
이전 포스팅 DB 페이지네이션을 최적화하는 여러 방법들 을 작성하면서, 쿼리 실행 계획을 살펴보다가 Using index condition 이라는 키워드가 등장했습니다.
예를 들어, 아래와 같이 말이죠.

커버링 인덱스를 사용했을 때 나타나는 Using index 는 알고 있지만, Using index condition 은 무엇인지 몰랐습니다.
이에 대해 조사를 하다, ‘인덱스 컨디션 푸시다운(ICP)’ 와 연관이 있다는 것을 알게 되었습니다.
이번 포스팅에서는 이것이 무엇인지 정리해보도록 하겠습니다.
인덱스 컨디션 푸시다운 (ICP: Index Condition Pushdown)
쿼리의 실행 계획을 EXPLAIN 절을 통해 확인하다보면, Extra 항목에 Using index condition 이 등장하곤합니다. 이는 ‘인덱스 컨디션 푸시다운(ICP)’를 사용하는 경우 나타나게 됩니다.
그렇다면 인덱스 컨디션 푸시다운(이하 ICP)가 무엇일까요?
인덱스 컨디션 푸시다운(ICP)이란?
MySQL 5.6 버전 이상 (MariaDB 5.3 이상) 부터 등장한 최적화 기술입니다. 이를 통해서, 인덱스가 적용된 테이블에서 좀 더 효율적으로 데이터를 가져올 수 있게 되었습니다.
ICP는 MySQL의 InnoDB 와 MyISAM 엔진에서 지원합니다.
원래는 어떤 문제가 있었고, 이를 어떻게 해결하게 됐을까요?
이를 이해하기 위해선, 먼저 MySQL이 내부적으로 어떻게 구성되는지 알아야 합니다.
MySQL 엔진과 Storage 엔진
MySQL은 내부적으로 MySQL 엔진 과 Storage 엔진 으로 나누어져 있습니다.
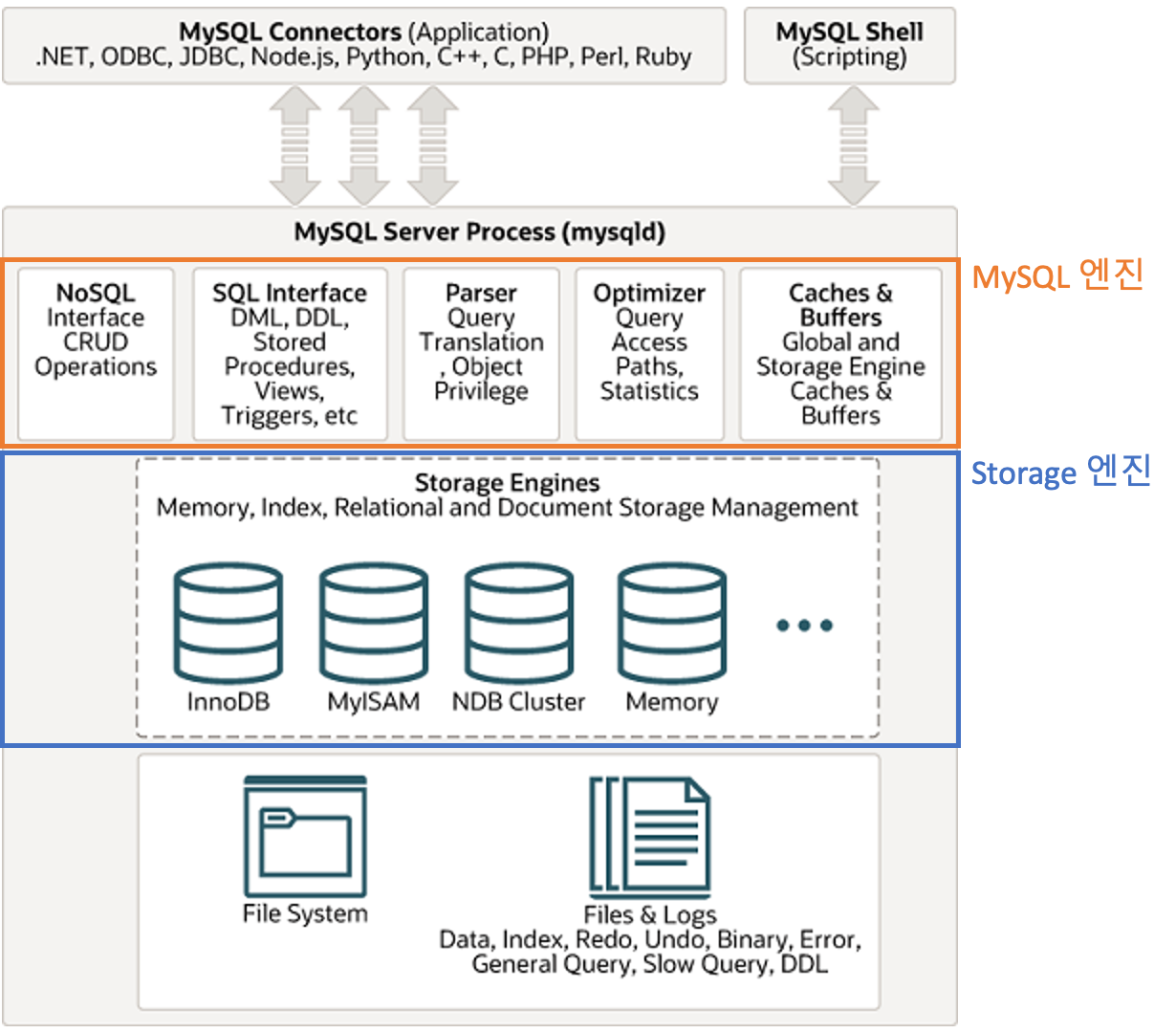
MySQL 엔진- SQL 쿼리를 분석하거나, 최적화하는 등의 역할을 수행합니다
Storage 엔진- 실제로 디스크에 접근해서 데이터를 읽거나 쓰는 작업을 수행합니다.
