
명령어 세트
개요
기계 명령어, 컴퓨터 명령어란?
- 프로세서가 실행할 수 있는 여러 가지 명령어들의 집합이다.
- 기계어 코드라고도 한다.
기계 명령어 형식
- 명령어는 일련의 비트들에 의해서 표현된다.
- 명령어 세트에서 한 가지 이상의 명령어 형식이 사용될 수 있다.
- 명령어 세트에는 다양한 형식의 명령어가 존재한다.
- 명령어는 필드들로 나누어진다.
-
간단한 명령어 형식

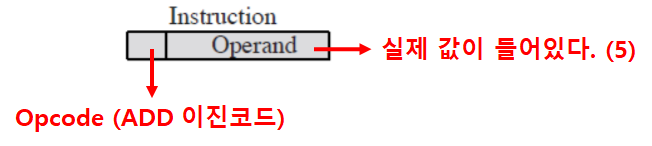
- Opcode
- 명령을 표현하는 이진 코드
- Operand
- 명령에 사용될 값 or 주소
- 하나의 명령어에 여러 Operand 필드가 존재할 수 있다.
- 명령에 사용될 값 자체를 담을 수도 있고, 명령에 사용될 값의 주소를 담을 수도 있다.
- Opcode
기계 명령어의 요소들
아래는 기계 명령어를 구성하는 요소들이다.
- 연산 코드
- 수행될 연산을 지정한다.
- 연산 코드 or Opcode 에 의해 지정된다.
- 원천 오퍼랜드 참조
- 연산할 Data의 주소 또는 실제값을 담는다.
- 결과 오퍼랜드 참조
- 연산 결과를 저장할 위치(주소)를 담는다.
연산 코드: 명령어 종류
- 데이터 처리
- 산술 및 논리 명령어
- 데이터 저장
- 기억장치와 레지스터 간의 데이터 이동
- 데이터 이동
- I/O 명령어들
- 프로그램 제어
- 검사와 분기 명령어
원천/결과 오퍼랜드의 위치
오퍼랜드가 존재할 수 있는 위치는 아래와 같다.
- 주기억장치 or 가상 기억장치
- 가상 기억장치: HDD 공간의 일부를 임시 Main Memory로 사용하는 것이다.
- 프로세서 레지스터
- I/O 장치
한 명령어 내의 주소(Operand) 개수
주소 개수?
- ‘한 명령어 내의 주소의 개수’는 프로세서의 구조를 설명하는 방법 중의 하나이다.
한 명령어에 필요한 주소의 종류
- 오퍼랜드의 참조를 위한 주소
- 연산 결과를 저장하기 위한 주소
3-주소 체계: 한 명령어 내에 3개의 주소가 존재하는 경우
-
주소 개수에 따른 명령어를 확인하기 위해, 다음 프로그램(연산)을 처리한다고 가정하자.
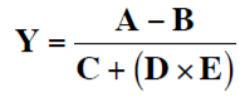
-
처리과정
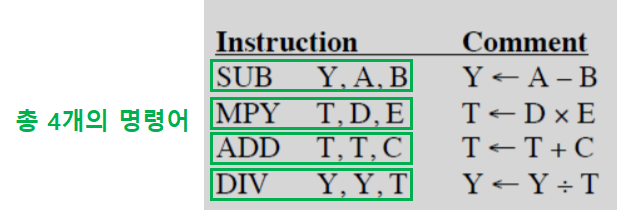
- 총 3개의 주소를 사용하여, 명령어를 구성하는 것을 확인할 수 있다.
- 임시 저장 공간인 T를 사용한다.
- 위 순서대로 명령어를 실행하면 위 프로그램(연산)을 수행할 수 있다.
-
3-주소 체계 특징
- 상대적으로 긴 명령어 형식이 필요하다.
- 필요한 명령어 개수는 적지만, 각 명령어의 길이가 길다.
- 별로 사용되지 않는 방식이다.
이어서, 동일한 프로그램에 대해 2-주소, 1-주소 체계에서는 어떻게 처리되는지 확인해보자.
2-주소 체계: 한 명령어 내에 2개의 주소가 존재하는 경우
-
처리과정
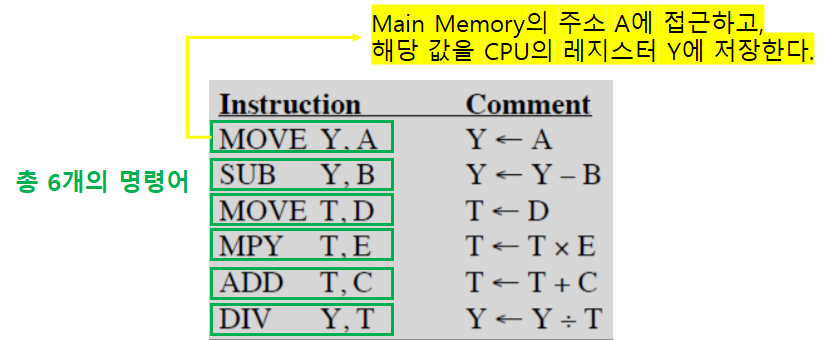
- 총 2개의 주소를 사용하여, 명령어를 구성하는 것을 확인할 수 있다.
