
최근에 DB에서 페이징을 하는 방법에 대해 복기를 하다가, 무한 스크롤과 페이지네이션에 대해 과거에 정리했던 포스팅을 다시 읽게 되었습니다.
관련 글은 Cursor Pagination 과 무한 스크롤 을 참고하시면 됩니다.
해당 글에서는 ‘무한 스크롤 구현시, 데이터가 중복될 수 있는 문제’만을 중점적으로 다루고, 추후에 ‘성능 관련 문제’에 대한 이야기도 포스팅하겠다고 했습니다. 거의 8개월이 지난 지금, 그 이야기를 해보고자 합니다…
가장 먼저, 페이징 처리의 기본인 LIMIT-OFFSET 방식을 사용했을 때의 성능을 확인해보고, 이때 발생하는 문제를 어떻게 해결하면 좋을지 설명하도록 하겠습니다.
사전 Set Up
아래는 이번 포스팅에서 사용하게 될 테이블입니다.
CREATE TABLE `PERSON` (
`ID` int NOT NULL AUTO_INCREMENT,
`NAME` varchar(256) DEFAULT NULL,
`UPDATE_TIMESTAMP` timestamp(6),
PRIMARY KEY (`ID`)
);
이 테이블에는 약 4,000만개의 Row가 저장되어 있습니다.
LIMIT-OFFSET 방식의 문제점
우리가 페이징 처리를 하기 위해 흔히 사용하는 LIMIT-OFFSET 방식은 OFFSET 값만큼의 Row를 읽은 후, LIMIT 값만큼의 Row를 가져오는 방식으로 동작합니다.
따라서 단순한 서비스에서는 별 문제가 되지 않지만, 많은 Row가 저장되어 있는 테이블에서 OFFSET 의 값을 매우 크게 설정하면 심각한 성능 저하 문제가 발생하게 됩니다.
그럼 실제로 테스트해봅시다.
OFFSET 값이 작은 경우
SELECT * FROM PERSON LIMIT 3 OFFSET 10;
위와 같이 OFFSET 값을 10으로 설정하면 약 0.3ms 만에 결과를 얻을 수 있습니다.
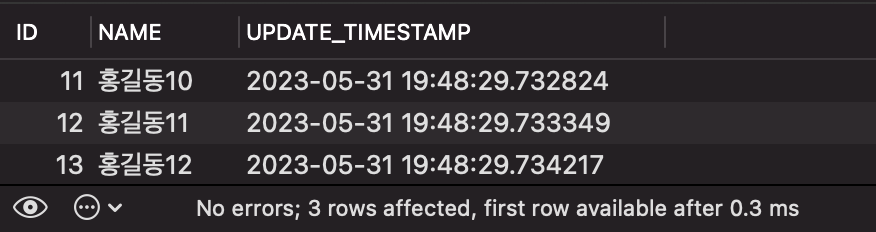
이 경우에는 속도가 충분히 빠르기 때문에 별 문제가 되지 않습니다. 그럼 OFFSET 값이 클 땐 어떨까요?
OFFSET 값이 큰 경우
SELECT * FROM PERSON LIMIT 3 OFFSET 39000000;
위와 같이, OFFSET 값을 3,900만으로 매우 크게 설정했습니다.
그 결과는 아래와 같습니다.
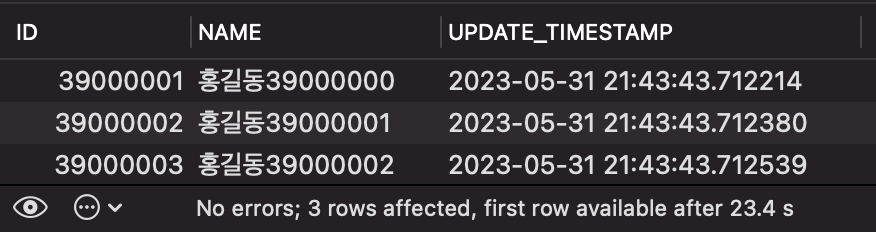
약 23s 만에 결과를 얻었습니다. 쿼리 하나를 실행하는데 23초가 걸린다면 정상적인 서비스 운영이 힘들겠죠?