- InnoDB나 MyISAM 과 같은 엔진은 이 부분에 해당합니다.
그리고 MySQL 엔진 은 Storage 엔진 에서 미처 거르지 못한 데이터를 걸러주는 역할까지 수행해줍니다.
이를 그림으로 나타내면 아래와 같습니다.
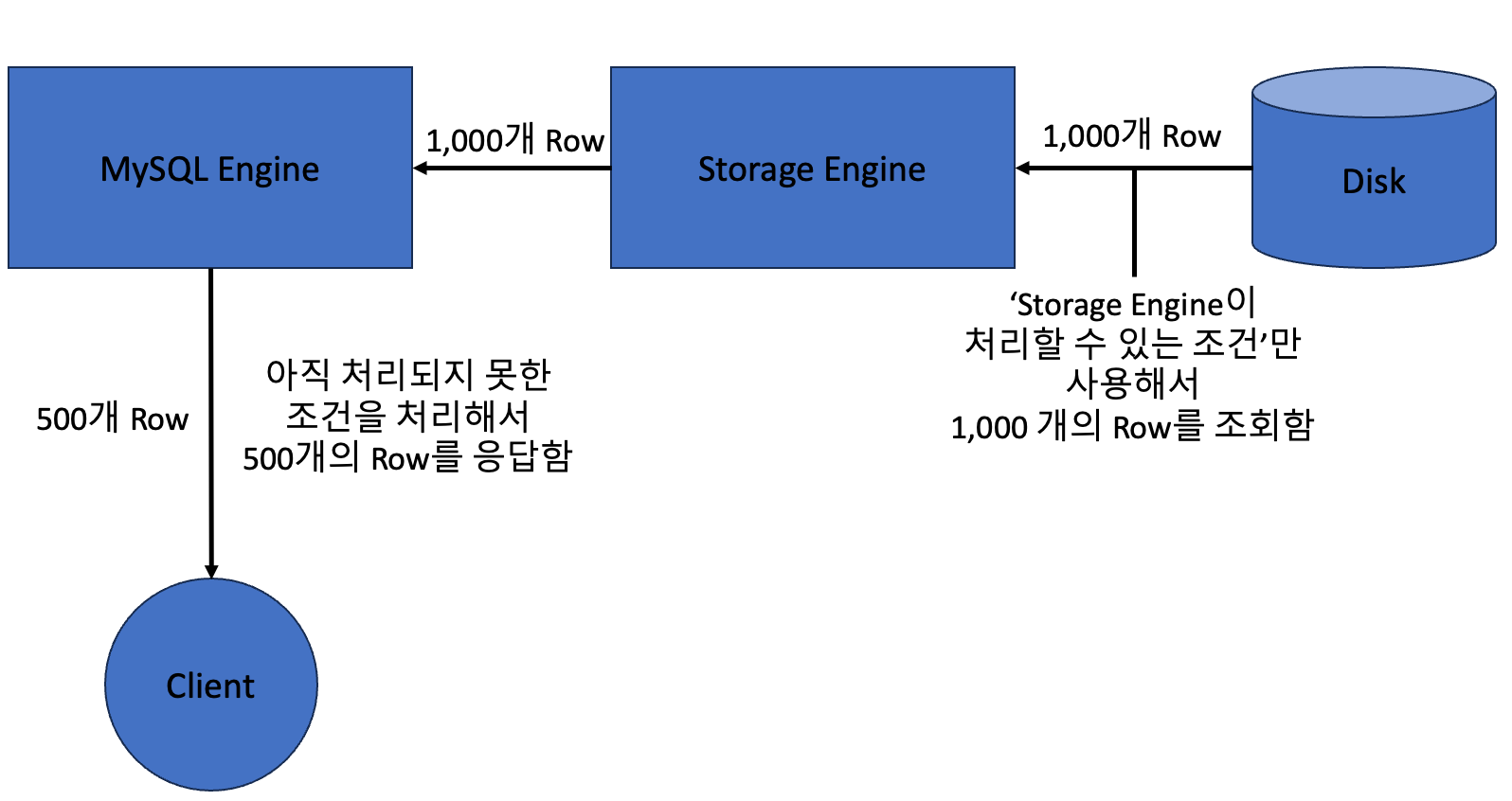
현재로서는 이정도만 알아도둬도, ICP를 이해하는데 어려움은 없을 것입니다.
