
- 이전 게시글
객체지향 쿼리 심화
개요
알아볼 내용
이번 포스팅에서 알아볼 내용은 아래와 같다.
- 벌크 연산
- 한번에 여러 데이터를 수정할 수 있는 기능
- JPQL과 영속성 컨텍스트 간의 관계
벌크 연산
배경
- 엔티티를 수정하려면, 영속성 컨텍스트의 변경 감지 기능(Dirty Check) 이나 병합 을 사용해야 한다.
- 엔티티를 삭제하려면,
EntityManager.remove()메서드를 사용해야 한다. - 하지만 이러한 방법으로 수백개 이상의 엔티티를 하나씩 처리하기에는 시간이 너무 오래 걸린다.
- 바로 이때, 벌크연산을 사용하면 된다.
예시 코드
-
UPDATE 벌크연산: 재고가 10개 미만인 모든 상품의 가격을 10% 상승시키기
//네이티브 쿼리 String qlString = "update Product p " + "set p.price = p.price * 1.1 " + "where p.stockAmount < :stockAmount"; //createNativeQuery()가 아닌, createQuery()를 사용한다. int resultCount = em.createQuery(qlString) .setParameter("stockAmount", 10) .executeUpdate(); //벌크연산 실행createQuery()- 해당 메서드에 ‘벌크 연산을 할 네이티브 SQL’을 전달한다.
- 단순히 네이티브 SQL 자체를 수행하려면,
createNativeQuery()를 사용함에 주의하자.
executeUpdate()- 벌크연산을 실행한다.
- 이때, 벌크 연산의 영향을 받은 엔티티의 건수를 반환한다.
-
DELETE 벌크연산: 가격이 100원 미만인 상품을 삭제하기
//네이티브 쿼리 String qlString = "delete from Product p " + "where p.price < :price"; int resultCount = em.createQuery(qlString) .setParameter("price", 100) .executeUpdate(); //벌크연산 실행- Delete 쿼리도
executeUpdate()메서드를 사용하여 벌크 연산을 수행한다.
- Delete 쿼리도
- INSERT 벌크 연산: 하이버네이트 종속 기능
- JPA 표준은 아니지만, 하이버네이트는
INSERT벌크 연산도 지원한다. -
100원 미만의 모든 상품을 선택해서 ProductTemp에 저장하기
//네이티브 쿼리 String qlString = "insert into ProductTemp(id, name, price, stockAmount) " + "select p.id, p.name, p.price, p.stockAmount from Product p " + "where p.price < :price"; int resultCount = em.createQuery(qlString) .setParameter("price", 100) .executeUpdate(); //벌크연산 실행
- JPA 표준은 아니지만, 하이버네이트는
벌크 연산 시 주의점
- 벌크 연산은 영속성 컨텍스트를 무시하고, DB에 직접 쿼리한다.
-
예시 코드
//----- JPQL ----- //상품A 조회 (상품A의 가격은 1000원이다.) Product productA = em.createQuery("select p from Product p where p.name = :name", Product.class) .setParameter("name", "productA") .getSingleResult(); //이때, productA는 영속상태이다. //출력결과: 1000 System.out.println("productA 수정 전 = " + productA.getPrice()); //----- 벌크 연산 ----- //모든 상품 가격 10% 상승 em.createQuery("update Product p set p.price = p.price * 1.1") .executeUpdate(); //출력결과: 1000 System.out.println("productA 수정 후 = " + productA.getPrice());- 가격이 1000원인 상품A를 조회했다. 조회된 상품A는 영속성 컨텍스트에서 관리된다.
- 벌크 연산으로 모든 상품의 가격을 10% 상승시켰다. 따라서 상품A의 가격은 1100원이 되어야 한다.
- 벌크 연산을 수행한 후에 상품A의 가격을 출력하면 기대했던 1100원이 아닌, 1000원이 그대로 출력된다.