-
2-주소 체계 특징
- 주소 하나가 ‘오퍼랜드의 주소’와 ‘결과의 주소’를 모두 지정한다.
- Y : ‘오퍼랜드 주소(A)’ 지정, ‘결과의 주소(Y-B, Y/T)’ 지정
Y ← A,Y ← Y-B,Y ← Y/T
- T : 오퍼랜드 주소(D) 지정, 결과의 주소(T*E, T+C) 지정
T ← D,T ← T*E,T ← T+C
- Y : ‘오퍼랜드 주소(A)’ 지정, ‘결과의 주소(Y-B, Y/T)’ 지정
- 명령어의 길이가 줄어든다.
- 필요한 명령어의 개수가 많아지지만, 각 명령어의 길이가 짧다.
- 주소 하나가 ‘오퍼랜드의 주소’와 ‘결과의 주소’를 모두 지정한다.
1-주소 체계: 한 명령어 내에 1개의 주소가 존재하는 경우
-
처리과정

- 총 1개의 주소를 사용하여, 명령어를 구성하는 것을 확인할 수 있다.
-
1-주소 체계 특징
- 두번째 주소는 묵시적으로 사용한다.
- 즉, “두번째 주소 == AC(누산기)” 라고 가정하고 명령어를 수행한다.
- 대개 레지스터(누산기, AC)를 두번째 주소로 사용한다.
- 초기 컴퓨터에서 흔히 사용되곤 했다.
- 두번째 주소는 묵시적으로 사용한다.
0-주소 체계: 한 명령어 내에 주소가 없는 경우
- 0-주소 체계는 스택을 사용한다.
-
처리과정

- 스택에 대해, 위 연산들을 수행하여 계산한다.
- 0-주소 체계 특징
- 모든 주소가 묵시적이다.
- 스택을 사용한다.
정리
- 주소가 많을수록
- 명령어가 복잡해진다.
- 레지스터가 더 많이 필요하다.
- 임시 저장공간이 더 많이 필요하다.
- 프로그램 당 명령어의 수가 적어진다.
- 주소가 적을수록
- 명령어가 덜 복잡해진다.
- 명령어 길이가 짧아진다.
- 프로그램 당 명령어의 수가 증가한다.
- 명령어의 인출/실행이 더 빨라진다.
- 명령어가 짧기 때문이다.
명령어 세트 설계
명령어 세트 설계시 고려사항
명령어 세트를 설계한다면, 아래와 같은 항목을 고려해야 한다. 이것들을 참고하여, 학습 Point를 잡자.
- 데이터 유형
- 연산의 종류
- 연산의 개수
- 연산의 기능
- 연산의 복잡도
- 명령어 형식
- 명령어의 길이
- 주소의 개수
- 각 필드의 크기
- 주소지정 방식
- 오퍼랜드의 주소가 지정되는 방식
- 레지스터
- 명령어에 의해, 참조될 레지스터의 개수
- 명령어에 의해, 참조될 레지스터의 용도
오퍼랜드 종류
오퍼랜드의 종류는 아래와 같다. 즉, 아래 항목들이 명령어의 Operand 필드에 들어올 수 있는 값의 종류이다.
- 주소
- 값이 들어있는 공간의 주소
- 수
- 정수, 부동소수점 수
- 문자
- ASCII 등
- 논리적인 데이터
- 비트
- 플래그 등
연산의 종류들
연산의 종류
연산의 종류는 무엇이 있을까. 이는 아래와 같다.
- 데이터 전송
- 산술
- 논리
- 제어의 이동
- 변환
- 입출력
- 시스템 제어
이제부터 중요한 내용들에 대해, 상세히 설명하겠다.
연산: 데이터 전송
- 데이터 전송 명령어가 명시해야하는 사항
- 근원지·목적지 오퍼랜드 위치
- 기억장치나 레지스터, 스택의 최상위 등의 위치를 말한다.
- 전송될 데이터의 길이
- 각 오퍼랜드의 주소지정 방식
- 주소를 어떤 방식으로 지정하는지 알아야 한다.
주소를 지정하는 방식은 아래에서 상세히 설명한다.
- 근원지·목적지 오퍼랜드 위치
- 데이터 전송 과정 (프로세서 동작 과정)
- 만약, 오퍼랜드의 근원지·목적지의 위치가 모두 레지스터인 경우
- 프로세서 내부에서 레지스터 간의 데이터 교환이 수행된다.
- 만약, 오퍼랜드의 근원지·목적지의 위치가 기억장치(Main Memory)인 경우
-
주소 지정 방식에 근거하여, 기억장치의 주소를 계산한다.