이 문제를 해결하는 방법에는 크게 두 가지가 있습니다.
- 아예
OFFSET을 사용하지 않는 방식 →NO-OFFSET방식- 성능적으로 가장 우수
- 하지만 반드시
OFFSET를 사용해야 하는 경우엔 사용 불가능
OFFSET을 사용하되, 인덱스가 적용된 칼럼만을 활용하는 방식 → 커버링 인덱스 방식NO-OFFSET에 비해선 다소 오래 걸림- 하지만
OFFSET활용 가능
그럼 각 방법에 대해 자세히 알아보겠습니다.
NO-OFFSET 방식으로 성능 개선
LIMIT-OFFSET 에서 성능 저하를 유발하는 가장 큰 원인이 바로 OFFSET 입니다.
NO-OFFSET 방식은 아예 OFFSET 을 사용하지 않음으로써 성능을 개선합니다. 사용 방법은 아래와 같습니다.
SELECT * FROM [TABLE_명] WHERE [건너뛸_기준_칼럼] > [건너뛸_기준_값] LIMIT [출력할_개수]
여기서 핵심은 OFFSET 대신 WHERE 을 사용했다는 점입니다. WHERE 조건에 ID 칼럼을 집어넣어서 조회해보겠습니다.
실행할 쿼리는 아래와 같습니다.
SELECT * FROM PERSON WHERE ID > 39000000 LIMIT 3;
결과는 아래와 같습니다.
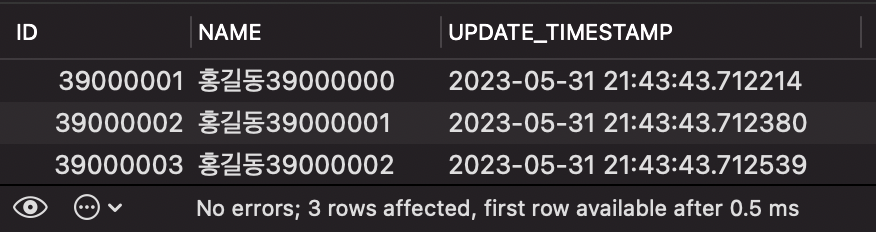
조회한 결과가 LIMIT-OFFSET 방식과 동일하게 나타났음에도, 수행 시간은 고작 0.5ms 밖에 소요되지 않았습니다.
이처럼 OFFSET 대신 WHERE 을 사용해서 건너뛸 기준을 설정하여 페이징하는 것을 커서 기반 페이징 이라고 합니다.
커서 기반 페이징을 통해서 성능을 극적으로 개선할 수 있지만 이때, WHERE 에 사용되는 칼럼에 Index가 적용되어야 한다는 조건이 있습니다.
우리는 기본적으로 인덱스가 적용되어 있는 칼럼 ID 를 WHERE 조건으로 사용했기 때문에, 성능을 개선시킬 수 있었던 것입니다.
(ID 칼럼이 PK이므로, 클러스터 인덱스)
그럼 인덱스가 적용되지 않은 칼럼을 WHERE 에 활용하면 어떻게 될까요?
인덱스를 타지 않고, NO-OFFSET 적용
실행할 쿼리는 아래와 같습니다.
SELECT * FROM PERSON WHERE UPDATE_TIMESTAMP >= '2023-05-31 21:43:43.712214' LIMIT 3;
현재 테이블의 UPDATE_TIMESTAMP 칼럼에는 인덱스가 적용되어 있지 않습니다. 이 경우에도, LIMIT-OFFSET 방식보다 효과적까요?
그 결과는 아래와 같습니다.
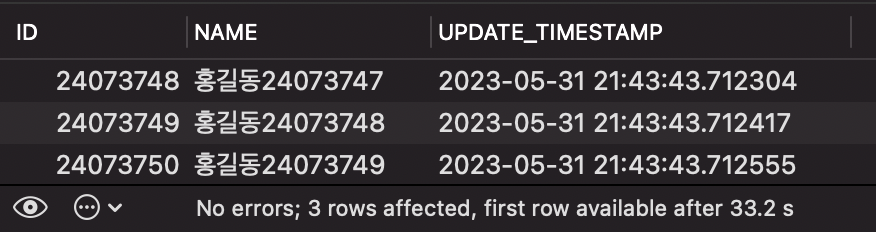
총 수행시간이 약 33초로, 기존 LIMIT-OFFSET 방식보다 오히려 더 오래 걸렸음을 확인해볼 수 있습니다.