- 왜냐하면 벌크 연산 시, 영속성 컨텍스트를 고려하지 않고 DB에 직접하여 값을 수정했기 때문이다.
- 시각화
-
벌크 연산 직전 상태
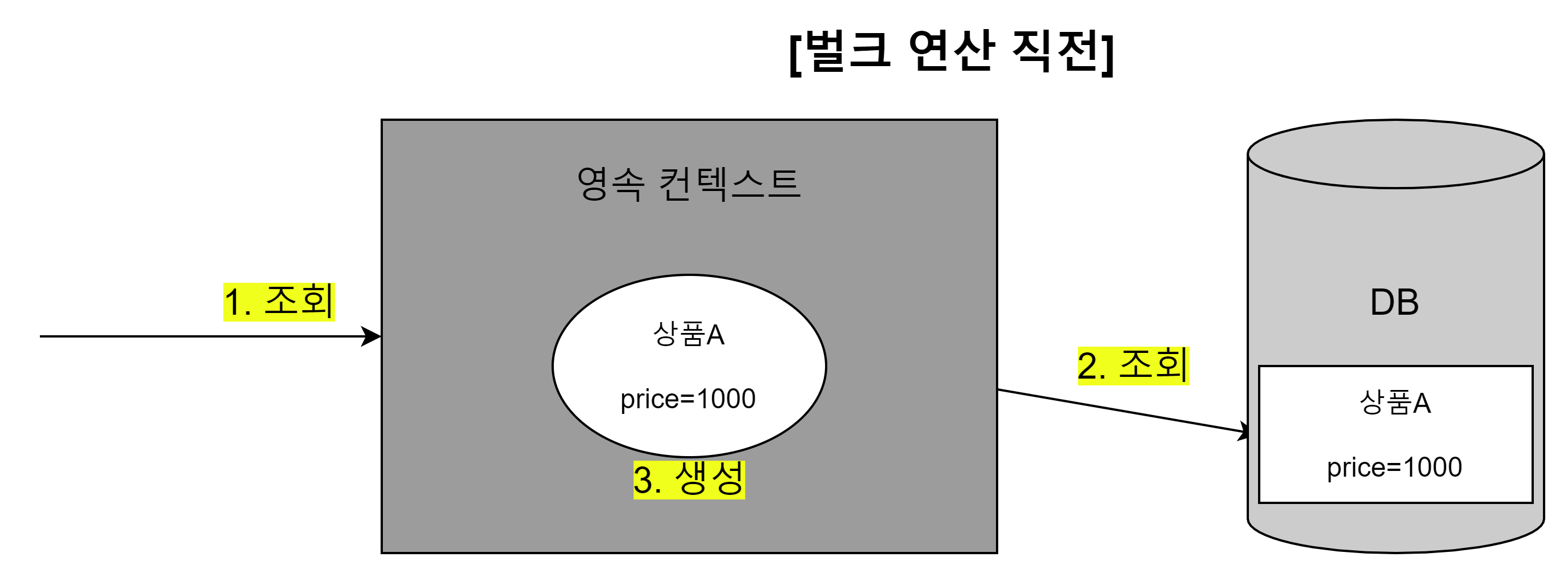
-
벌크 연산 상태
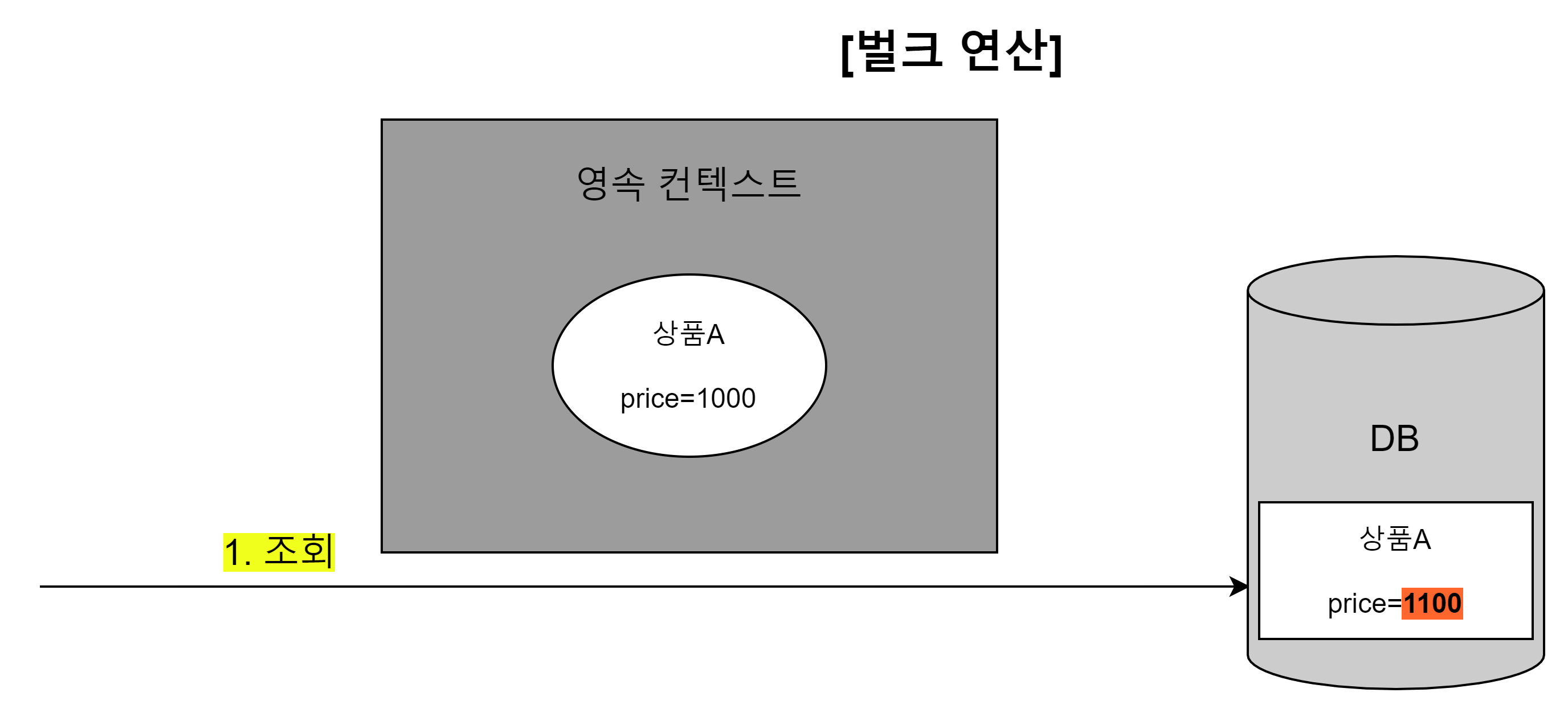
-
벌크 연산 문제점 해결방법들
em.refresh()사용- 벌크 연산을 수행한 직후에 정확인 상품A 엔티티를 사용해야 한다면,
em.refresh()를 사용해서 DB에서 상품A를 다시 조회하면 된다.
em.refresh(productA);- 벌크 연산을 수행한 직후에 정확인 상품A 엔티티를 사용해야 한다면,
- 벌크 연산 먼저 실행
- 벌크 연산을 가장 먼저 실행하여, 문제를 방지할 수 있다.
- 예시
- 벌크 연산으로 상품A의 가격을 변경한 뒤 상품A를 조회하면, 벌크 연산으로 이미 변경된 상품A를 조회하게 된다.
- 벌크 연산 수행 후 영속성 컨텍스트 초기화
- 벌크 연산을 수행한 직후에 바로 영속성 컨텍스트를 초기화해서, 영속성 컨텍스트에 남아 있는 엔티티를 제거하는 것도 좋은 방법이다.