ICP 없이 조회하는 경우
그럼 본격적으로 ICP에 대해 설명하기 전에, 이것이 어떤 문제를 해결하고자 등장했는지 알아보겠습니다.
현재 MySQL 8버전을 사용하고 계신다면, 모두 기본적으로 ICP를 사용하고 계실텐데요.
먼저 이 기능을 끄도록 하겠습니다.
SET optimizer_switch = 'index_condition_pushdown=off';
그리고 테스트에 사용할 테이블은 아래와 같습니다.
CREATE TABLE `PERSON` (
`ID` int NOT NULL AUTO_INCREMENT,
`NAME` varchar(256) DEFAULT NULL,
`UPDATE_TIMESTAMP` timestamp(6) NULL DEFAULT NULL,
`HEIGHT` int DEFAULT NULL,
PRIMARY KEY (`ID`),
KEY `time_name_index` (`UPDATE_TIMESTAMP`,`NAME`)
);
인덱스 time_name_index 를 UPDATE_TIMESTAMP 과 NAME 칼럼으로 생성해두었습니다.
그리고 4000만개의 Row를 저장해두었습니다.
이제 아래와 같은 조회 쿼리의 실행 계획을 살펴보겠습니다.
EXPLAIN SELECT * FROM PERSON
WHERE `UPDATE_TIMESTAMP` >= '2023-05-31 19:48:30'
AND `NAME` LIKE '김철수%'
LIMIT 3;
결과는 아래와 같습니다.

먼저 key 항목을 살펴보면 time_name_index 가 존재하기 때문에, 해당 인덱스를 사용한 것으로 판단할 수 있습니다.
Extra 항목의 Using where 의 의미는 ‘Storage 엔진 에서 완벽하게 Row를 필터링하지 못하여, 추가적으로 MySQL 엔진 에서 한번 더 필터링했다는 것’ 입니다.
즉, 아래 그림과 같습니다.
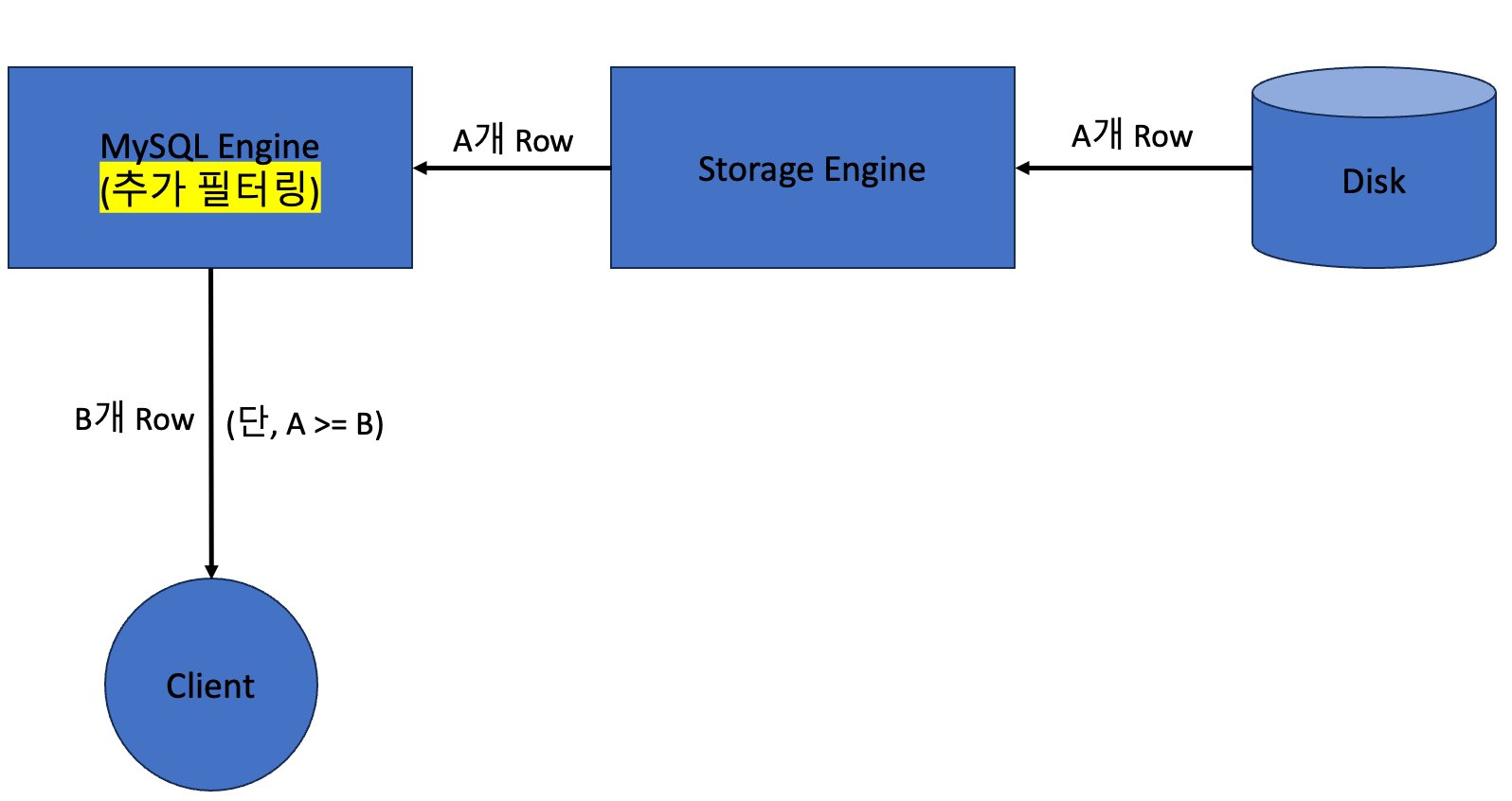
왜 Storage 엔진 에서 완벽하게 필터링을 하지 못했을까요?