EXPLAIN 을 통해, 실행계획을 살펴보면 아래와 같습니다.

type 을 확인해보면, ALL 을 갖는 것을 볼 수 있습니다. 즉, 테이블의 전체 데이터를 스캔한다는 의미입니다. 따라서, 성능 개선을 기대해볼 수 없습니다.
그러면 이번에는 UPDATE_TIMESTAMP 에 인덱스를 적용하고, 다시 동일한 쿼리를 실행해보겠습니다.
-- 인덱스 생성
CREATE INDEX timestamp_index ON PERSON(`UPDATE_TIMESTAMP`);
-- 다시 동일한 쿼리로 조회
SELECT * FROM PERSON WHERE `UPDATE_TIMESTAMP` >= '2023-05-31 21:43:43.712214' LIMIT 3;
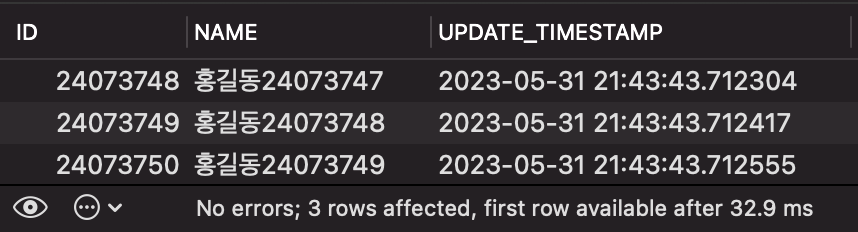
인덱스를 적용하고 나니, 실행시간이 약 33ms 로 매우 크게 단축됐습니다.
실행계획을 살펴볼까요?

실제로 인덱스를 활용한 것을 확인해볼 수 있습니다.
따라서 단순히 WHERE 절을 사용하는 것이 아니라, 반드시 인덱스를 활용해야 한다는 것을 알 수 있습니다.
정확한 페이징 결과를 얻으려면
WHERE절에 사용될 칼럼이 유니크한 값으로 구성되어야 합니다.
자세한 것은 Cursor Pagination 과 무한 스크롤 포스팅의 ‘Cursor Pagination 의 한계 부분’ 을 참고하세요.
그리고
Extra항목의 값으로Using index가 아닌Using index condition이 들어왔는데,Using index condition이 무엇인지는 추후에 포스팅하겠습니다.
혹은 개발자 이동욱님의 블로그 글을 참고하셔도 좋습니다.
LIMIT-OFFSET vs NO-OFFSET 결론
지금까지의 테스트를 통해, 얻을 수 있는 결론은 아래와 같습니다.
LIMIT-OFFSET방식은OFFSET까지 데이터를 살펴봐야하기 때문에,OFFSET값이 크다면 매우 불리해진다.WHERE로 건너뛸 Row를 설정해서 페이징하는NO-OFFSET방식, 즉 커서 기반 페이징 방식을 도입하여 성능 개선을 이뤄낼 수 있다.WHERE절에 사용될 칼럼은 인덱스가 적용되어 있어야 한다.
하지만, 이 NO_OFFSET 방식에도 단점은 존재합니다.
만약 비즈니스 기획상 반드시 OFFSET 을 사용해야 하는 상황이라면, NO-OFFSET 을 사용할 수는 없습니다. 이 경우엔, 어떻게 성능을 개선해야 할까요?
예를 들어, n번째 Row를 한번에 조회해야하는 경우
이럴 때 사용할 수 있는 방법은 바로 ‘커버링 인덱스를 활용하는 것’입니다.
커버링 인덱스를 활용한 페이징
커버링 인덱스란?
본격적인 페이징 방법에 대해 알아보기 전에, 먼저 커버링 인덱스가 무엇인지 알아봅시다.