- 영속성 컨텍스트를 초기화하면, 이후 엔티티를 조회할 때 벌크 연산이 적용된 DB에서 엔티티를 조회한다.
- 정리
- 가능하면 벌크 연산을 가장 먼저 수행하는 것이 좋고, 상황에 따라 영속성 컨텍스트를 초기화하자.
영속성 컨텍스트와 JPQL
쿼리 후 영속 상태인 것과 아닌 것
- JPQL로 엔티티를 조회하면 영속성 컨텍스트에서 관리된다.
- 하지만 엔티티가 아니면 영속성 컨텍스트에서 관리되지 않는다.
select m from Member m //엔티티 조회 (관리O)
select o,address from Order o //임베디드타입 조회 (관리X)
select m.id, m.username from Member m //단순 필드 조회 (관리X)
참고로 임베디드 타입을 프로젝션으로 지정하고 조회하여 반환된 객체의 값을 변경해도, flush 시 변경내용이 반영되지 않는다.
임베디드 타입은 영속성 컨텍스트에서 관리되지 않아, Dirty Checking 되지 않기 때문이다.
- 조회한 엔티티만 영속성 컨텍스트가 관리한다.
JPQL로 조회한 엔티티와 영속성 컨텍스트
-
만약 영속성 컨텍스트에 회원1이 이미 있는데, JPQL로 회원1을 다시 조회하면 어떻게 될까?