다시 말하지만, 주소 지정 방식에 대한 상세한 내용은 나중에 설명하겠다.
- 만약 주소가 가상 기억장치를 참조한다면, 가상 주소를 실제 기억장치 주소로 변환한다.
- 주소 지정된 항목이 캐시에 있는지 확인한다.
- 캐시에 없다면, 기억장치 모듈로 명령(데이터 전송 명령)을 보낸다.
-
- 만약, 오퍼랜드의 근원지·목적지의 위치가 모두 레지스터인 경우
연산: 산술
- 산술 종류
- 덧셈
- 뺄셈
- 곱셈
- 나눗셈
- 단일 오퍼랜드 연산 종류
- 절대화
-
a
-
- 증가
- a++
- 감소
- a–
- 음수화
- -a
- 절대화
- ‘프로세서의 ALU’에서 산술 연산을 수행한다.
- 산술 연산을 위해 “ALU ↔ Main Memory 간 데이터를 이동시키는 것”까지, 산술연산에 포함된다.
연산: 논리
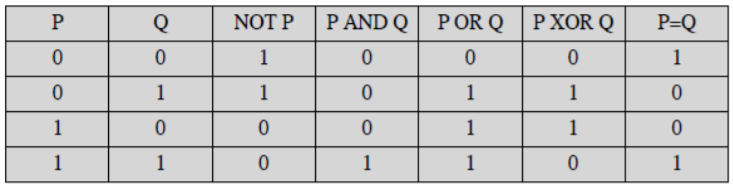
- 논리 연산은 비트를 조작하는 연산을 한다.
- 논리 연산 종류
- AND
- OR
- NOT
-
기본적인 논리 연산들
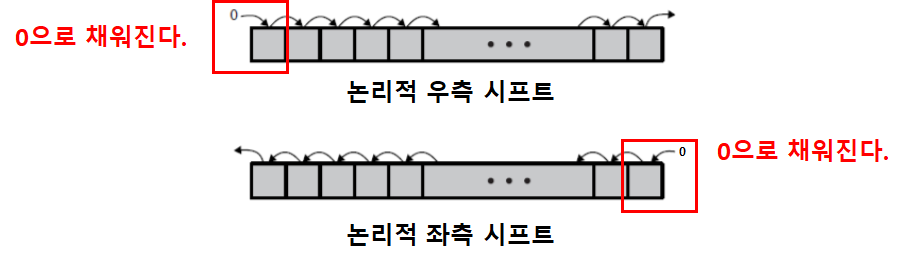
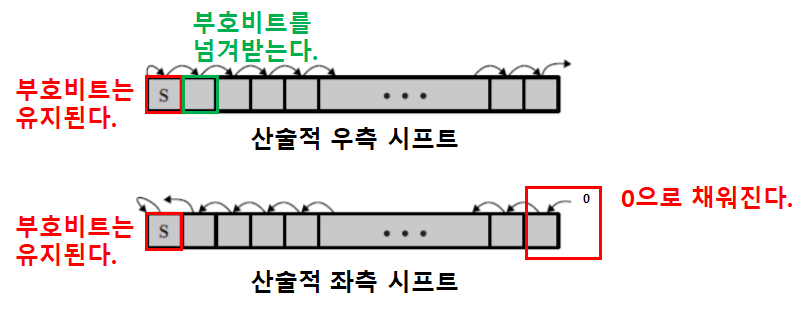
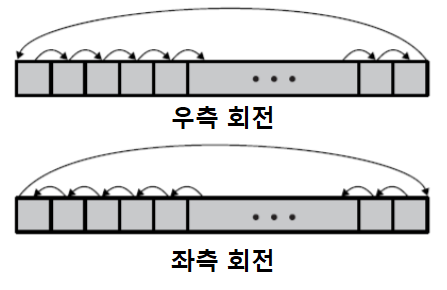
시프트와 회전 연산
- 시프트 연산 종류
- 논리적 시프트
- 모든 비트를 옮긴다.
- 산술적 시프트
- 부호 비트는 유지한채로 옮긴다.
- 논리적 시프트
-
회전 연산
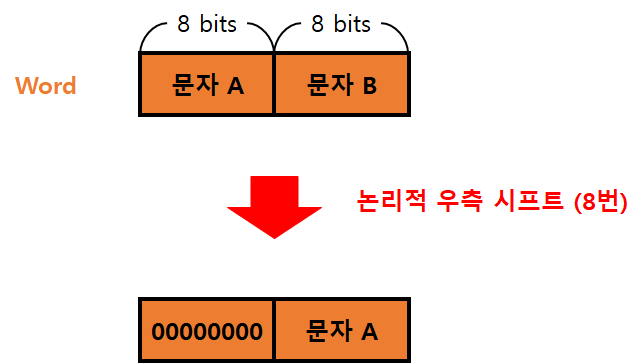
논리적 시프트의 사용
- Main Memory의 한 Word가 두개의 문자를 저장한다면, 이것을 구분하기 위해 논리적 시프트가 사용될 수 있다.