커버링 인덱스는 쿼리에 사용되는 모든 칼럼을 가지고 있는 인덱스를 의미합니다. 즉, 한 쿼리의 SELECT , WHERE , ORDER BY , GROUP BY 등에서 사용되는 모든 칼럼이 한 인덱스의 구성요소라면, 이것을 커버링 인덱스라고 합니다.
예를 들어, 아래와 같은 쿼리가 있다고 해봅시다.
SELECT NAME FROM SOME_TABLE WHERE AGE > 20 ORDER BY HEIGHT;
이때 아래와 같은 인덱스가 존재한다면, 위 쿼리는 커버링 인덱스를 활용해 실행된다고 이야기할 수 있습니다.
CREATE INDEX my_index ON SOME_TABLE(NAME, AGE, HEIGHT);
커버링 인덱스를 사용했을 때의 이점
OFFSET 을 사용하더라도 커버링 인덱스를 활용하면 성능 향상이 가능하다고 하는데, 어떻게 가능한 것일까요?
그 이유는 아래와 같습니다.
- 커버링 인덱스를 사용하면, ‘실제 데이터 접근’ 없이 ‘인덱스 데이터’만으로 결과를 만들어낼 수 있다.
- 실제 데이터에 접근할 때 발생하는 오버헤드를 제거할 수 있기 때문에,
OFFSET을 사용해 조회하는 최종 수행시간이 줄어든다.
커버링 인덱스를 사용했을 때 어떻게 오버헤드가 줄어드는 것인지를 이해하기 위해서는, 먼저 DB가 인덱스를 사용해서 Row를 조회할 때 어떤 식으로 동작하는지 알아야 합니다.
MySQL(MariaDB)를 기준으로 설명하겠습니다.
인덱스의 종류
아래는 인덱스의 종류와 특징에 대해 정리한 표입니다. 혹시 필요하시면 참고하시기 바랍니다.
| 인덱스 종류 | 대상 | 특징 |
|---|---|---|
| Clustered Index | 아래 우선순위 별로 설정됨 1. Primary Key 2. Unique Key 3. Hidden Key (Row ID) |
- 테이블당 오직 1개만 존재 - 테이블 그 자체를 나타냄 - 데이터(단말노드)에는 모든 칼럼이 포함됨 |
| Non-Clustered Index | 직접 지정한 칼럼 | 테이블당 여러개 존재 가능 |
DB가 인덱스를 통해 조회하고, 데이터를 가져오는 과정
MySQL(MariaDB)는 인덱스를 사용해서 데이터를 조회할 때, 어떻게 데이터를 가져오게 되는 것일까요?
아래 쿼리를 예시로 설명하겠습니다.
-- 인덱스 생성
CREATE INDEX age_index ON SOME_TABLE(AGE);
-- 조회 쿼리
SELECT `NAME` FROM SOME_TABLE WHERE `AGE` = 41;
위와 같이 Non-Clustered 인덱스(age_index)를 생성해두고, SELECT 쿼리를 실행하면, DB는 내부적으로 아래와 같이 동작하게 됩니다.
