
헤드 포인터와 헤드 노드
개요
헤드 포인터 방식의 문제점
- 맨 앞 노드의 처리가 까다롭다.
Ex) “맨앞에 노드추가” , “중간에 노드추가” 따로 처리해주어야함.
- 해결방법: 헤드 노드
헤드 노드
참고: 일반적으로 ‘org’은 헤드노드를 가르킴
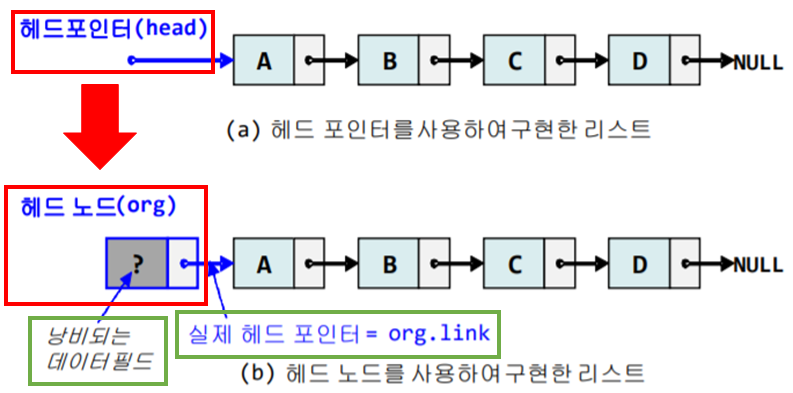
노드헤더 사용 리스트의 특징
- 헤드 노드를 제외한 모든 노드가 선행 노드를 갖는다.
- insert와 delete 연산이 간단해진다.
get_entry(-1)연산이 헤드노드의 주소를 반환하도록 수정해야한다.
get_entry(int index) 연산의 변화
get_entry(int index)
**<헤드 포인터="">**
Node* get_entry(int index) {
int i;
Node *n = head;
for(i=0; i<index; i++, n=n->link) {
if(n==NULL) { //끝까지 탐색했을때 (찾으려는 index가 존재하지 않을때)
return NULL;
}
}
return n;
}
**<헤드 노드="">**
Node* get_entry(int index) {
int i;
Node *n = &org;
for(i=-1; i<index; i++, n=n->link) {
if(n==NULL) { //끝까지 탐색했을때 (찾으려는 index가 존재하지 않을때)
break;
}
}
return n;
}
- 성결대학교 컴퓨터 공학과 박미옥 교수님 (2021)
- 최영규, 『두근두근 자료구조』