- 예시를 통해 알아보자.
- 문제
- 각 기억장치 Word의 길이 : 16비트
- 한 Word에 두 개의 문자를 저장한다.
- 즉, 하나의 문자는 8비트이다.
실제로 ASCII 체계에서 1Byte (8 bit)를 하나의 문자로 설정한다.
- 이 두 개의 문자를 구분하여 출력해보자.
- 좌측 문자를 출력하는 절차: 논리적 우측 시프트
- 해당 Word를 레지스터에 적재한다.
- 우측으로 8번 시프트한다.
- I/O를 수행한다. I/O 모듈이 하위 8비트를 읽는다.
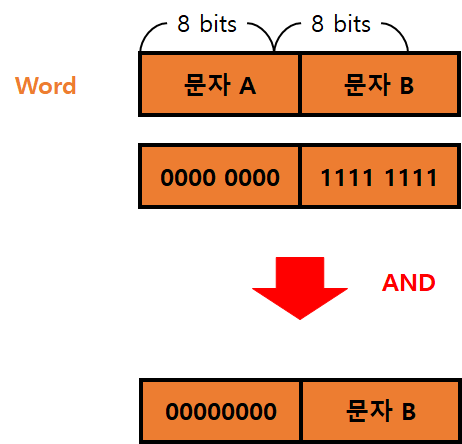
- 우측 문자를 출력하는 절차: AND 논리 연산
- 해당 Word를 레지스터에 적재한다.
- 00000000 11111111 와 AND 연산을 수행한다. (좌측 문자를 제거한다.)
- I/O 를 수행한다.
산술적 시프트의 사용
- 숫자에 곱셈을 해야할 때, 사용할 수 있다.
- 비트 연산은 상당히 빠르므로, 계산시 유용하게 사용될 수 있다.
- 산술적 좌측 시프트
- 곱하기 2와 같다.
- 예시
- 8 = 00001000
- 00001000 에 대해, 좌측 시프트 1번 ⇒ 00010000 = 16
- 산술적 우측 시프트
- 나누기 2와 같다.
- 예시
- 8 = 00001000
- 00001000 에 대해, 우측 시프트 1번 ⇒ 00000100 = 4
연산: 제어의 이동
- 분기
- 분기를 통해, 제어를 이동시킨다.
- 분기의 종류
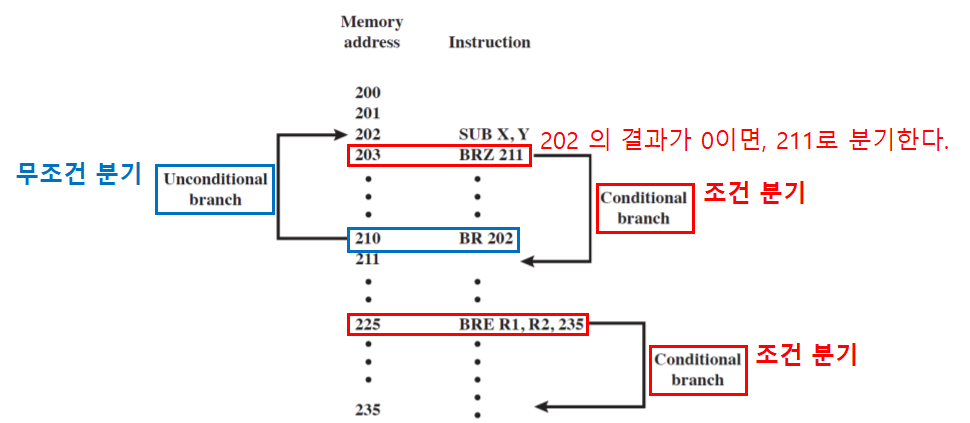
- 무조건 분기 : 조건없이 항상 분기된다.
- BR X : 위치 X로 분기하라
- 조건 분기 : 조건에 따라, 분기된다.
- BRP X : 결과가 양수면, 위치 X로 분기하라.
- BRN X : 결과가 음수면, 위치 X로 분기하라.
- BRZ X : 결과가 0이면, 위치 X로 분기하라.
- BRO X : 오버플로우가 발생하면, 위치 X로 분기하라.
- BRE R1, R2, X : R1의 내용과 R2의 내용이 일치하면, 위치 X로 분기하라.
- 무조건 분기 : 조건없이 항상 분기된다.