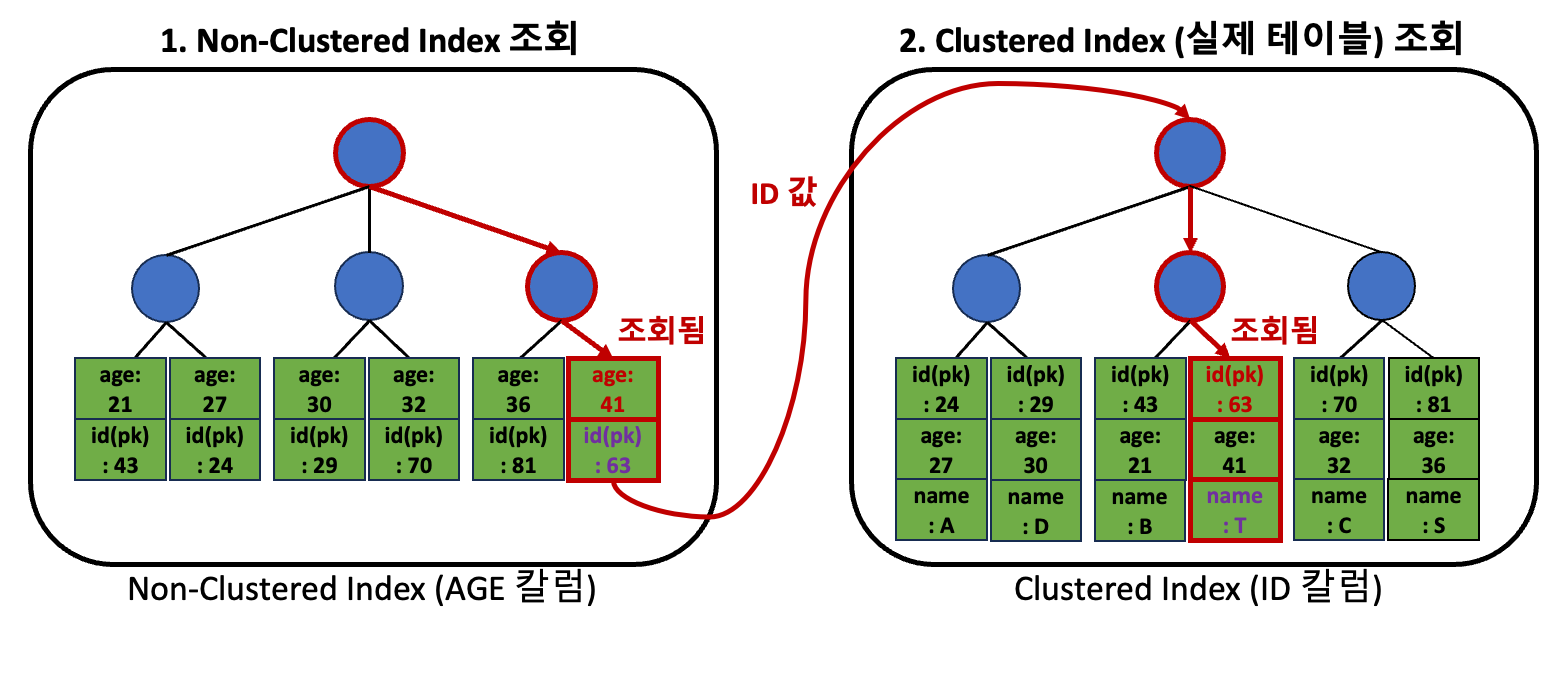
-
가장 먼저, ‘
WHERE조건에 사용된AGE칼럼’이 존재하는 인덱스 중 하나를 선택한다.
그리고 해당 인덱스에서 조건을 만족하는 데이터(AGE = 41)를 찾는다.모든 Non-Clustered 인덱스에는 직접 설정한 칼럼뿐만 아니라, 기본키 칼럼까지 포함됩니다.
-
1번 과정에서 찾은 데이터의 PK에 해당하는
ID칼럼 값으로, 다시 Clustered Index 즉 실제 테이블을 조회한다. (ID = 63)
그리고 최종적으로 출력할 칼럼의 값(NAME)을 가져온다.
커버링 인덱스 사용해서, 성능 개선이 가능한 이유
만약 커버링 인덱스를 사용하게 되면, 위 과정 중 ‘2번 과정’이 생략되게 됩니다!
왜냐하면, 조회에 필요한 모든 칼럼의 정보가 ‘1번 과정’에서 사용하는 Non-Clustered 인덱스에 담겨있기 때문입니다.
그렇기 때문에, 성능이 개선될 수 있습니다.
아래와 같은 쿼리를 실행한다고 해보겠습니다. 이전과는 다르게 인덱스에 AGE 뿐만 아니라, NAME 칼럼까지 포함되어 있습니다.
-- 인덱스 생성 (커버링 인덱스로 활용)
CREATE INDEX age_index ON SOME_TABLE(`AGE`, `NAME`);
-- 조회 쿼리 (커버링 인덱스 활용)
SELECT `NAME` FROM SOME_TABLE WHERE `AGE` = 41;
조회 쿼리에서 사용된 모든 칼럼(NAME , AGE)으로 구성된 새로운 Non-Clustered 인덱스를 생성했습니다.