그 이유는, LIKE % 는 인덱스를 타지 못하기 때문입니다. 우리가 생성해둔 인덱스 time_name_index 는 조회 쿼리에서 사용한 UPDATE_TIMESTAMP 와 NAME 칼럼으로 구성되어있긴 하지만, NAME LIKE '김철수%' 조건 때문에 NAME 칼럼은 인덱스에서 활용할 수 없습니다.
따라서 Storage 엔진 은 NAME 칼럼 조건에 대한 정보를 MySQL 엔진 으로부터 아예 전달받지 못합니다. (이 부분이 가장 중요한 포인트입니다.)
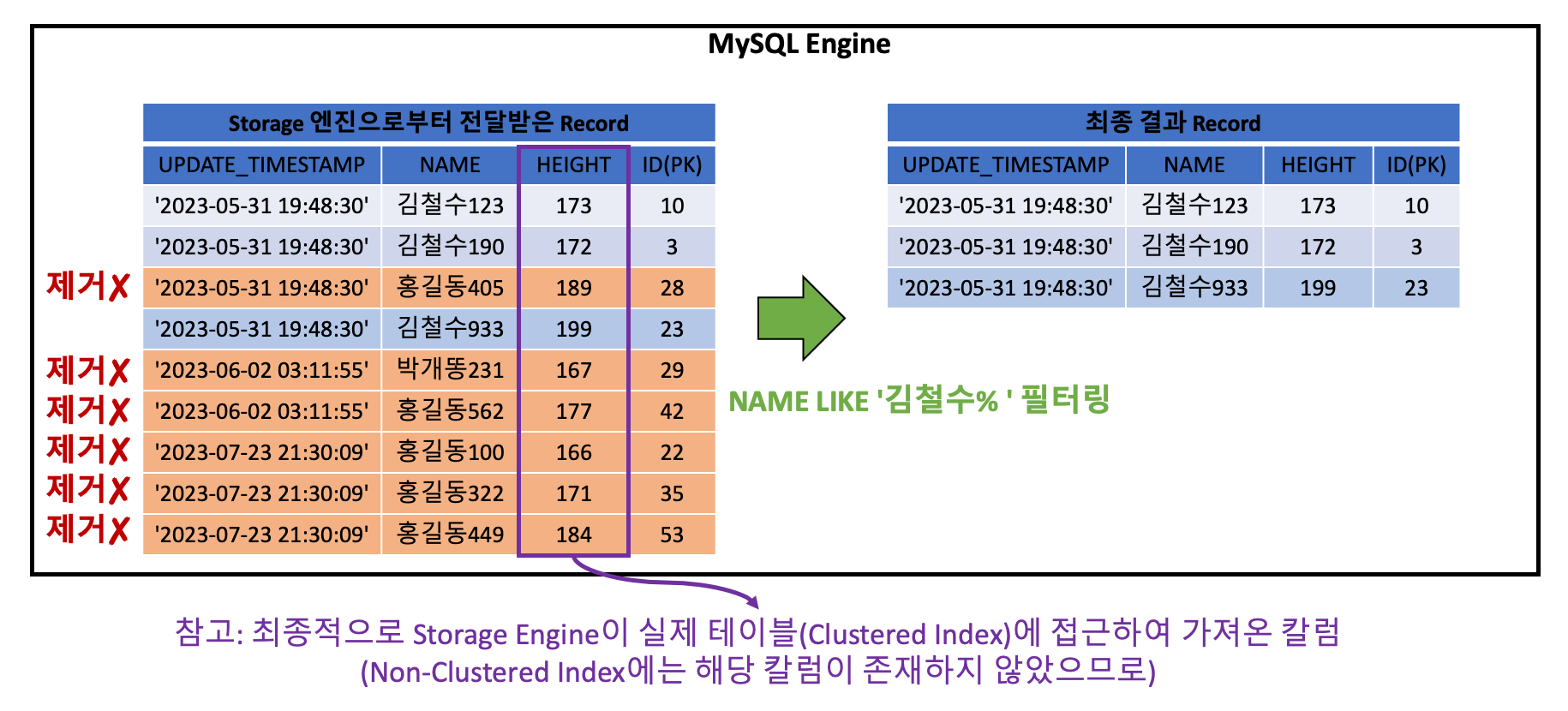
결과적으로 Storage 엔진 이 디스크에서 가져오는 데이터는 아래와 같습니다.