-
분기 예시
연산: Skip
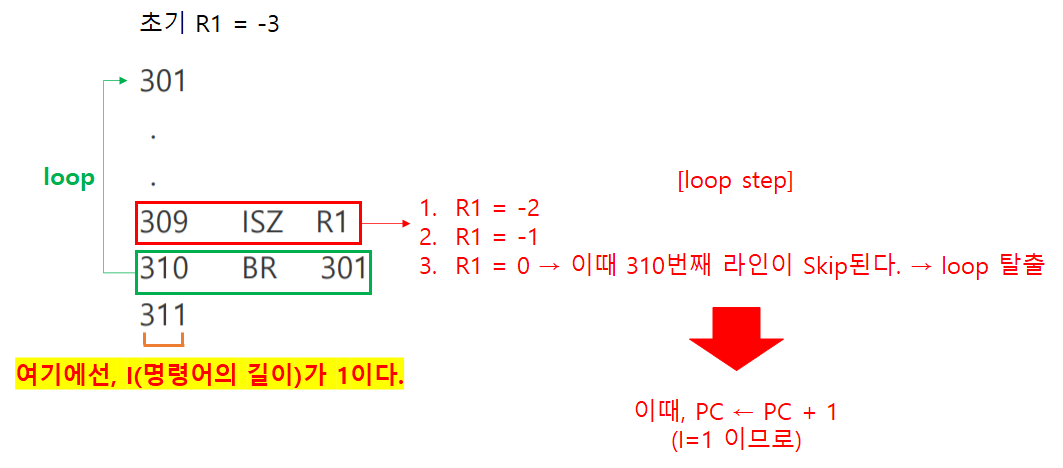
- 하나의 명령어를 건너뛰게 한다.
- 건너뛸 때, PC(Program Counter)를 업데이트해야 한다.
- "’다음 명령어의 주소’에 ‘하나의 명령어의 길이’를 더한 값”으로 업데이트한다.
- 하나의 명령어의 길이 = I (대문자 i)
- 즉, PC ← PC + I 으로 업데이트해야 한다.
- 예시
- ISZ: Increment and Skip if Zero
- 특정 값에 1을 더하고 결과가 0이라면, 바로 아래 명령어를 Skip하라.
- ISZ: Increment and Skip if Zero
주소지정
다양한 주소 지정 방식을 사용하는 이유
- 오퍼랜드의 주소 길이가 액세스 가능한 기억장치의 크기를 결정한다.
- 하지만, 전형적인 명령어 형식에서는 짧은 길이의 주소 필드를 사용한다.
- 따라서 보다 큰 주기억장치 또는 가상기억장치 영역을 사용하기 위해서, 다양한 주소 지정 방식을 사용한다.
주소지정 기법에서의 고려사항 (학습 Point)
- ‘주소지정 영역’과 ‘주소지정 유연성’ 간의 적절한 조절
- ‘기억장치 참조의 횟수’와 ‘주소 계산의 복잡성’
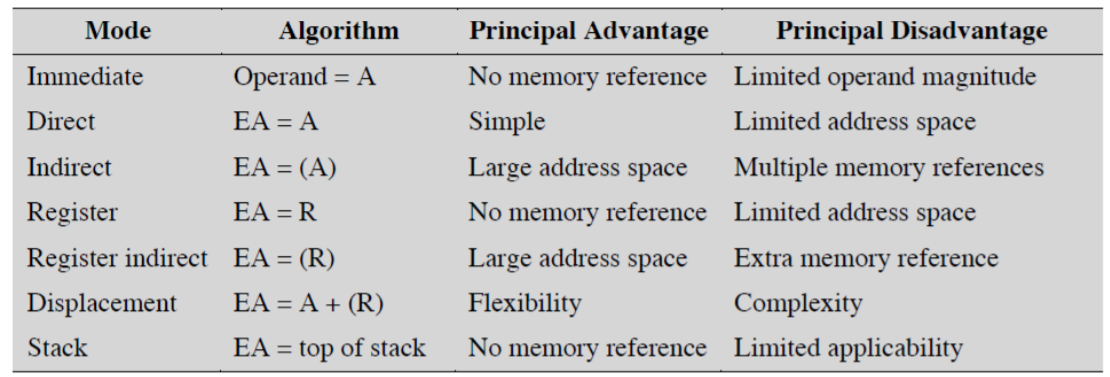
일반적인 주소지정 방식
- 즉시
- 직접
- 간접
- 레지스터
- 레지스터 간접
- 변위
- 스택
지금부터 하나씩 살펴보자.
주소지정 방식: 즉시 주소지정
- 오퍼랜드가 명령어에 포함된다.
- 즉, Operand 필드에 실제 값이 들어 있다.
- 예시
- ADD 5
- 특징
- 오퍼랜드를 인출하기 위해서, 기억장치를 참조하지 않는다.
- 즉, ‘명령어 사이클’에서 하나의 ‘기억장치 사이클’ 또는 ‘캐시 사이클’을 줄일 수 있다.
- 명령어 사이클: 명령어인출 → 명령어해독 → 데이터인출 → 계산 → 결과저장
- 여기서, 데이터인출 과정이 필요없다!
- ‘사용할 수 있는 수의 크기’가 ‘주소필드의 크기’로 제한된다.
- 왜냐하면, Operand로 값을 표현하기 때문이다.