이 경우, 아래와 같이 동작하게 됩니다.
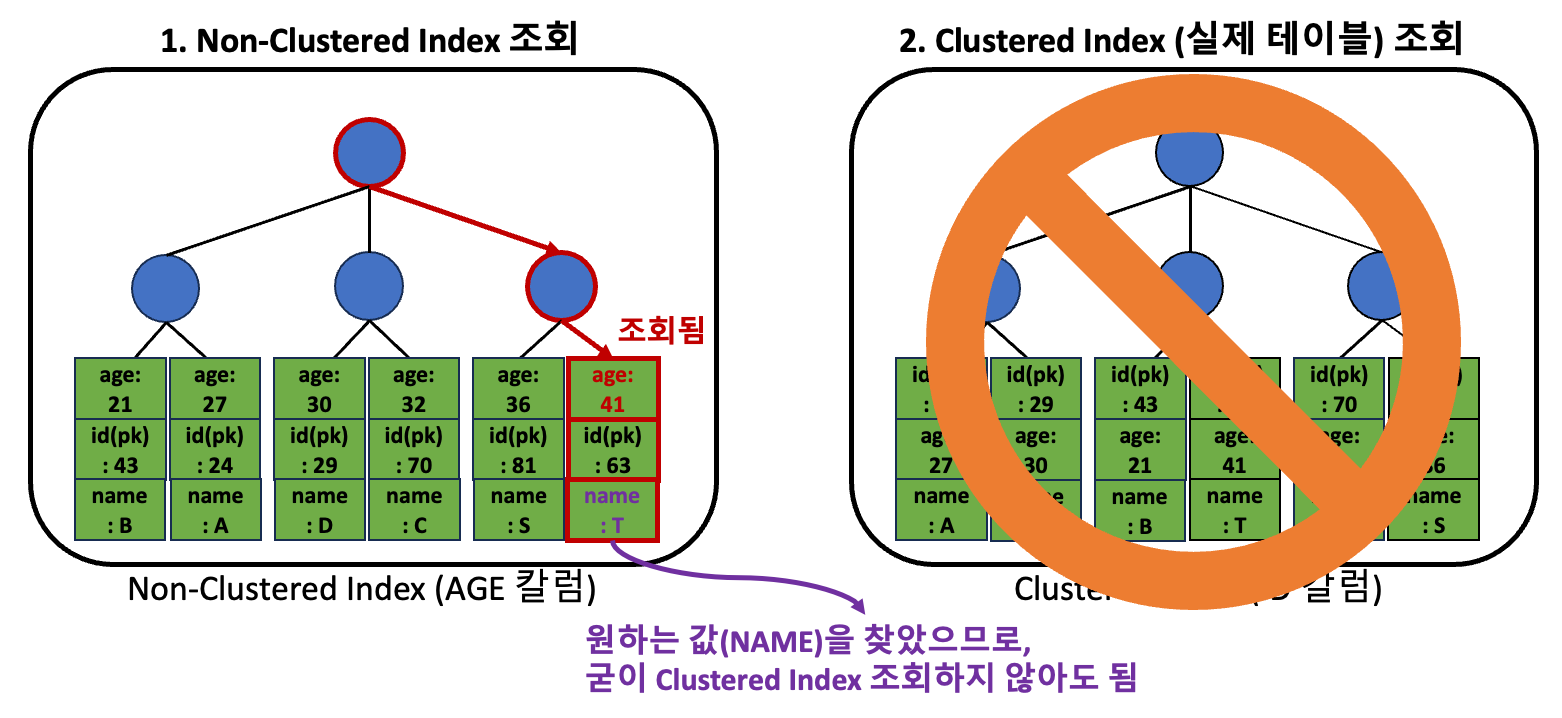
커버링 인덱스를 사용해서 페이징 처리하기
지금까지 커버링 인덱스가 무엇이고 어떤 원리로 조회 성능을 개선할 수 있는지 알아봤습니다.
커버링 인덱스와 함께 OFFSET 을 사용하면, OFFSET 만큼 데이터를 확인할 때 실제 데이터를 조회하지 않으므로 (즉, Clustered 인덱스를 다시 참조해서 조회하지 않으므로) 성능 개선을 기대할 수 있습니다.