//회원1 조회 em.find(Member.class, "member1"); //member1이 영속성 컨텍스트의 관리를 받음 //엔티티 쿼리 조회 결과가 회원1, 회원2이다. List<Member> resultList = em.createQuery("select m from Member m", Member.class) .getResultList();
</br>
- ‘JPQL로 DB에서 조회한 엔티티’가 영속성 컨텍스트에 이미 있으면
- ‘JPQL로 DB에서 조회한 결과’를 버리고, 대신에 영속성 컨텍스트에 있던 엔티티를 반환한다.
- 그리고 이때, ‘JPQL로 DB에서 조회한 결과의 식별자’와 ‘영속성 컨텍스트가 관리하는 엔티티의 식별자’를 비교하여 같은 엔티티임을 확인한다.
- 결과 시각화
-
JPQL를 통한 조회 시도
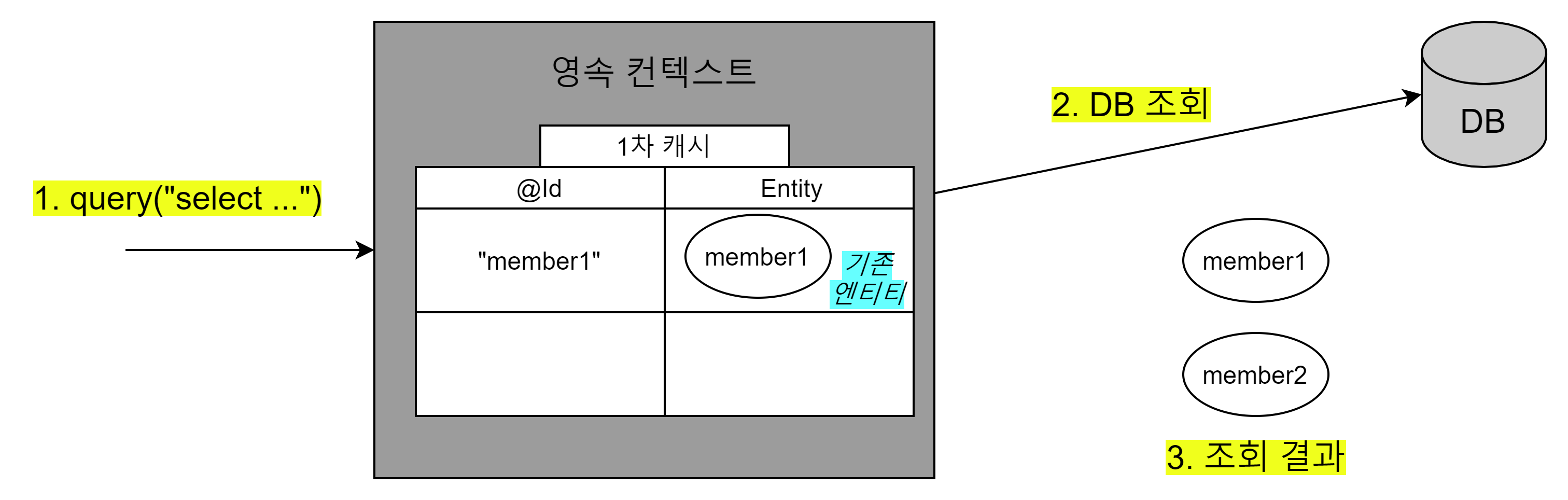
-
JPQL를 통한 조회 결과
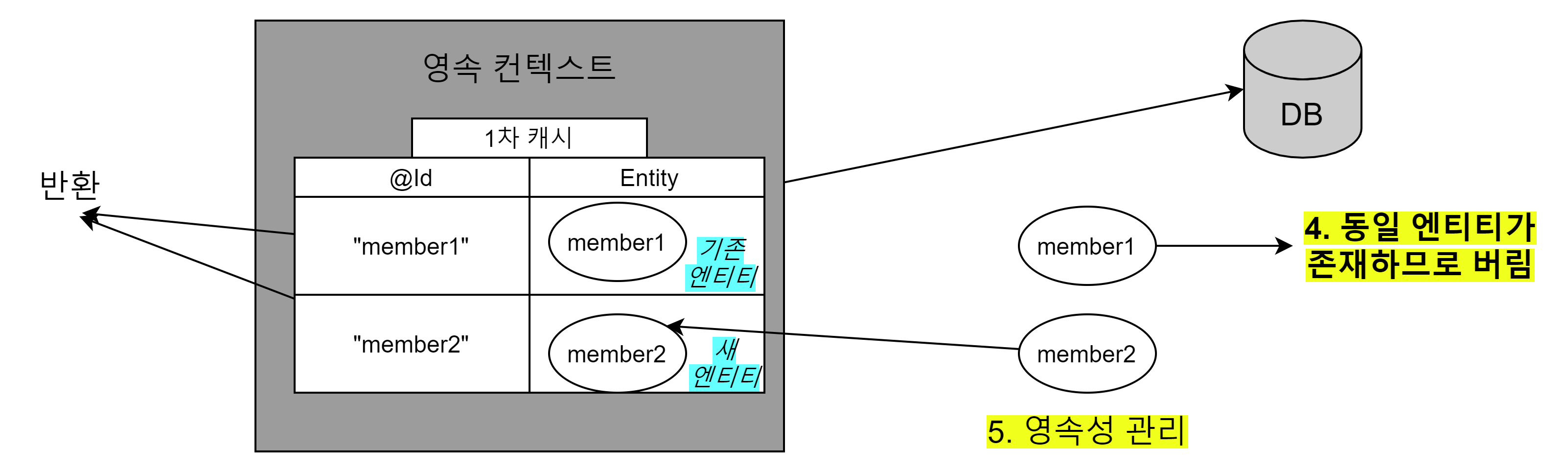
-
- 흐름 순서
- JPQL을 사용해서 조회를 요청한다.
- JPQL은 SQL로 변환되어 DB를 조회한다.
- 조회한 결과와 영속성 컨텍스트를 비교한다.