- 오퍼랜드를 인출하기 위해서, 기억장치를 참조하지 않는다.
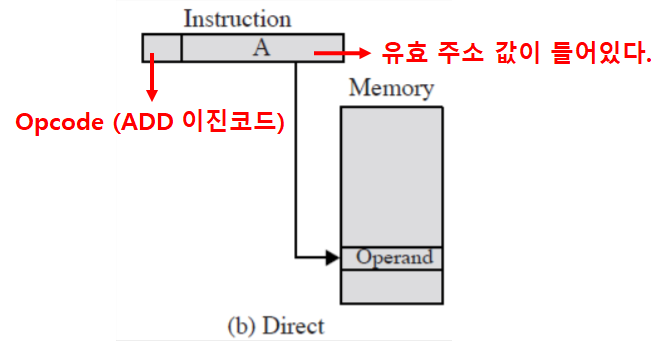
주소지정 방식: 직접 주소지정
- ‘명령어의 주소 필드’가 ‘오퍼랜드의 유효 주소’를 갖는다.
- 유효 주소: 원하는 실제 값이 들어있는 곳의 실제 주소
- EA (Effective Address, 유효주소) = Address Field (A, 오퍼랜드·주소 필드)
- 예시
- ADD A
- 특징
- 기억장치를 한번만 참조한다.
- 유효 주소 계산을 위한 추가 작업이 없다.
- 주소 공간 제한
- Operand 필드 크기에 따라, 액세스 가능한 공간의 크기(개수)가 제한되기 때문이다.
- 기억장치를 한번만 참조한다.
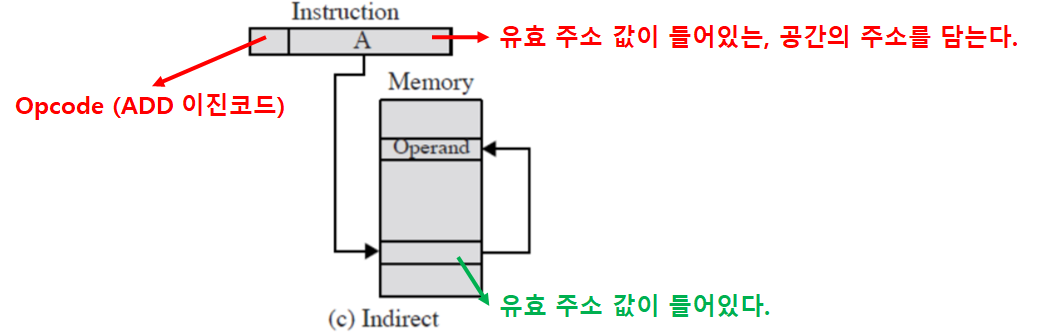
주소지정 방식: 간접 주소지정
- ‘주소 필드’는 ‘기억장치에 저장된 단어의 주소’를 가리킨다.
- 그리고 그 기억장치에 ‘오퍼랜드에 대한 주소 전체’를 저장한다.
‘pointer의 주소’를 주소필드에 담는다고 생각하면 쉽다.
- EA = (A)
- 괄호: 간접
- 예시
- ADD (A)
-
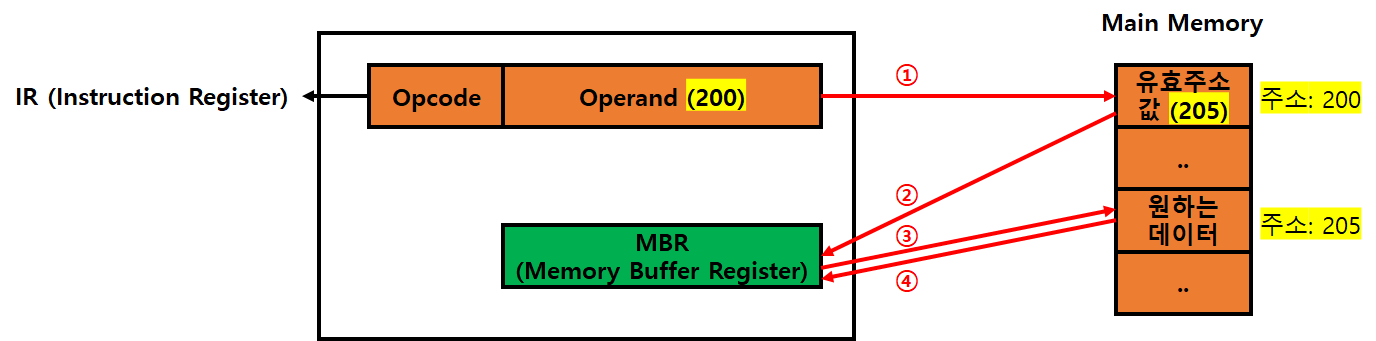
실제 동작 방식
- 특징
- 큰 주소 공간을 갖는다.