그럼 직접 테스트해보도록 하겠습니다.
참고로 DB 테이블 상태는 이전에 NO-OFFSET 방식에서 사용했던 것과 동일합니다.
-- 인덱스 생성 (커버링 인덱스로 활용될 예정)
CREATE INDEX name_time_index ON PERSON(`NAME`, `UPDATE_TIMESTAMP`);
-- 다시 동일한 쿼리로 조회
SELECT `NAME`, `UPDATE_TIMESTAMP` FROM PERSON ORDER BY `NAME` ASC LIMIT 3 OFFSET 39000000;
위 쿼리를 실행하면, 아래와 같은 결과를 확인할 수 있습니다.
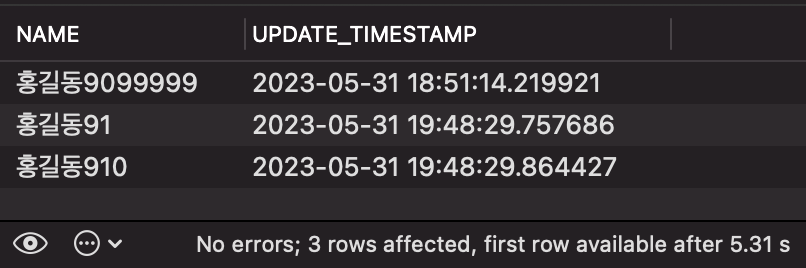
결과적으로 약 5초가 소요됐습니다. 인덱스 없이 조회했을 때 약 23초가 걸렸던 것에 비해, 5배 이상 개선된 것을 알 수 있습니다. (그래도 데이터가 너무 많아서 그런지 오래 걸리는 수준이기는 합니다. 어쨌든 성능이 개선됐다는 사실에 집중합시다!)
실행 계획까지 확인해볼까요?

Extra부분이 Using Index 라면, 커버링 인덱스가 사용된 것으로 보면 됩니다.
참고로,
Key항목에 인덱스 이름이 존재하면 인덱스를 사용한 것입니다. (Extra항목이Using index가 아니라도)
Extra항목이Using index라면, 오직 인덱스만을 사용해서 데이터를 가져왔다는 의미입니다.
만약 모든 칼럼의 값이 궁금하다면…?
지금까지 커버링 인덱스를 사용해서 OFFSET 의 성능을 개선할 수 있다고 했습니다.
그런데 만약 조회할 Row의 모든 칼럼을 확인하고 싶다면, 해당 테이블의 모든 칼럼을 가지고 있는 인덱스를 만들어야 하는 것일까요?
물론 그렇게 처리하는게 가능하긴 하지만, Row를 추가·업데이트할 때마다 너무 많은 오버헤드가 발생할 것이고, 컴퓨팅 자원도 너무 많이 필요하게 됩니다.
이럴땐 아래와 같은 방법을 사용하면 됩니다.
SELECT * FROM [테이블명] AS t1
JOIN (
[커버링 인덱스를 사용해 페이징하는 서브쿼리]
) AS t2
ON t1.ID = t2.ID;
가장 먼저 서브쿼리를 통해서 커버링 인덱스로 페이징을 진행합니다. 그리고 그 결과와 기존 테이블을 조인시켜서 ‘인덱스에 포함되지 않은 칼럼’을 가져옵니다.
조인을 사용해서 조회하는 경우와, 조인을 사용하지 않는 경우, 두 가지 모두 테스트해보도록 하겠습니다.
먼저 새로운 칼럼 HEIGHT 를 PERSON 테이블에 추가하도록 하겠습니다. (인덱스에 포함되지 않은 칼럼 추가)
ALTER TABLE PERSON ADD COLUMN HEIGHT int;
그리고 아래와 같이 조인 없이 조회해보겠습니다.