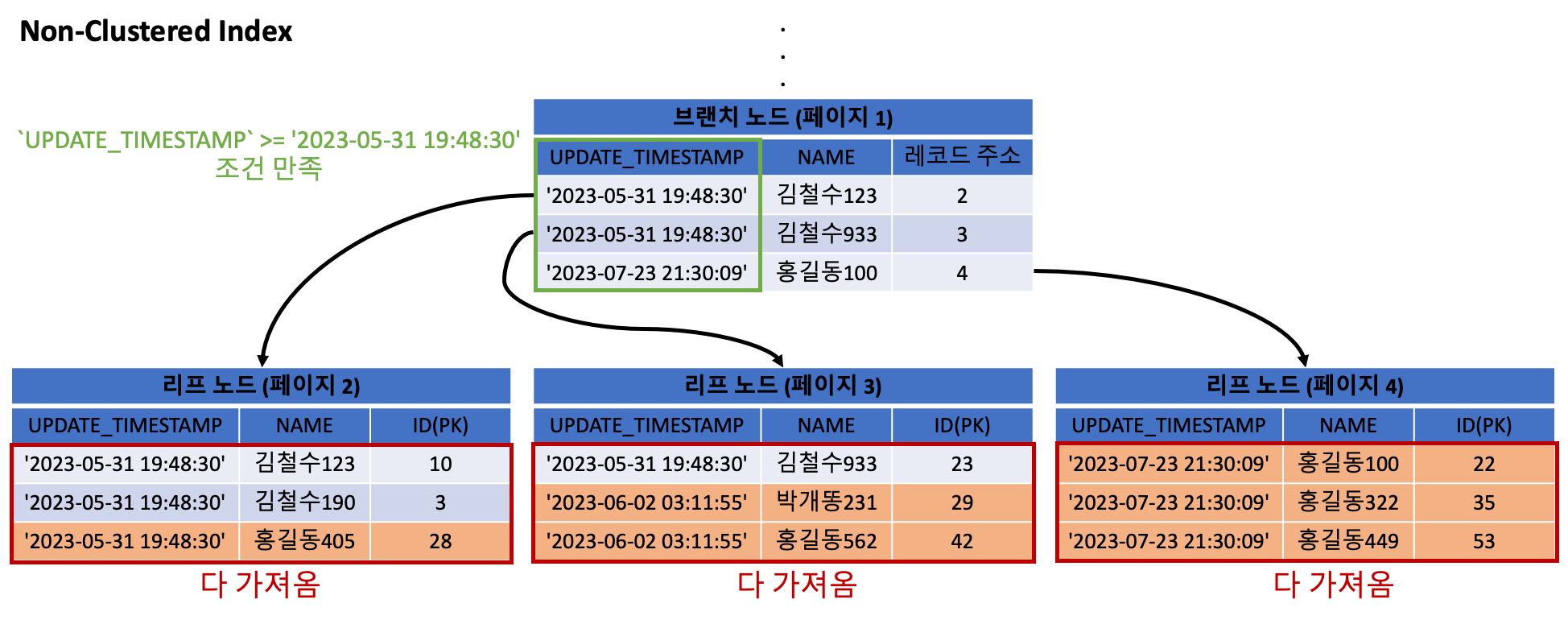
위 그림은 Storage 엔진 이 Non-Clustered Index(time_name_index)를 사용해서 Record를 가져오는 것을 표현한 것입니다.
우리는 두 가지 조건 UPDATE_TIMESTAMP >= '2023-05-31 19:48:30' 와 NAME LIKE '김철수%' 을 사용했습니다.
첫번째 조건은 만족하지만 NAME LIKE '김철수%' 조건은 만족하지 않는 레코드(주황색 영역)까지 MySQL 엔진 으로 가져오게 됩니다.
추가로 설명하면, Non-Clustered Index의 경우 조회된 리프 노드(페이지)에 존재하는 PK 칼럼의 값을 활용해서, 다시 Clustered Index를 조회하게 됩니다. (모든 칼럼에 대한 정보를 가져오기 위해)
그렇기 때문에, 아래와 같이 MySQL 엔진 에서 다시 필터링을 수행해야 원하는 결과를 얻을 수 있습니다.
HEIGHT칼럼은 우리가 만들어둔 인덱스time_name_index에 포함되지 않습니다.
따라서 Non-Clustered Index인time_name_index에서 조회된 Record의 PK값을 통해, 실제 테이블(Clustered Index)에 접근하여 모든 칼럼 값을 가져와야 합니다.