- Operand 길이가 아닌, Word 길이에 대해 접근 가능한 주소 개수가 결정되기 때문이다.
- 두 번의 기억장치 참조가 필요하다.
- 큰 주소 공간을 갖는다.
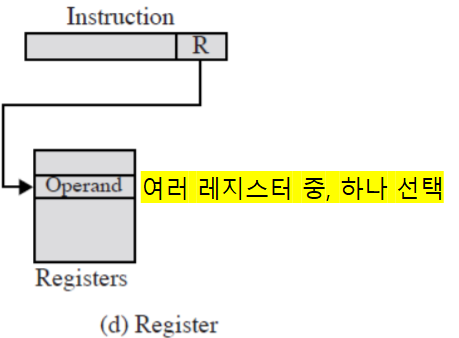
주소지정 방식: 레지스터 주소지정
- 직접 주소지정과 유사하다.
- ‘주소 필드’가 ‘레지스터’를 가리킨다.
- 주소 필드가 주기억장치 주소를 가리키지 않는다.
- EA = R
- R : 레지스터
-
구조
- 특징
- 명령어에서 주소 필드가 작아도 된다.
- ‘레지스터를 지정하는 주소 필드’는 3~5개의 비트를 가진다.
- 보통 사용 가능한 레지스터의 개수를 고려했을 때, 그 정도의 비트 수면 적당하다.
- 기억장치 액세스가 불필요하다.
- 따라서, 명령어 실행이 빨라진다.
- 주소 공간이 제한된다.
- 레지스터의 수가 제한적이기 때문이다.
- 명령어에서 주소 필드가 작아도 된다.
주소지정 방식: 레지스터 간접 주소지정
- 간접 주소지정 방식과 유사하다.
-
EA = (R)
-
구조
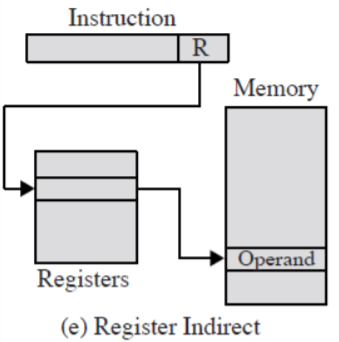
- 특징
- ‘주소 필드에 의해 주소 공간이 제한되는 문제’를 그 필드가 ‘주소를 가지고 있는 단어의 위치’를 가리키도록 함으로써 해결한다.
- 간접 주소지정 방식보다 기억장치 액세스 횟수가 1회 더 작다.
주소지정 방식: 변위 주소지정
- ‘직접 주소지정 + 레지스터 간접 주소지정’ 형태이다.
- EA = A + (R)
- A : 직접
- (R) : 레지스터 간접
- 총 두개의 주소 필드를 가지며, 둘 중 하나는 명시적이다.
- A = 기준 (base value)
- A: 명시적
- R = 기준으로부터 얼마나 떨어졌는가에 대한 정보
- R: 묵시적
A와 R의 역할이 서로 변경될 수 있다.
- A = 기준 (base value)
-
구조
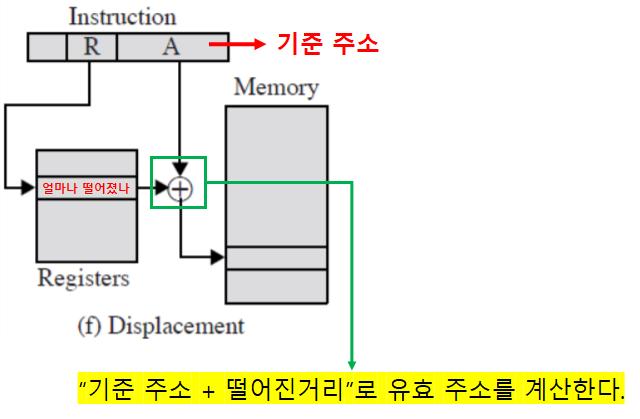
- 변위 주소지정 방식의 종류: 사용하는 레지스터에 따른 종류
- PC 상대 주소지정
- PC를 레지스터로 사용한다.
- EA = A + (PC)
- A: 변위값 (얼마나 떨어져있는가?) (A: 명령어 내의 Operand 필드)
- PC: 기준주소
- 대부분의 기억장치 참조들이 현재 실행되고 있는 명령어에 인접시, 상대 주소지정 방식을 이용하면 명령어의 주소 비트를 절약할 수 있다.
- 적용 예시) 분기 명령어
- 베이스-레지스터 주소지정
- 베이스 레지스터를 레지스터로 사용한다.
- EA = A + (BR)
- A: 변위값 (얼마나 떨어져있는가?) (A: 명령어 내의 Operand 필드)
- BR: 기준주소
- 적용 예시) 프로그램(데이터)의 위치 이동
- 인덱스 주소지정
- 인덱스 레지스터를 레지스터로 사용한다.
- EA = A + R
- A: 기준주소
- R: 변위값 (얼마나 떨어져있는가?)