SELECT * FROM PERSON ORDER BY `NAME` ASC LIMIT 3 OFFSET 39000000;
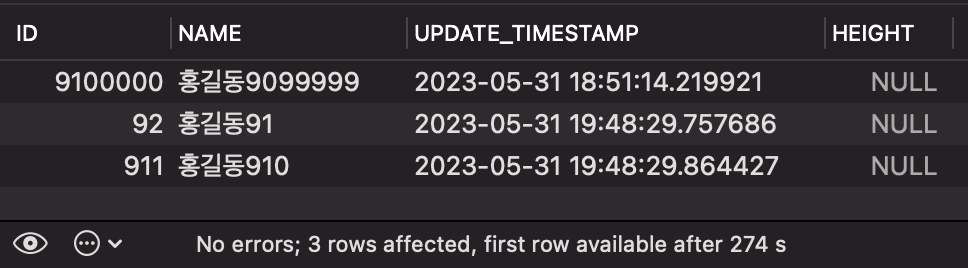
약 5분 정도가 걸려서 결과를 확인할 수 있습니다. 왜냐하면 커버링 인덱스가 적용되지 않아서, 테이블을 풀스캔했기 때문입니다.
실제 실행 계획을 살펴보면 아래와 같습니다.

그러면 이번에는 조인을 사용해서 전체 칼럼을 조회해보겠습니다.
SELECT * FROM PERSON p
JOIN (
SELECT `ID`, `NAME`, `UPDATE_TIMESTAMP` FROM PERSON ORDER BY `NAME` ASC LIMIT 3 OFFSET 39000000
) as sub
ON sub.`ID` = p.`ID`;
서브쿼리를 사용해서 커버링 인덱스를 활용하도록 했습니다. 즉, 서브쿼리의 결과는 실제 테이블 접근없이 인덱스만으로 만들어지게 됩니다. 그리고 서브쿼리의 결과와 실제 테이블을 조인시켰습니다.
그 결과는 아래와 같습니다.

아까와 동일한 데이터가 조회됐지만, 실행하는 데 오직 6초만이 소요됐습니다.
(역시 6초도 매우 오래 걸리는 수준이지만, 기존 5분에서 6초로 엄청난 시간단축이 가능해졌다는 것에 초점을 맞춥시다.)
실행 계획을 살펴보면 아래와 같습니다.

세번째 Row는 서브쿼리에 대한 실행 계획이고, 나머지는 메인 쿼리에 대한 실행 계획입니다.
먼저 서브쿼리 실행 계획을 살펴볼까요?
Extra 부분을 살펴보면 Using index 로 커버링 인덱스를 정상적으로 활용한 것을 볼 수 있습니다.
두번째 Row의 type 은 eq_ref 입니다. eq_ref 는 ‘조인에서 처음으로 읽은 테이블의 칼럼값’을 ‘두번째 테이블의 PK·Uni 칼럼’의 검색 조건에 사용할 때를 의미합니다.
즉, ‘서브쿼리 결과 칼럼 sub.ID 값’과 동일한 ‘메인쿼리 칼럼 p.ID 값’을 갖는 Row를 조회했다는 뜻입니다.
참고로,eq_ref 에서 두번째 테이블의 Clustered Index이 사용되고, 각 테이블의 칼럼이 한 종류만 사용되기 때문에 속도가 충분히 빠릅니다.
정리하며…
지금까지 DB의 페이지네이션을 어떻게 최적화할 수 있을지 정리해봤습니다.
내용을 다시 정리해보면…
- 기본적인 페이징 방식인
LIMIT-OFFSET의 비효율성OFFSET까지 데이터를 읽어야 해서 느림
- 이를 해결하기 위해,
NO-OFFSET과커버링 인덱스방식을 사용NO-OFFSET:OFFSET대신WHERE사용 (단, 조건으로 인덱스 사용)커버링 인덱스:OFFSET을 반드시 사용해야 한다면, 조회 쿼리의 모든 칼럼이 인덱스의 구성요소일 때 사용 가능
- 성능은
NO-OFFSET이 훨씬 좋음
저번 포스팅을 작성할 때와 마찬가지로, 페이지네이션을 너무 단순하게 생각했음을 깨닫게 되었습니다.
이 글을 보시는 모든 분들께 도움이 됐으면 좋겠습니다. 혹시 틀린 내용이 있다면 알려주세요. 감사합니다.