보다 자세한 것은 이전 포스팅인 ‘DB 페이지네이션을 최적화하는 여러 방법들’의 커버링 인덱스 부분를 참고하시면 좋겠습니다.
하지만 이런 방식은 너무 비효율적으로 보입니다. 그 이유는 아래와 같습니다.
- 어차피 사용되지 않고
MySQL 엔진에서 걸러질 Record를Storage 엔진가 굳이 디스크에서 가져와야함. - 필요 이상의 Record를
Storage 엔진이MySQL 엔진에게 전달해야함. - 이를
MySQL 엔진이 다시 필터링 해줘야함.
이 문제는 NAME 칼럼 조건은 인덱스를 타지 못한다는 이유로, MySQL 엔진 이 Storage 엔진 에게 아예 해당 조건 정보를 전달해주지 않아서 발생합니다.
심지어 Storage 엔진 이 사용한 인덱스에 NAME 칼럼에 대한 정보가 존재하는데도 불구하고, NAME 칼럼 조건을 전달받지 못해서 Storage 엔진 이 이를 고려하지 못합니다.
즉, Storage 엔진 이 NAME 칼럼을 확인할 수 있지만(인덱스에 NAME 칼럼이 존재하기 때문에), MySQL 엔진 으로부터 해당 칼럼에 대한 조건 정보를 받지 못해서 조건 검사를 하지 못하게 됩니다.
이를 해결하기 위해서 등장한 것이 바로, ICP(Index Condition Pushdown) 입니다.
ICP(Index Condition Pushdown)
ICP는 MySQL 엔진 이 ‘인덱스 범위 조건에 사용될 수 없어도, 인덱스에 포함된 칼럼’이라면 해당 정보를 Storage 엔진 에 전달함으로써 문제를 해결합니다.