- 이때, 레지스터 참조는 명시적일 수도 있고, 묵시적일 수도 있다.
- 명령어의 주소 필드가 기억장치 주소로 사용되므로, 베이스 레지스터 명령어에 비하여 주소 필드의 비트수가 더 많아진다.
- 적용 예시) 배열 데이터 연산 (반복 연산에 유리하다.)
- PC 상대 주소지정
주소지정 방식: 스택 주소지정
- 오퍼랜드는 스택의 최상위에 위치한다.
- 묵시적인 주소지정의 한 형태이다.
- 왜냐하면, 스택의 최상위부터 참조하기 때문이다.
- 묵시적인 주소지정의 한 형태이다.
- 예시
- ADD : 스택에서 pop 2번하여 나온 값들을 더한다.
정리
명령어 형식들
명령어 형식?
- 명령어 형식은 연산코드와 한 개 이상의 오퍼랜드를 포함한다.
- 대부분의 명령어 세트에서 하나 이상의 명령어 형식들이 사용된다.
명령어 길이
- 명령어 길이에 영향을 주는 요소들
- 기억장치의 용량
- 기억장치의 용량만큼을 오퍼랜드에 표현해야 하기 때문이다.
- 기억장치의 구조
- 사용하는 기억장치가 Register인지, Main Memory인지
- 버스의 구조
- 프로세서의 복잡도 및 속도
- 기억장치의 용량
- ‘명령어의 종류’와 ‘공간 절약’ 관계
- 연산 코드의 종류는 프로그램 길이에 반비례한다.
- 연산코드 종류 ↑ , 프로그램 길이 ↓
- 연산코드의 종류가 적으면, 프로그램적으로 처리해야 하는 것이 많기 때문이다.
- 오퍼랜드 개수는 프로그램 길이에 반비례한다.
- 오퍼랜드 개수 ↑ , 프로그램 길이 ↓
- 하나의 명령어에서 갖는 오퍼랜드 개수가 많으면, 자연스럽게 프로그램의 길이는 작아진다.
- 주소 지정방식이 다양하면, 다중 분기에 유연성을 제공한다.
- 주기억장치 및 가상 기억장치의 증가는 명령어 길이의 증가를 초래한다.
즉, ‘명령어의 길이 ↑’면 ‘프로그램 길이↓’
- 연산 코드의 종류는 프로그램 길이에 반비례한다.
- 명령어 길이는 기억장치 전송폭(데이터 버스폭)과 같거나, 다른 쪽의 배수가 되어야 한다.
비트할당
- ‘연산 코드의 종류’와 ‘주소지정 능력’ 관계
- 명령어 길이가 고정되어 있다면, opcode와 operand 크기 간에 조정이 필요하다.
- 주소지정 비트(operand용 비트)의 용도를 결정하는 요소
- 주소지정 방식의 수
- 오퍼랜드의 수
- 레지스터 대 기억장치
- 레지스터 세트의 수
- 주소 영역
- 주소의 세분화
가변길이 명령어
- 가변길이 명령어란?
- 하나의 명령어 세트안에 다양한 길이의 명령어가 존재하는 것
- 장점
- 길이가 서로 다른 더 많은 종류의 연산 코드를 쉽게 제공한다.
- 주소 지정이 융통성있게 된다.
- 단점
- 프로세서의 복잡도가 증가한다.
- RISC와 수퍼스칼라 구조의 기계들은 성능 개선을 위해 고정-길이 명령어를 사용한다.
RISC 구조
CISC 구조의 특징
- 명령어의 길이가 가변적이다.
- 여러 복잡한 형태의 주소 모드가 존재한다.
- 비교적 적은 수의 일반 목적용 레지스터 개수가 존재한다.
RISC 구조의 특징
- 기계 사이클당 하나의 기계어를 실행한다.
- 기계 사이클이란
- 아래 3가지 동작을 하는데 소요되는 시간
- 레지스터로부터 2개의 오퍼랜드 인출
- ALU 동작
- 결과를 레지스터에 저장
- 아래 3가지 동작을 하는데 소요되는 시간
- 즉, RISC는 “명령어인출·명령어해독·데이터인출·데이터실행·결과저장과 같이 M.M를 기반으로 동작하는 것”을 CPU 내에서 한번에 처리한다.
- 기계 사이클이란
- 대부분의 연산이 레지스터들을 통해 수행된다.
- 기계장치를 액세스하는 동작은 LOAD, STORE 명령어로만 구성되어야 한다.
- 따라서 RISK는 명령어가 더 단순하다.
- 비교적 많은 수의 일반 목적용 레지스터가 필요하다.
- 간단한 주소 지정 방식을 갖는다.
- 간단한 명령어 세트를 갖는다.
- 명령어 파이프라인의 최적화
- 성결대학교 컴퓨터 공학과 최정열 교수님 (2021)
- William Stalling, 『컴퓨터시스템구조론(10판)』