- 식별자 값을 기준으로
member1은 이미 영속성 컨텍스트에 있으므로, 조회된 결과를 버리고 기존에 있던member이 반환된다. - 식별자 값을 기준으로
member2는 영속성 컨텍스트에 없으므로 영속성 컨텍스트에 추가한다. - 쿼리 결과인
member1,member2를 반환한다. 여기서member1은 쿼리 결과가 아닌 영속성 컨텍스트에 있던 엔티티다.
- 이를 통해 알 수 있는 사실
- JPQL로 조회한 엔티티는 영속 상태이다.
- 영속성 컨텍스트에 이미 존재하는 엔티티가 있으면 기존 엔티티를 반환한다.
새로 조회한 결과를 버리고, 영속성 컨텍스트에 존재하는 기존의 엔티티를 반환하는 이유에 대해 알아보자.
기존 엔티티를 반환하는 방식 말고, 어떻게 할 수 있을지 생각해보면 아래와 같다.
- 새로운 엔티티를 영속성 컨텍스트에 하나 더 추가하는 방법
- 영속성 컨텍스트는 기본 키 값을 기준으로 엔티티를 관리한다. 따라서 같은 기본 키 값을 가진 엔티티는 등록할 수 없다.
- 따라서 사용할 수 없는 방법이다.
- 기존 엔티티를 새로 검색한 엔티티로 대체하는 방법
- 영속성 컨텍스트에 수정 중인 데이터가 사라질 수 있으므로 위험하다.
- 따라서 사용할 수 없는 방법이다.
위에서 설명한 방법들은 모두 불가능한 방법들이다. 따라서 JPA는 “기존 엔티티는 그대로 두고 새로 검색한 엔티티를 버리는 방법”을 채택했다.
find() vs JPQL
em.find()메서드는 엔티티를 영속성 컨텍스트에서 먼저 찾고, 없으면 DB에서 찾는다.- 따라서 해당 엔티티가 영속성 컨텍스트에 있으면 메모리에서 바로 찾으므로 성능상 이점이 있다.
따라서 1차 캐시하고 부른다.
//최초 조회, DB에서 조회 Member member1 = em.find(Member.class, 1L); //두번째 조회, 영속성 컨텍스트에 있으므로 DB 조회X Member member2 = em.find(Member.class, 1L); // member1 == member2 => true
-
JPQL은 어떤 방식으로 동작할까?
//첫번째 호출: DB에서 조회 Member member1 = em.createQuery("select m from Member m where m.id = :id", Member.class) .setParameter("id", 1L) .getSingleResult(); //두번째 호출: DB에서 조회 Member member2 = em.createQuery("select m from Member m where m.id = :id", Member.class) .setParameter("id", 1L) .getSingleResult(); // member1 = member2 => true!- 첫번째 JPQL 호출
- DB에서 회원 엔티티를 조회하고 영속성 컨텍스트에 등록한다.
- 두번째 JPQL 호출
- DB에서 같은 회원 엔티티를 조회하고, 결과를 버리고 기존 엔티티를 반환한다.
- 첫번째 JPQL 호출
- 상세 설명
- JPQL은 항상 DB에 SQL을 실행해서 결과를 조회한다.
em.find()메서드는 영속성 컨텍스트에서 엔티티를 먼저 찾고, 없으면 DB를 조회한다.- JPQL은 DB를 먼저 조회한다. 그리고 결과가 영속성 컨텍스트에 있으면 결과를 버리고 기존 엔티티를 반환한다.
- 그렇기 때문에, JPQL 역시
member1 == member2가 true이다.
- 그렇기 때문에, JPQL 역시
- 정리
- JPQL은 항상 DB를 조회한다.
- JPQL로 조회한 엔티티는 영속 상태이다.
- 영속성 컨텍스트에 이미 존재하는 엔티티가 있으면, 기존 엔티티를 반환한다.
JPQL과 플러시 모드
플러시란?