즉, MySQL 엔진 이 ‘인덱스에 포함되었지만 인덱스 탐색에 사용할 수 없는 칼럼의 조건 정보’를 Storage 엔진 에 전달해서, MySQL 엔진 대신 Storage 엔진 이 최대한 필터링을 할 수 있도록 만듭니다.
ICP를 적용하여 얻을 수 있는 효과는 아래와 같습니다.
Storage 엔진이 ‘불필요한 Row(결과에 포함되지 않을 Row)’의 정보를 얻기 위해, 실제 테이블(Clustered Index)에 접근하는 것을 방지- 이를 통해,
Storage 엔진이 디스크에 접근하는 횟수를 줄여 성능 개선 가능
- 이를 통해,
Storage 엔진이 ‘불필요한 Row’를 제거해서MySQL 엔진에 전달하므로, MySQL 내부의 데이터 통신 성능 개선
ICP를 사용하는 경우, 이전에 살펴본 예시 상황을 다시 그림으로 나타내보면 아래와 같습니다.
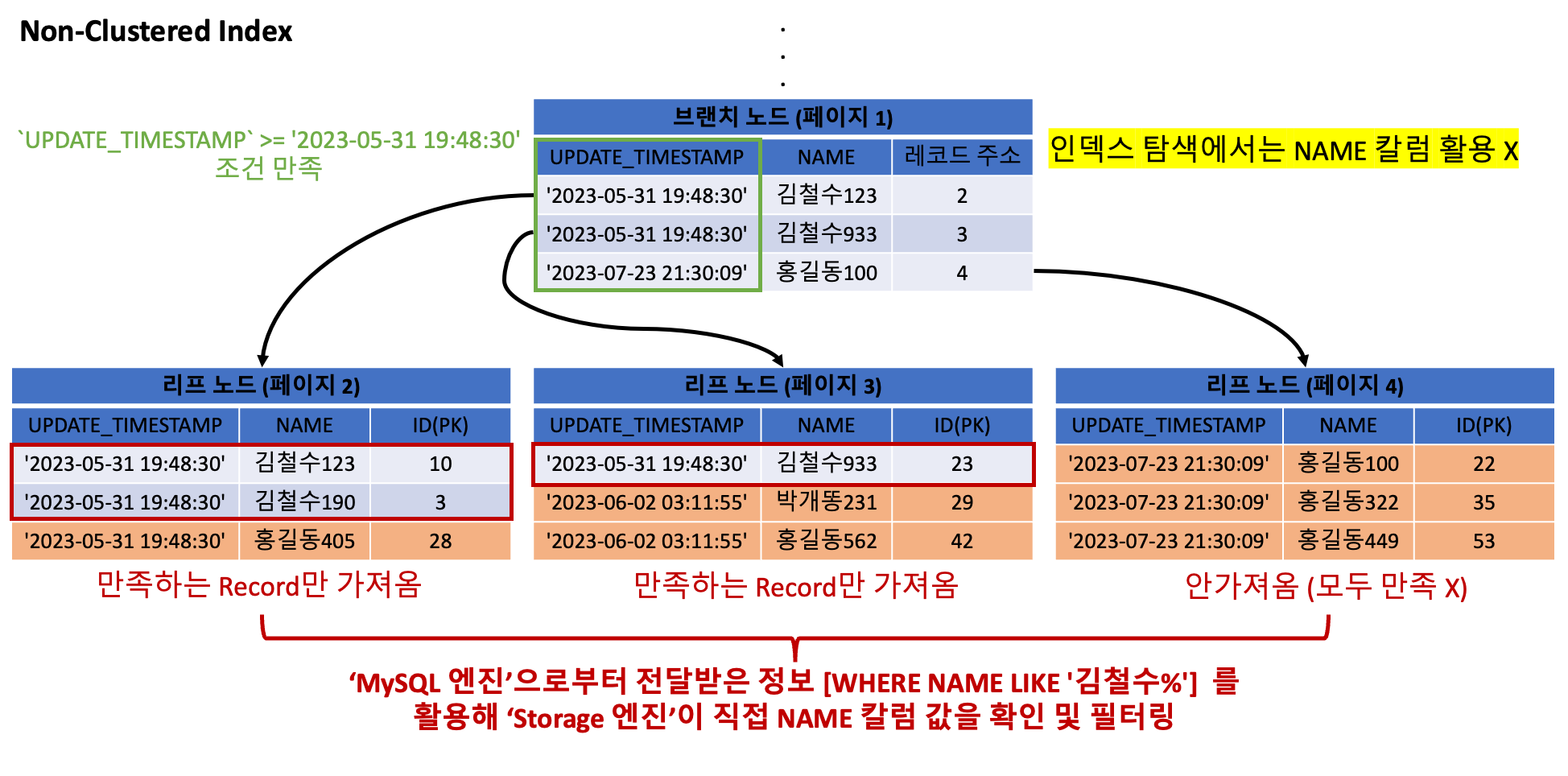
MySQL 엔진 이 인덱스에 포함된 칼럼에 대한 조건 정보 WHERE NAME LIKE '김철수%' 를 Storage 엔진 에 전달합니다.
그리고 Storage 엔진 이 직접 해당 조건을 검사합니다. 이때 중요한 것은 Storage 엔진 이 Non-Clustered 인덱스만을 통해 (실제 테이블 Clustered Index 접근 X) 검사한다는 것입니다. 왜냐하면, 이미 인덱스에 해당 칼럼이 존재하기 때문입니다.
결과적으로 MySQL 엔진 이 전달받는 결과는 아래와 같습니다.
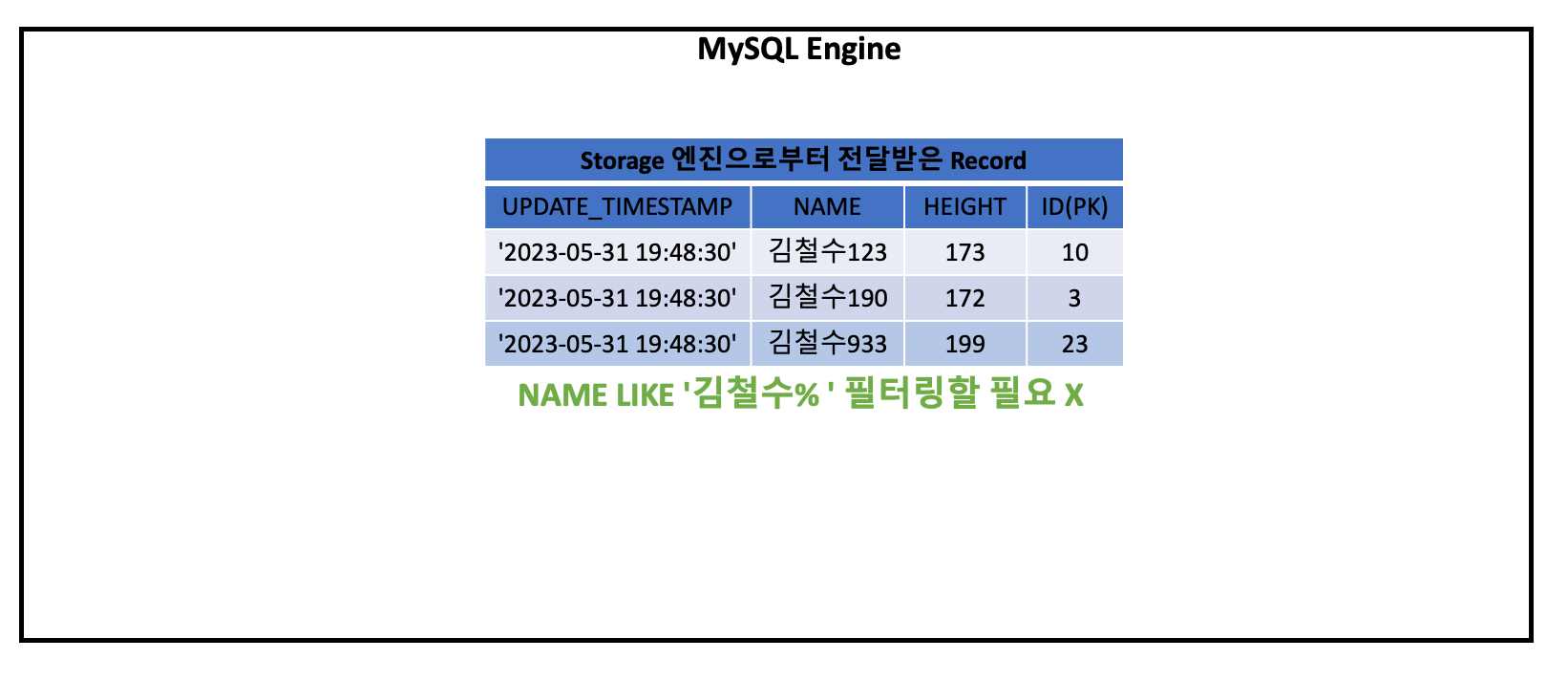
결과 비교
그럼 이번에는 실제로 성능이 개선되는지 확인해보겠습니다.
