 때문이다. - 하지만 만약 아이템의 개수가 적다면, 선형 탐색을 해도 크게 문제가 없다. (In-Memory이기 때문에 충분히 빠르다.)
- Ziplist 는 HashTable 없이 선형탐색을 하는 자료구조이다.
O(N) 관련 명령어는 주의하자
- Redis는 Single Threaded 이다.
- 따라서 Redis가 동시에 여러 개의 명령을 처리할 수 없다. (Atomic)
- 하나의 명령어가 긴 시간을 소요한다면, 그동안 해당 명령어 외의 작업은 불가능하다.
- 대표적인
O(N)명령KEYSFLUSHALL,FLUSHDB- Delete Collections
- Get All Collections
KEYS 명령 대체 방법
scan명령을 사용하는 것으로 대체할 수 있다.- 한번의 명령으로 모든 것을 조회하는
keys명령과는 다르게,scan명령은 조회의 범위가 정해져있다. - 따라서 모든 것을 조회하려면 여러 번 명령을 입력해야 한다.
- 그리고 여러 번의 명령을 입력하는 사이에 다른 작업이 수행될 수 있다.
Collection 의 모든 item을 가져오는 방법
- Collection의 일부만 가져오는 방법이 가장 쉬운 방법이다.
- 아니면 큰 Collection을 작은 여러 개의 Collection으로 나눠서 저장하는 방법도 있다.
userranks: 3만 개의 아이템이 저장된 Collectionuserranks1,userranks2,userranks3: 각각 1만 개의 아이템이 저장된 Collections 들
Redis 권장 설정 - redis.conf 권장 설정
Maxclient설정 = 50,000RDB/AOF설정 - off- 특정 commands disable
KEYS
- 전체 장애의 90% 이상이
KEYS와SAVE 설정을 사용해서 발생한다.