- 영속성 컨텍스트의 변경 내역을 DB에 동기화하는 것
- 플러시가 일어날 때, 영속성 컨텍스트에 등록, 수정, 삭제한 엔티티를 찾아서 INSET, UPDATE, DELETE SQL을 만들어 DB에 반영한다.
- 커밋하기 직전이나, 쿼리 실행 직전에 자동으로 플러시가 호출된다.
- 플러시 옵션
em.setFlushMode(FlushModeType.AUTO);- 커밋 또는 쿼리 실행 시, 먼저 플러시
- 기본값
em.setFlushMode(FlushModeType.COMMIT);- 커밋시에만 플러시
쿼리와 플러시 모드
- JPQL을 실행하기 전에 영속성 컨텍스트의 내용을 DB에 반영해야 한다.
- JPQL은 영속성 컨텍스트에 있는 데이터를 고려하지 않고, DB에 직접 접근하기 때문에
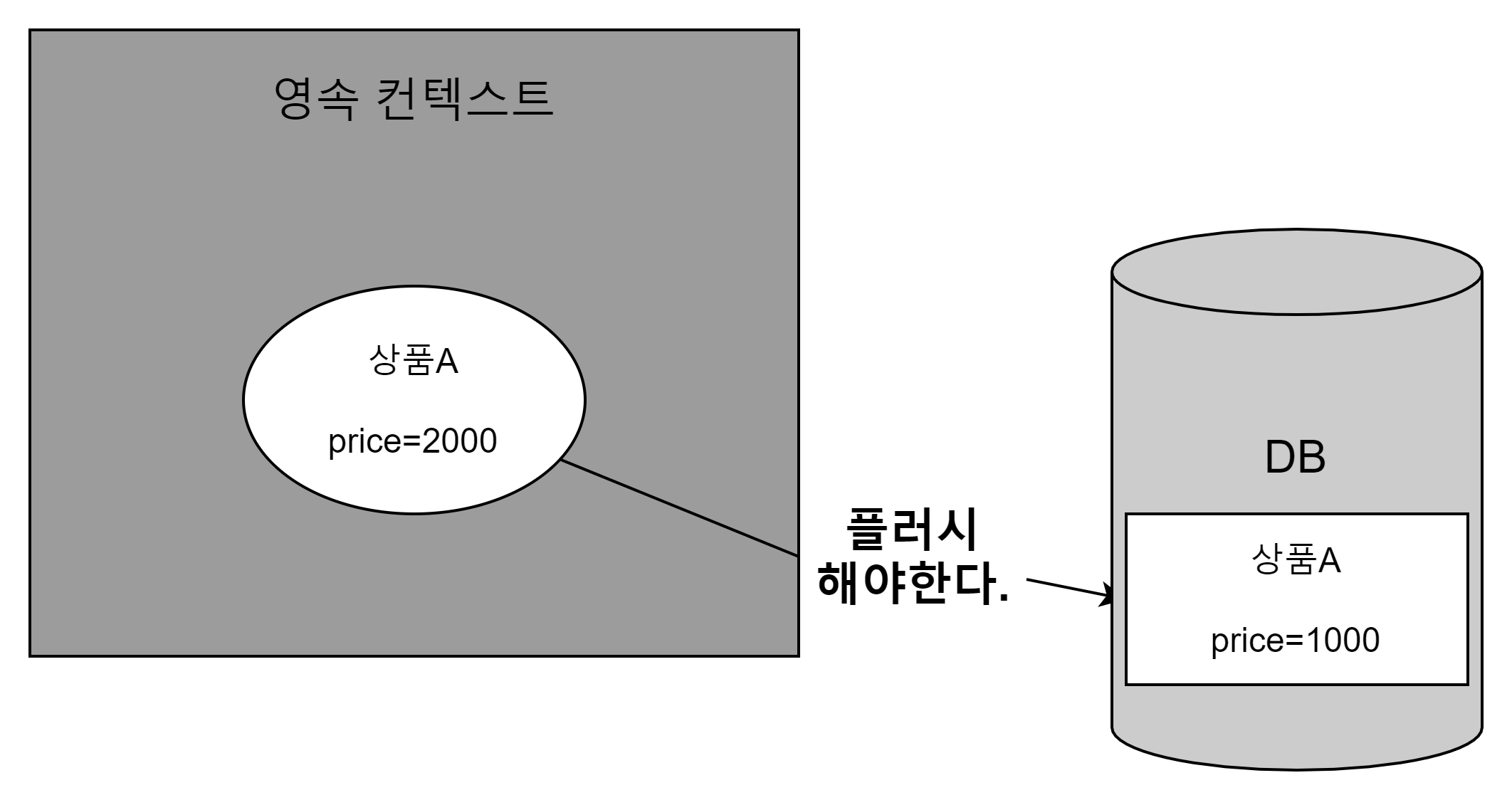
-
다음 예제 코드를 보자.