먼저 ICP를 적용하지 않은 경우를 다시 테스트해볼까요?
ICP가 적용되지 않은 경우
SELECT * FROM PERSON
WHERE `UPDATE_TIMESTAMP` >= '2023-05-31 21:23:43.525335'
AND `NAME` LIKE '홍길동%'
LIMIT 3;
위 쿼리를 실행하면, 아래와 같은 결과를 볼 수 있습니다. (현재 ICP 옵션은 꺼둔 상태입니다. 글 상단 내용을 참고하세요.)
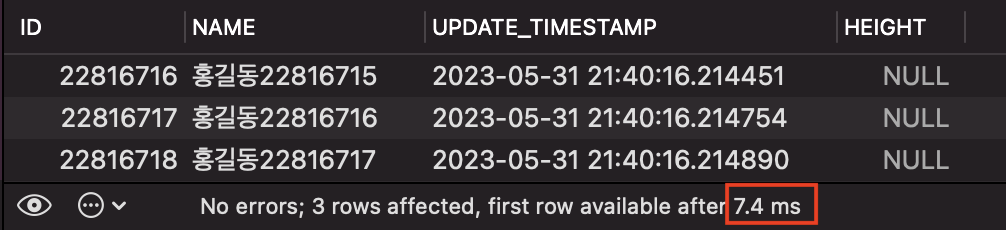
해당 쿼리를 실행하는데 7.4 ms 가 소요되었습니다.
실행 계획을 살펴보면 아래와 같습니다.
이미 글 초반에 살펴본 살펴본 실행 계획과 동일하죠?
key 항목에 인덱스 이름이 존재하기 때문에, 인덱스를 사용하긴 했습니다. 하지만 Extra 항목에서 Using where 이 나왔기 때문에, MySQL 엔진 에서 추가적인 필터링 작업이 수행되었음을 알 수 있습니다.
그럼 이번에는 ICP 옵션을 켜서 동일한 쿼리를 실행해보겠습니다.
ICP가 적용된 경우
SET optimizer_switch = 'index_condition_pushdown=on';
먼저 위 쿼리를 실행해서, ICP 옵션을 켜두겠습니다.
그리고 위와 동일한 쿼리를 실행하겠습니다.
SELECT * FROM PERSON
WHERE `UPDATE_TIMESTAMP` >= '2023-05-31 21:23:43.525335'
AND `NAME` LIKE '홍길동%'
LIMIT 3;
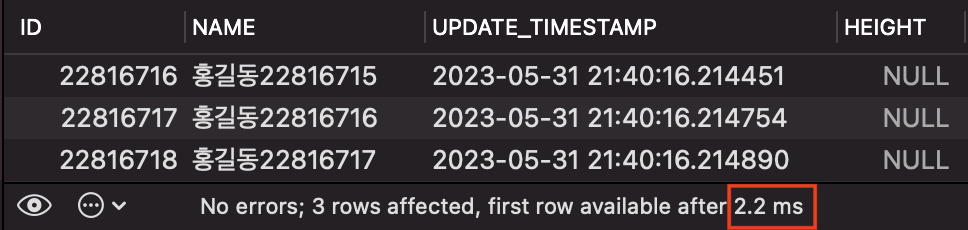
어떤가요? 실행시간이 2.2 ms 로, 기존 7.4 ms 보다 단축된 것을 확인할 수 있습니다.
그럼 실행 계획까지 살펴보겠습니다.

이전과 동일하게 key 값이 time_name_index 로 인덱스를 사용한 것을 알 수 있습니다.
하지만 Extra 는 Using index condition 으로 ICP가 적용되었습니다.
즉, NAME 칼럼에 대한 조건 정보가 Storage 엔진 에 전달되었고, Storage 엔진 이 해당 조건까지 필터링을 했다는 의미입니다.
정리하며…
지금까지 Using index condition 이라는 키워드를 가지고, ICP 라는 최적화 기술에 대해 알아봤습니다.
이번 기회에 MySQL이 내부적으로 어떻게 동작하는지까지 알아볼 수 있었고, 이를 기반으로 ICP까지 학습할 수 있어서 좋았습니다.
이 글을 읽는 여러분께도 도움이 됐길 바라며, 글 마치겠습니다. 혹시나 틀린 내용이 있다면 알려주세요.
감사합니다.