//가격을 1000 -> 2000원으로 변경 product.setPrice(2000); //가격이 2000원인 상품 조회 (JPQL) Product product2 = em.createQuery("select p from Product p where p.price = 2000", Product.class) .getSingleResult();product.setPrice(2000)- 해당 메서드를 호출하면, 영속성 컨텍스트의 상품 엔티티는 가격이 1000원에서 2000원을 변경된다.
- DB에서는 아직 1000원인 상태로 남아있다.
- JPQL 호출 시
- 가격이 2000원인 상품을 조회한다.
- 이때 플러시 모드를 따로 설정하지 않으면 플러시 모드가
AUTO이다. - 따라서 쿼리 실행 직전에 영속성 컨텍스트가 플러시된다.
- 결국 2000원으로 수정한 상품을 조회할 수 있다.
- 위 예시에서 플러시 모드는
COMMIT으로 설정하면, 쿼리시에는 플러시되지 않는다.- 따라서 2000원으로 수정한 상품을 조회할 수 없다.
플러시 모드와 최적화
FlushModeType.COMMIT모드는 트랜잭션을 커밋할 때만 플러시하고, 쿼리를 실행할 때는 플러시하지 않는다.- 따라서 JPA 쿼리를 사용할 때, 영속성 컨텍스트에는 있지만 아직 DB에 반영하지 않은 데이터를 조회할 수 없다.
- 그렇다면
COMMIT플러시 모드는 왜 사용할까?-
아래와 같이 플러시가 너무 자주 일어나는 상황에
COMMIT모드를 사용하면, 쿼리시 발생하는 플러시 횟수를 줄여서 성능을 최적화할 수 있다.//비즈니스 로직 등록() 쿼리() // 쿼리 전, 먼저 플러시한다. 등록() 쿼리() // 쿼리 전, 먼저 플러시한다. 등록() 쿼리() // 쿼리 전, 먼저 플러시한다. 커밋() // 이때도 먼저 플러시한다.- 위 상황에서
FlushModeType.AUTO사용시: 쿼리와 커밋할 때, 총 4번 플러시한다. - 위 상황에서
FlushModeType.COMMIT사용시: 커밋할 때, 총 1번 플러시한다.
- 위 상황에서
-
- 또한 JPA를 사용하지 않고, JDBC를 직접 사용해서 SQL을 실행할 때도 플러시 모드를 고민해야 한다.
- JDBC로 쿼리를 직접 실행하면 JPA는 JDBC가 실행한 쿼리를 인식할 방법이 없다.
- 따라서 별도의 JDBC 호출은 플러시 모드를 AUTO로 설정해도 플러시가 일어나지 않는다.
- 이때는 JDBC로 쿼리를 실행하기 직전에,
em.flush()를 호출해서 영속성 컨텍스트의 내용을 DB에 동기화하는 것이 안전하다.
- 김영한, 『자바 ORM 표준 JPA 프로그래밍』, 에이콘